说到 OpenGL 就离不开 SGI(美国硅图公司)这家公司,OpenGL 起源于 SGI,在 1992 年 7 月发布 OpenGL 1.0 版后成为工业标准。由成立于 1992 年的独立财团 OpenGL Architecture Review Board (ARB)控制。SGI 等 ARB 成员以投票方式产生标准,并制成规范文档(Specification)公布,各软硬件厂商据此开发自己系统上的实现。只有通过了 ARB 规范全部测试的实现才能称为 OpenGL 规范。
SGI 是一家以高性能计算、数据管理和虚拟化产品的主要制造商。上世纪90年代,硅图制造的高端微型计算机“工作站”被用来为《侏罗纪公园》等好莱坞大片设计电脑特技,该公司一度成为硅谷的明星企业之一,其 1995 年的纯收入达 2.25 亿美元。
SGI 创始人吉姆·克拉克(James Clark)博士出生于美国德州乡村小镇,中学辍学参军,靠自学获得中学同等学历。服完兵役的克拉克考进犹他大学专攻电脑制图,1978 年获博士学位。四年后,他以自己研制的图形工作站和三维绘图软件创办 SGI,然后快速成长为世界著名的图形软硬件制造商。
Silicon Graphics, Inc. (SGI) was a computing manufacturer that produced high-performance computer hardware and software from 1981 through 2009. SGI’s collaboration with game studio Rare and their work on Steven Spielberg's Jurassic Park cements them within the 1990’s computing zeitgeist.
Dr. James H. Clark left his position as an electrical engineering associate professor at Stanford University to found SGI in 1982 along with a group of seven graduate students and research staff from Stanford: Kurt Akeley, David J. Brown, Tom Davis, Rocky Rhodes, Marc Hannah, Herb Kuta, and Mark Grossman; Abbey Silverstone - a former manufacturing executive at Xerox; and a few others. The Mayfield Fund venture capital group supplied the initial funding.
SGI machines were known for their processing power, yet their workstations were not produced for the personal consumer market. The primary barrier to entry was their exorbitant price tag. Yet, even if one could afford to purchase a SGI workstation IRIX, the proprietary Unix-based operating system was optimized for 3D visualization and high performance computing environments. This meant that SGI systems often lacked of support for popular software of the time, including video games.
1995 年并购著名的动画软件公司 Alias Wavefront(2004年售出),从而拥有了属于自己的软件。
SGI 发展史上最重大的事件:
- 1983年,第一批图形终端推出;
- 1984年,第一批图形工作站推出,由此可以看出,它对图形工作站的贡献有多么巨大。
大家所熟悉的「侏罗纪公园」、「指环王」、「紧急迫降」等影片均是在 SGI 的图形工作站上制作出来的。
然而好景不长,随着竞争对手推出成本更低的技术和产品,硅图公司开始走下坡路。
2009 年 SGI 被 Rackable Systems 收购,改名为 SGI 硅图国际。2016 年 11 月 1 日,Hewlett Packard Enterprise 以 2.75 亿美金收购 Silicon Graphics International Corp.,SGI 正式从股票市场退市。
2006 年 08 月 10 日,Khronos 集团宣布获得 OpenGL 的控制权。经过扩张,Apple、Dell、Google 和 S3 Graphics 等公司都已成为了其会员。
科纳斯组织(Khronos Group)是一个由成员资助,专注于制定开放标准(Open standard)的行业协会,重点制定免费的 API,使在各种平台和设备上创作或播放的多媒体可以得到硬件加速。
