我们把以下内容开源在了国内阿里云社区。阿里云作为Datawhale开源支持方,将提供免配置运行环境和免费算力支持。
逻辑回归(Logistic regression,简称LR)虽然其中带有"回归"两个字,但逻辑回归其实是一个分类模型,并且广泛应用于各个领域之中。虽然现在深度学习相对于这些传统方法更为火热,但实则这些传统方法由于其独特的优势依然广泛应用于各个领域中。而对于逻辑回归而言,最为突出的两点就是其模型简单和模型的可解释性强。
支持向量机(Support Vector Machine,SVM)是一个非常优雅的算法,具有非常完善的数学理论,常用于数据分类,也可以用于数据的回归预测中,由于其优美的理论保证和利用核函数对于线性不可分问题的处理技巧, 在上世纪90年代左右,SVM曾红极一时。 本文将不涉及非常严格和复杂的理论知识,力求于通过直觉来感受 SVM。
决策树是一种常见的分类模型,在金融分控、医疗辅助诊断等诸多行业具有较为广泛的应用。决策树的核心思想是基于树结构对数据进行划分,这种思想是人类处理问题时的本能方法。例如在婚恋市场中,女方通常会先看男方是否有房产,如果有房产再看是否有车产,如果有车产再看是否有稳定工作……最后得出是否要深入了解的判断。
kNN(k-nearest neighbors),中文翻译K近邻。我们常常听到一个故事如果要了解U的经济水平,只需要知道他最好的5个朋友的经济能力,对他的这五个人的经济水平求平均就是这个人的经济水平。这句话里面就包含着kNN的算法思想。
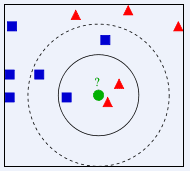
示例 :如上图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
LightGBM是2017年由微软推出的可扩展机器学习系统,是微软旗下DMKT的一个开源项目,由2014年首届阿里巴巴大数据竞赛获胜者之一柯国霖老师带领开发。它是一款基于GBDT(梯度提升决策树)算法的分布式梯度提升框架,为了满足缩短模型计算时间的需求,LightGBM的设计思路主要集中在减小数据对内存与计算性能的使用,以及减少多机器并行计算时的通讯代价。
LightGBM可以看作是XGBoost的升级豪华版,在获得与XGBoost近似精度的同时,又提供了更快的训练速度与更少的内存消耗。正如其名字中的Light所蕴含的那样,LightGBM在大规模数据集上跑起来更加优雅轻盈,一经推出便成为各种数据竞赛中刷榜夺冠的神兵利器。
线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用。LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。即:将数据投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近方法。