{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Programming Language: Python
- Python Runtime Engine/Version: 3.6.5
Make sure to install the following packages before running
you should be able to install the dependencies via the following commands
python -m pip install --user numpy scipy matplotlib ipython jupyter pandas sympy nose
python Knapsack.py
For the Recursion I crawl through all of the possible options, and if the blocks align it is extremely fast. It checks by adding the item to the first knapsack, then the second, then discards that particular item, and tries the next
The memorizing utilizes the same recursion as the knapsack, but substitutes the
The cache I used was a Dictionary Approach by creating a hash.
I take the 3 inputs n, l1, l2 and concatinate there values into a string, for example with n=4, l1=23, l2=83 the string would be '4_23_83'.
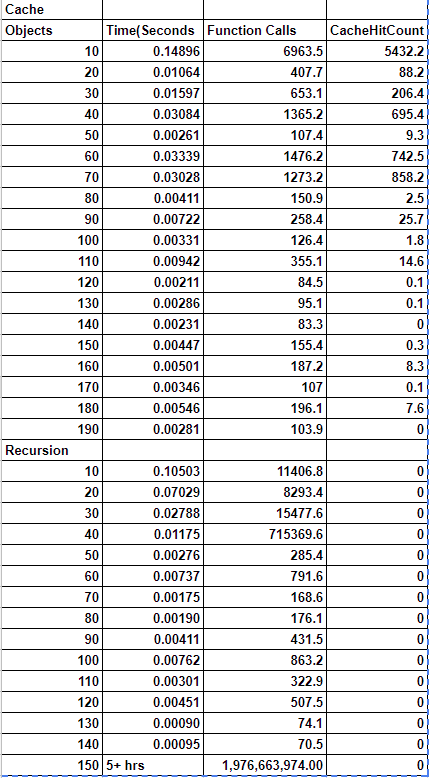
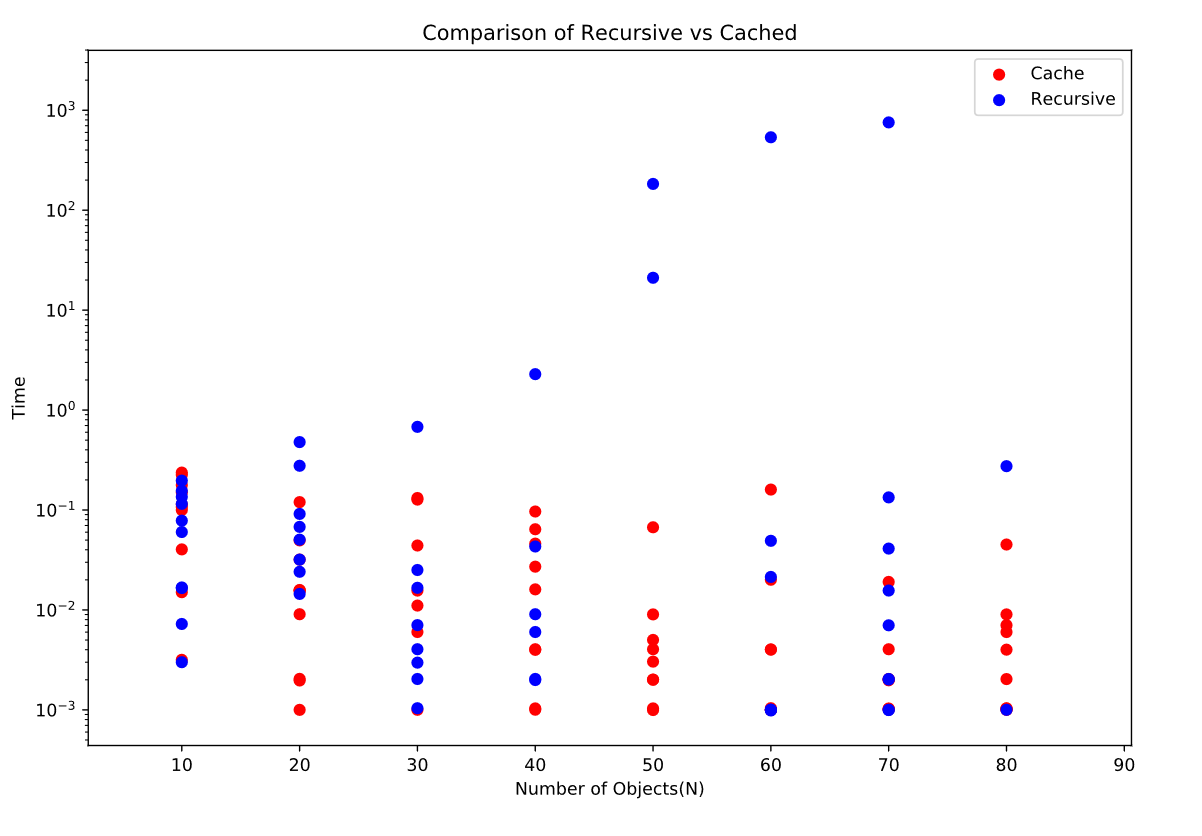
When running the empirical study the caching approach starts out slower, but with more objects, it tends to be faster at finding the solution since it calls on the same parameters so many times.