在 OpenGL 结构评审委员会通过了 OpenGL API 标准的转手之后,Khronos 集团成立了一个 OpenGL 工作组来控制并发展开放式 3D 图形标准,以实现跨平台操作。
Khronos 将能够结合 OpenGL 来开发 OpenGL API 相关软件设计套件和文件。OpenGL 规范的转让将在 2006 年第三季度完成。
为了确保 OpenGL、OpenGL ES、OpenML、COLLADA 和 OpenGL SC 等标准之间的一致性,OpenGL ARB 和 Khronos 集团的合作在之前就已经开始了。
OpenGL 规范转让完成后,所有与 OpenGL 有关活动都必须在 Khronos 参加的情况下完成,从而实现 3D 制图功能应用到包括从超级计算机到手机的所有硬件平台和操作系统。
Khronos 集团总裁兼 Nvidia 公司嵌入式产品副总裁 Neil Trevett 说:“Khronos 在行业内的广泛参与,将使其有效地利用现有和将来的媒体平台之间的配合,并为两者创造新的市场商机。”
目前,OpenGL Graphic API 还在进化之中,但是出于性能与构架优化,以及 Metal、DirectX 等对手竞争需要,新的接棒者 Vulkan GPU API 已经开始普及应用。这个新的规范将开放更多的 GPU 能力给开发者,一方面硬件性能可以得到最大化的发掘,但另一方面,对开发者的技术要求也提升几个级别。
- OpenGL Wiki
- Computer Graphics: Principles and Practice 3rd Edition 2014
- Fundamentals of Computer Graphics 4/5th Edition
- OpenGL SuperBible: comprehensive tutorial and reference OpenGL 4.3 6th Edition
- OpenGL SuperBible: comprehensive tutorial and reference OpenGL 4.5 7th Edition
- OpenGL Programming Guide: The Official Guide to Learning OpenGL 4.3 8th Edition
- OpenGL Programming Guide: The Official Guide to Learning OpenGL 4.5 with SPIR-V 9th Edition
- GLSL Essentials: Enrich your 3D scenes with the power of GLSL! by Jacobo Rodríguez
- GAMES101: 现代计算机图形学入门
- GAMES101-现代计算机图形学入门-闫令琪
- GAMES101 课程录像
- OpenGL Reference Cards
- Vulkan® API Tutoria
我接触 GPU 渲染管线是从 OpenGL 开始的,而有个金主爸爸的 DirectX 多媒体接口只有一个模糊的认识。在图形接口规范中,确实是非常混乱的一个市场,像是一个军阀混战的年代。Open Graphics Library 整体上还是比较接近图形学的基础概念,选择 OpenGL 的理由很简单:通用跨平台。
如果想要更深入 GPU 的开发,还可以选择更精细的 Vulkan® API,它也 khronos 组织制定的图形接口标准。
Vulkan 虽然给开发者提供了更多的自由度,如果这个开发者本身不自由(非大牛),那用回 OpenGL 也是个不错的选择。原因就在于如果开发者对内存管理机制,对程序运行机制没有十足的理解,那就可能会误用 Vulkan 导致运行效率甚至 OpenGL 运行效率更低,那这样就得不偿失。
毕竟 Vulkan 细杂体现在,要实现图形学的 Hello World 程序绘制三角形绘制需要上千行代码,这对于熟悉 OpenGL 程序的开发人员来讲是不可想象的,甚至比自己用 CPU 实现一套软光栅器更为复杂!同时难度也体现在它的 API 复杂难懂,对于入门图形学的新手来讲并不是太简单。
无论这些 API 规范如何打架,着色器始终就是高效绘图的代名词,通过可编程着色器语言 Shader Language 在 GPU 中执行高效的图形渲染代码。
要了解着色器的功能以及如何有效地使用它们,了解渲染管道的基础知识非常重要。还必须学习如何编写 GLSL 程序,并找到好的教程和示例来学习。可以学习 SFML SDK 附带的着色器示例。
官方提供的 OpenGL Wiki 文档是最佳入门材料,上面有关于 Rendering pipeline,OpenGL Shading Language 的基本介绍。另外,shadertoy 网站也是一个膜拜大神着色器案例的好去处。
三大主流的 Shader 语言是:
- HLSL - Direct3D High Level Shader Language 高级着色语言
- GLSL - OpenGL Shader Language
- CGSL - Nvidia C for Graphic
着色器 Shaders 就是在 GPU 上运行的程序,也就是对 GPU 编程的代码片断,所谓片断是指这种程序一般很小,可能最多就是上几百行代码。出于 OpenGL 的通用性,学习一般使用 GLSL (OpenGL Shading Language) 编写,语法上它和 C/C++ 语言非常相似。
与使用 OpenGL 状态机提供的固定状态和操作集相比,它为程序员提供了对绘图过程的更多控制,并且以更灵活、更简单的方式。借助这一额外的灵活性,着色器可用于创建过于复杂(如果不是不可能的话)的效果,用常规 OpenGL 函数无法描述这些效果:每像素照明、阴影等。现代显卡和新的 OpenGL Core Profile 图形接口已经完全基于着色器,称为固定管道的固定状态和函数集已被弃用,将来可能会被删除。
官方提供 GLSL Validator 工具用来检查着色器的错误,根据文档可以看到对应渲染管线的各种着色器。
GLSL Validator 验证工具基于文件扩展名来应用的特定于阶段的规则:
- .vert for a vertex shader
- .tesc for a tessellation control shader
- .tese for a tessellation evaluation shader
- .geom for a geometry shader
- .frag for a fragment shader
- .comp for a compute shader
- .mesh for a mesh shader
- .task for a task shader
- .rgen for a ray generation shader
- .rint for a ray intersection shader
- .rahit for a ray any hit shader
- .rchit for a ray closest hit shader
- .rmiss for a ray miss shader
- .rcall for a ray callable shader
工具提供了两个可执行程序:
- glslangValidator 着色器编译与规范验证程序,会根据扩展名来应用各个渲染阶段适用的验证规则。
- spirv-remap 中间语言编译器,将 GLSL AST 编译为 SPIR-V intermediate language。
GLSL Validator 是官方发布的开源 GLSL 编译器,命令行编译模式方便了用户直接测试着色器语法,而不必使用 C/C++ 相关依赖库及其编译执行过程,也不需要在主文件编写大量初始化代码。
只需要运行命令,将要进行语法检查的着色器程序传入,即可以看到是不有错误输出:
glslangValidator some.vertOpenGL 4.5 最大变化就是支持 Khronos 自家开发新设计的 SPIR-V,Standard Portable Intermediate Representation,这是一种 GPU 通用计算和图形学的中间语言,最初是为 OpenCL 规范准备的,和下一代图形标准 Vulkan 差不多同时提出,也在不断发展完善。
有两种最基本的着色器类型:顶点着色器和片段(或像素)着色器。顶点着色器针对每个顶点运行,而片段着色器针对每个生成的片段(像素)运行。根据要实现的效果类型,可以提供顶点着色器、片段着色器或两者。
使用 Shader 进行渲染时,需要创建两个基础对象 shader 对象和 program 对象,简要来说,主要包括以下六个步骤:
- 创建一个顶点 shader 对象和一个片段 shader 对象
- 将源码附加到每一个shader对象上
- 编译 shader 对象
- 创建一个 program 对象
- 将编译后的 shader 对象附加到这个 program 对象上
- 链接这个 program 对象,然后执行着色渲染
顶点着色器Vertex Shader对应的是顶点 Vertex,相当于像素的概念,也是现代 GPU 最原始的输入数据,但是 GPU 希望使用它来完成更多的工作。所以,顶点一般由一组属性,除了基本的颜色属性外,还有一个 2D 或 3D 坐标、纹理坐标。
这些顶点会构成最基本的图元 Primitive,所谓图元就是最简单的图形,如点,线,三角形,四边形等等,在各版本 OpenGL 支持的图元类型如下:
| GL2.1 | GL3.3 | GL4.5 | 基本图元类型 |
|---|---|---|---|
| ✓ | ✓ | ✓ | GL_POINTS |
| ✓ | ✓ | ✓ | GL_LINES |
| ✓ | ✓ | ✓ | GL_LINE_STRIP |
| ✓ | ✓ | ✓ | GL_LINE_LOOP |
| ✓ | ✓ | ✓ | GL_TRIANGLES |
| ✓ | ✓ | ✓ | GL_TRIANGLE_STRIP |
| ✓ | ✓ | ✓ | GL_TRIANGLE_FAN |
| ✓ | ✄ | ✄ | GL_QUADS |
| ✓ | ✄ | ✄ | GL_QUAD_STRIP |
| ✓ | ✄ | ✄ | GL_POLYGON |
| - | ✓ | ✓ | GL_LINE_STRIP_ADJACENCY |
| - | ✓ | ✓ | GL_LINES_ADJACENCY |
| - | ✓ | ✓ | GL_TRIANGLE_STRIP_ADJACENCY |