When running the KnapRecursive() it tends to be fast, but once in a while it will get a set that will cause it to take a very log time.
Generate a table of runtime vs. the number of objects. At what object count does it become infeasible to run the algorithm?
Here is a table with the averages with the time in seconds
- Develop a simple recursive solution to the following Knapsack optimization problem:
- Given: n items each of size s[i] and two knapsacks maximum capacity L1 and L2.
- Find whether there exists a subset of objects that fill both knapsacks exactly. There is no need to determine the objects that make the solution if one exists. An object can either be discarded, placed in the first knapsack or placed into the second knapsack. (This is a very simple extension of the solution that we developed in class. Think about how a problem instance is described: n (how many objects we have), l1 (the size of the first knapsack) and l2 (the size of the second knapsack).
- Implement the solution as a recursive algorithm in the language of your choice. Call this algorithm KnapRecursive()
- Test the code on a few small examples to make sure it is providing the correct answers
- Add a cache to the recursive solution so that each unique solution encountered is only computed once. This technique is called memorizing. Call this procedure KnapMemo(). Recall that to create this algorithm, make the following changes to the recursive algorithm:
- Create a cache data structure Bool cache[n+1, L1+1, L2+1], and a book-keeping array Bool cacheValid[n+1, L1+1, L2+1] (This could be an array, dictionary indexable by the three integers)
- Before the recursive call, check if this solution has been seen before (in cacheValid) if so simply return the solution from the cache.
- Compute the recursive solution, place it in the cache and set cacheValid to true, and return the solution.
- Verify that the two algorithms are running correctly (i.e., all algorithms compute the same answers over a set of randomly created problems). The recursive solution will only be able to solve small problems.
- Perform the following empirical study described below: Create a problem generator that takes n and m and returns a list of n uniformly random integers in the range 1 to m-1 For the recursive algorithm, fix L1 and L2 to be 100 and then run and time the algorithm with increasing object counts, from 10 to 200 by 10. For each object count, repeat 10 times with different random sets of sizes where m is 50. Generate a table of runtime vs. the number of objects. At what object count does it become infeasible to run the algorithm? Create a graph where the x axis is the number of objects and the y axis is the runtime. Important: this graph must be a linear (x) vs. log(y) graph. Look them up if you are unfamiliar. Repeat the same experiment with memoizing solution knapMemo(). How much faster is the memoizing method? Experiment with much larger problem sizes (L1, L2, n and also m). What variable values cause the memoizing algorithm to slow down and why? Write a brief writeup (about 10 sentences) explaining the behavior of the algorithms derived from the graphs. The 30 points will be awarded as follows: 15 points fully working program that correctly implements the two algorithms; 5 points for the empirical studies; 5 points for the correct graphs; 5 points for a correct technical explanation of the behavior.
Submit your graph and report your commented code along with instructions to run the code.