| - | ✓ | ✓ | GL_TRIANGLES_ADJACENCY |
| - | - | ✓ | GL_PATCHES |
在绘制命令发出后,GPU 就会开始渲染管线的工作流程,顶点着色器就被调用以处理输入的顶点数据,它应该是简单的着色器程序,甚至只是做数据的拷贝工作,供后续的着色流程添加更复杂的处理。
OpenGL 绘制命令可以理解为指执行 Draw 动作一系列函数,如 glDrawArrays、glDrawBuffer、glDrawBuffers、glDrawElements、glDrawPixels 等等。
在顶点着色器程序运行之后,会依次进行以下操作:
Tessellation Shaders细分着色器,根据设置的细分等级不同,可能加大渲染工作量,也可能降低渲染工作量。基本图元细分为更多的基本图形,创建出更加平滑的视觉效果。或者设置更低的细分,减少细节,降低渲染工作量。Geometry Shader,几何着色器可以在图元的基础上再构建生成其它图元,比如利用四个点可以构造出多个三角形,而且每个输入的图元只会执行一次几何着色器。所以,在最坏的情况下,就是输入的图元全是点,这样几何着色器和顶点着色器执行次数一样。Geometry Shader几何着色器,输入基本图元形式的顶点的集合,通过产生新顶点构造出新的基本图元来生成其他形状。Primitive Assembly基本图元装配,把所有输入的顶点数据作为输入,输出制定的基本图元,为光栅化作准备。Rasterization光栅化即像素化,把细分着色器输出的基本图形映射为屏幕上网格的像素点,生成供片段着色器处理的片段,光栅化包含一个剪裁操作,会舍弃超出定义的视窗之外的像素,来提升执行效率。Fragment Shader片段着色器,主要作用是计算出每一个像素点最终的颜色,通常片段着色器会包含 3D 场景的一些额外的数据,如光线,阴影等。在这个阶段里会使用深度测试,通常也称作 Z-Buffering,和模板测试 Stencil Test 来决定一个片元是否是可见的。如果一个片元成功地通过了所有激活的测试,那么它就可以被直接绘制到帧缓存中了,更新它对应的像素的颜色值,也可能包括深度值。如果开启了 blending 融合模式,那么片元的颜色会与该像素当前的颜色相叠加,形成一个新的颜色值并写入帧缓存中。
根据 OpenGL 文档,详细的渲染管线工序如下:
- Vertex Specification
- Vertex Rendering
- Primitive
- Vertex Processing
- Vertex Shader
- Tessellation
- Geometry Shader
- Vertex Post-Processing
- Transform Feedback
- Clipping
- Primitive Assembly
- Face Culling
- Rasterization
- Fragment Shader
- Per-Sample Processing
- Scissor Test
- Stencil Test
- Depth Test
- Blending
- Logical Operation
- Write Mask
片段着色器阶段也基本就是渲染管线的最后流程,经过最后的处理就得到了屏幕上输出的图形。
Mastering SFML game development by Pupius, Raimondas 书中提供了一张 Programmable pipeline 示意图,很简明地表达了渲染管线各个工序的作用:

以下是根据 OpenGL Programming Guide 第 9 版本制作的 GPU 渲染流程图:
+========+ +========+ +==============+ +==============+
| Vertex | | Vertex | | Tessellation | | Tessellation |
| Data | -> | Shader | -> | Control | -> | Evaluation |
+========+ +========+ | Shader | | Shader |
+==============+ +==============+
+==========+ |
| Culling | +===========+ +==========+ |
| and | | Primitive | | Geometry | |
| Clipping | <- | Setup | <- | Shader | <--------+
+==========+ +===========+ +==========+
|
V +=============+
+===============+ +==========+ | █▀▀░█░█░▀█▀ |
| Rasterization | -> | Fragment | -> | █▀▀░▄▀▄░░█░ |
+===============+ | Shader | | ▀▀▀░▀░▀░░▀░ |
+==========+ +=============+
Figure 1.2 OpenGL pipeline这里,有几个关键的阶段,但只有顶点着色器和片段着色器是必需外部提供的:
- ✒ 从顶点数据输入到 Geometry Shader 几何着色器为止,这部分是整个渲染流程的前端部分。
- ✒ 其次,是固定功能部分,Primitive Assembly, Clipping, Rasterization 等阶段就是将代表场景的图元转化为像素,会应用 Viewport Transformation 这类操作以将虚拟 3D 场景映射到 2D 的屏幕空间上。主要是光栅化,几何空间上的顶点通过投射变换,确定了对应屏幕光栅的位置,也就是几何图形空间的点与像素坐标的对应关系确立。
- ✒ 最后,是以 Fragment Shader 为分界的渲染后期阶段,这个阶段最重要的工作就是在将数据发送到帧缓冲区前确定像素的颜色。
其中,中间部分的光栅化流程涉及了非常抽象的概念,光栅化本身表示对顶点之间的像素进行填充或绘制形成线段。在软件模拟的 3D 世界中,所有东西都是用数学去表达的。空间的一个顶点在什么位置,用三维向量表示,移动、旋转后在什么位置,需要进行线性变换,又叫仿射变换。而要将这个数学抽象的 3D 世界转化为屏幕空间对应的 2D 坐标,还需要根据一个观测角度来决定,这相当于有一台隐藏的摄像机在给抽象世界拍照,再将照片显示在屏幕上。
光栅化之后,就在最后的上色阶段,而 Fragment Shader 也就最后控制图像生成的可编程阶段。图像上什么颜色,或者使用什么纹理,或者什么混合模式都在后期进行。
还有游离在渲染管线之外的一个全局性的计算着色器 Compute Shader,它可以对各个阶段的渲染进行调整。
由于 Vertex Shader 是单输入输出机制,即使用将每个像素用一个 GPU 线程来处理,数据通过整条流水线还是存在浪费。另外,虽然 Gemetry Shader 可以实现各种功能,但也因此在设计上的复杂导致效率低下,不能做预先假设来优化性能。2003 年左右发展出来 GPGPU - General Purpose Computing on GPUs,进一步促使 Compute Shader 的产生,这种着色器游离渲染管线之外,可以任意读写。
不管在屏幕上看到的图像有多么立体,本质上它就是 2D 平面图像,是 3D 数学模型经过变换后投射到屏幕上的图像。这个过程很像画家在使用透视原理将眼睛观察到的世界绘画到纸张的过程,早期画家就摸索出使用格子参考的方式将观察到的画面对应投射到画布上,而 3D 图像技术也使用同样的原理。
这里涉及以下这些基本图形学概念:
- Model Matrix 模型矩阵:通过对物体进行位移、缩放、旋转来改变物体在世界空间中的位置、大小和朝向。
- View Matrix 观察矩阵:由一系列的位移和旋转的组合来完成,平移/旋转场景从而使得特定的对象被变换到摄像机的前方。
- Projection Matrix 投影矩阵:定义一个观察箱 Viewing Box 来限定可视物体的空间范围,也称为平截头体 Frustum,范围内的坐标都会最终出现在用户的屏幕上。将抽象 3D 空间坐标转化为对应的 2D 光栅坐标被称之为投影Projection。
- Orthographic Projection Matrix 正射投影矩阵方式定义了一个类似立方体的平截头体,可以将远处的物体与近处的物体以同样的方式投射而不会产生远近不同的差别(w 分量没有被改变)。
- Perspective Projection Matrix 透视投影矩阵 则是符合实际生活的投身方式,离你越远的东西看起来更小,这个效果称之为透视。
- Viewport Transform 视口变换:最后将裁剪坐标变换为屏幕坐标,这个过程叫视口变换。视口变换将位于 -1.0 到 1.0 范围的坐标变换到由 glViewport 函数所定义的坐标范围内,最后变换出来的坐标将会送到光栅器,将其转化为片段。
顶点变换可能涉及五个不同的坐标系统:
- Local Space 局部空间;
- World Space 世界空间;
- View Space 观察空间;
- Clip Space 裁剪空间;
- Screen Space 屏幕空间;
Perspective Projection vs. orthographic Projection:

OpenGL 使用的坐标是笛卡尔坐标系统,即屏幕向右、向上分别为 X、Y 轴正方向 ,顶点的值直接反映在屏幕。
始终需要明确的一点是 OpenGL 世界坐标系是右手坐标系 right-hand system ,在二维屏幕上,屏幕水平方向是 X 轴方向,向右为正,屏幕竖起方向是 Y 轴方向,向上为正,垂直于屏幕的方向是 Z 轴方向,从屏幕里往外为正。即右手中指向自己表示 Z 轴、食指竖起向上表示 Y 轴、母指向右表示 X 轴。即使手腕怎么转动,右手系统这种轴向关系是主要的参考。
- OpenGL 使用右手系,默认窗体中心为原点,左下角为负,右上角为正;
- 屏幕鼠标的 2D 坐标左上角为原点,右正角为正;
当然,可以通过透视变换来改变屏幕的图像。
仿射变换(Affine Transformation)和齐次坐标系(Homogeneous Coordinate)是计算机图形学中经常碰到的基本概念,在闫令琪的 Game101 现代计算机图形学入门网络公开课上十分简明地讲解这些图形学理论基础。
GPU 图形渲染管线非常复杂,它包含很多可配置的部分。但对于大多数场合,只需要配置顶点着色器、片段着色器。其它是可选的,通常可以使用默认着色器。
GPU 中没有默认的顶点着色器和片段着色器,不可能随意给出某些顶点,然后涂上点颜色就渲染展示出来,所以必须至少定义一个顶点着色器和一个片段着色器。对于初始学者,这确实是有点难,因为即使是渲染一个简单的三角形,也必需学习一堆关于 GPU 渲染管线的知识。另一个难点是,它结合了线性代数基础原理,又结合了图形美学,所以这就是一个技术美术的工作。
在整个渲染流水线中,以下是一些 GPU 图形编程涉及顶点数据及其使用方式的基础概念:
-
VBO- Vertex Buffer object 在显卡存储空间中开辟出的一块内存缓存区用来储存顶点数据,增加顶点进入 GPU 效率的方法。它们可以存储在显存中的缓冲区,以最快的 GPU 速度去访问数据。 -
VAO- Vertex Array Object 顶点数组对象,定义了批量的顶点,和着色器变量起连接作用。VBO 保存了一个模型的顶点属性信息,每次绘制模型之前需要绑定顶点的所有信息,当数据量很大时,重复这样的动作变得非常麻烦。VAO 可以把这些所有的配置都存储在一个对象中,每次绘制模型时,只需要绑定这个 VAO 对象就可以了。 缓存顶点的方式,比起零散的顶点传输效率要高。 -
EBO- Element Buffer Object 索引缓冲对象,或者称IBO- Index Buffer Object,相当于 OpenGL 中的顶点数组的概念。通过顶点索引来解决顶点重用问题,可以减少内存空间浪费,提高执行效率。当需要使用重复的顶点时,通过顶点的位置索引来调用顶点,而不是对重复的顶点信息重复记录,重复调用。
在没有 VBO 的图形绘制,如 glDrawArrays 都是从本地内存推送顶点数据到给 OpenGL 核心,这样中间就会间隔着频繁的 CPU -> GPU 数据对拷操作,增大开销,从而降低效率。
使用 VBO 可以直接将顶点数据缓存到 GPU 开辟的一段内存中,直接从显存中获取而不必再走一遍主机内存,这样就能提升绘制的效率。VAO 就是组织批量的 VBO 数据,则 EBO 就是通过索引来使用顶点数据提高数据复用效率。
在 OpenGL 4.6 Core Profile 规范手册的封面上,完整地描绘了数据的流向。还有官方的 OpenGL API Reference Card 文档也有详细的 OpenGL Pipeline 流程图。

- https://www.khronos.org/opengl/wiki/History_of_OpenGL
- https://www.khronos.org/opengl/wiki/Shader_Compilation
- https://www.khronos.org/opengl/wiki/Core_And_Compatibility_in_Contexts
- https://www.khronos.org/opengl/wiki/OpenGL_Extension
- https://www.khronos.org/registry/OpenGL/extensions/EXT/
- https://www.khronos.org/opengl/wiki/Debug_Output
- https://www.khronos.org/opengl/wiki/OpenGL_Error
- OpenGL Insights OpenGL, OpenGL ES, and WebGL Community Experiences by Patrick Cozzi Christophe Riccio
- OpenGL Insights Source Code https://github.com/OpenGLInsights/OpenGLInsightsCode
- OpenGL and Vulkan https://geek-docs.com/vulkan/vulkan-tutorial/vulkan-and-opengl.html
- FreeGLUT HelloWorld https://github.com/jimboyeah/spine-sfml-demo/blob/master/examples/opengl.cpp
- Anton's OpenGL 4 Tutorials https://antongerdelan.net/opengl/
在早期,OpenGL 和 GLSL 的版本发行并不一致,直到 OpenGL 2.0 开始,才对应发行一个版本号。但版本号并不总是一致,直到 OpenGL 3.3 开始才一致。根据对应关系经 GLSL 1.1 对应的是 OpenGL 2.0,GLSL 1.5 对应 OpenGL 3.2:
OpenGL 历史版本更新:
| 时间 | 版本 | GLSL | 主要特性增加 |
|---|---|---|---|
| 1992/01 | OpenGL 1.0 | - | |
| 1997/01 | OpenGL 1.1 | - | Vertex arrays |
| 1998/03/16 | OpenGL 1.2 | - | Imaging subset (optional) |
| 1998/10/14 | OpenGL 1.2.1 | - | Define ARB extensions concept |
| 2001/08/14 | OpenGL 1.3 | - | Compressed texture format |
| 2002/07/24 | OpenGL 1.4 | - | Automatic mipmap generation |
| 2003/07/29 | OpenGL 1.5 | - | Buffer object |
| 2004/09/07 | OpenGL 2.0 | 1.10 | OpenGL Shading Language 1.00 |
| 2006/07/02 | OpenGL 2.1 | 1.20 | |
| 2008/08/11 | OpenGL 3.0 | 1.30 | Deprecation Model |
| 2009/03/24 | OpenGL 3.1 | 1.40 | |
| 2009/08/03 | OpenGL 3.2 | 1.50 | Geometry shaders, in/out interface block |
| 2010/03/11 | OpenGL 3.3 | 3.30 | |
| 2010/03/11 | OpenGL 4.0 | 4.00 | Tessellation Shader |
| 2010/07/26 | OpenGL 4.1 | 4.10 | |
| 2011/08/08 | OpenGL 4.2 | 4.20 | |
| 2012/08/06 | OpenGL 4.3 | 4.30 | Arbitrary Compute Shaders |
| 2013/07/23 | OpenGL 4.4 | 4.40 | |
| 2014 | OpenGL 4.5 | 4.50 | |
| 2017 | OpenGL 4.6 | 4.60 | The SPIR-V language can be used to define shaders. |
关键的版本有:
- OpenGL 2.0 引入着色器语言,支持顶点着色器、片段着色器;
- OpenGL 3.2 引入几何着色器;
- OpenGL 4.0 引入细分着色器;
- OpenGL 4.3 引入计算着色器;
- OpenGL 4.6 正式引入 SPIR-V 标准可移植中间层语言;
OpenGL 4.5 最大变化就是支持 Khronos 自家开发新设计的 SPIR-V,Standard Portable Intermediate Representation,这是一种 GPU 通用计算和图形学的中间语言,最初是为 OpenCL 规范准备的,和下一代图形标准 Vulkan 差不多同时提出,也在不断发展完善。
着色器就是渲染管线中的可编程阶段执行的 GUP 代码,也就是一个编译单元,互相独立的小段程序。顶点着色器各片段着色器是两个最基本的用户定义的着色器,各个着色器的输入输入是受约束的,片段着色器只能访问当前输入的片段,不可以访问邻近的其它片段。
而相对自由的计算着色器是可以访问其它着色器处理器可使用的资源,包括纹理、缓冲、图像变量、原子计数器等,它没有固定的输出。它不是图形管道的一部分,其副作用是可以更改图像、存储缓冲区和原子计数器。
计算着色器操作一个分组,即执行相同代码的一组着色器调用,可能是并行的。工作组内的调用之间可以通过共享变量共享数据,并发出内存和控制屏障,memory and control barriers,以实现同一工作组的其他成员同步。
OpenGL 与 OpenGL ES/SC 的版本关联:
- OpenGL 1.3 对应 OpenGL ES 1.0 和 OpenGL SC 1.0 • OpenGL 1.5 对应 OpenGL ES 1.1 • OpenGL 2.0 + extra features 对应 OpenGL ES 2.0 • OpenGL 3.x 对应 OpenGL ES 3.0 (Halti) Expected
OpenGL® 作为业界最为广泛使用的 2D/3D 图形库接口标准,应用在成千上万的各式各样的计算机的程序中。从初期的崭露头角,到与 Direct3D 激烈竞争,后经历黯淡被 Khronos 接手又发扬光大,已经历经波折发展了 20年。由于过去的黯淡,至今甚至仍有人站在错误的时间角度认为它是落后的——它从未停止它前进的步伐。
作为强有力的竞争者,DirectX 始终靠着强有力的金主爸爸独霸 Windows 平台,官方自从 Windows 95 时代提供了 OpenGL 1.1 的实现,就再也没有更新过了。就连 1996 年同时代出现的 Opengl Superbible: The Complete Guide to Opengl Programming for Windows Nt and Windows 95 也更新到现 2016 的第七版 OpenGL SuperBible: comprehensive tutorial and reference。
Khronos Group 接手 OpenGL 之后,近几年发展速度迅猛,版本的更新已经到了 OpenGL 4.6,其功能不在 Direct3D 11 之下,且被 Nvidia 和 AMD 主流显卡全面支持。值得注意的是,通用性极好的 OpenGL 在 96.8% 手持设备得到了支持,它们大多都只使用桌面 OpenGL 的子集 OpenGL ES 作为他们的图形编程接口,许多家用游戏机也使用 OpenGL 作为其图形的编程接口。OpenGL 已经重新回到主流的地位!
因为硬件进化趋势的一致性,API 的使用上,OpenGL 也渐渐地和 Direct3D 更加的相似了,在 OpenGL 4.4 的环境下,基本可以“还原”出和 Direct3D 11 一样的接口,从 Direct3D 11 移植到 OpenGL 程序不再是一件难事。
OpenGL 已经不是单一的 API 接口规范,还有移动设备适用的子集 OpenGL ES,和安全敏感行业适用的 OpenGL SC(OpenGL - Safety Critical Profile)开放标准,高安全敏感性的特殊市场包括航空工业,军事,医学和汽车业等等。
从 1992 年 1 月,最早版本的 OpenGL 1.0 由 Mark Segal 和 Kurt Akeley 发布。
OpenGL 最初是作为 Silicon Graphics 工作站专有图形 API - Iris GL 的一种开放的、可复制的替代品创建的。
虽然 OpenGL 最初在某些方面与 Iris GL 相似,但由于缺乏正式的规范和一致性测试,没有在 Iris GL 广泛采用。
Mark Segal 和 Kurt Akeley 编写了 OpenGL 1.0 规范,该规范试图将有用图形 API 的定义形式化,并使跨平台非 SGI 第三方实现和支持变得可行。
但,OpenGL API 1.0 版中一个值得注意的遗漏是纹理对象。Iris GL 对各种对象都有定义和绑定阶段,包括材质、灯光、纹理和纹理环境。OpenGL 避开了这些对象,转而支持增量状态更改,其思想是集体更改可以封装在显示列表中。除了关键部分的纹理对象 glBindTexture 没有明确定义阶段之外,它仍然是一种理念。
OpenGL 经历了一系列功能增量修订,逐渐增加融入核心 API 的扩展 API。
- OpenGL 1.1 在核心 API 中添加了 glBindTexture 扩展,顶点数组替代了立即模式的顶点绘制 API。时隔 5 年更新发布的版本,而另一边 Direct3D 已经上场,尤其是红色警戒游戏大卖。
- OpenGL 2.0 整合了重要新增功能 GLSL 着色语言,这是一种类似 C 语言,可用于 GPU 编程管道的转换和片段着色阶段。
- OpenGL 3.0 增加了“弃用”概念:Deprecation Model,在以后的版本中将某些功能标记为删除状态。
- OpenGL 3.1 基于现有的弃用模型,和后续将要实现的 Core Profile 重大修改,删除了大多数不推荐的功能。
- OpenGL 3.2 创建了两个 OpenGL 上下文概念:Core Profile 和 Compatibility Profile。
着色器语言扩展就是 ARB_shading_language_100,这个 OpenGL 2.0 引入的扩展就是 ARB 认可的扩展。
通过编写 OpenGL 着色器脚本,再经过 OpenGL 编译成 Program Object,也就是相应的二进制指令并上传给 GPU 执行。
OpenGL 4.x 才引入细分着色器和计算着色器的支持,Tessellation shaders and Compute Shaders。
在谈论渲染管线或图形管线时,经常会涉及 GUP 渲染管线和软件的渲染管线模型,有时会混淆不清。不过越来越统一的硬件图形处理流程下,通常它们又是指同样一件事。
2008 年 8 月 11 日发布的 OpenGL 3.0 这个版本代号叫做 Longs Peak,包含了很多大量改变原有工作方式,从根本性改变 API 调用方式的内容。从此开始分 Core Profile 和 Compatibility Profile 两种上下文工作方式,并且 Khronos Group 希望只支持 Core Profile。但这个革新性的规范被许多厂商明确表示拒绝,他们并表示会继续支持许多被划入 Compatibility Profile 的扩展,所以 Compatibility Profile 被改为可选项。
OpenGL 3.0 的出现改变了过去 OpenGL 向后兼容的特性,在一定程度上简化了 API 的臃肿以及增加了 API 的灵活度。
在新版本后,基本文档就有三个了:
- OpenGL 规范文档:GLSLangSpec.3.30.pdf
- GLSL 核心模式规范文档:glspec33.core.pdf
- GLSL 兼容模式规范文档:glspec33.compatibility.pdf
在未来,OpenGL 将会由 Vulkan API 接棒,和 DX12 以及 Metal API 等图形库一较高下。
Vulkan 与 OpenGL 相比,它可以更详细对显卡描述你的应用程序打算做什么,从而可以获得更好的性能和更小的驱动开销。
Vulkan 的设计理念与 Direct3D 12 和 Metal 基本类似,但 Vulkan 作为 OpenGL 的替代者,它设计之初就是为了跨平台实现的,可以同时在 Windows、Linux 和 Android 开发。甚至在 Mac OS 系统上,Khronos 也提供了 Vulkan 的 SDK,虽然这个 SDK 底层其实是使用 MoltenVK 实现的。
关于 OpenGL 的错误处理,在内部有一个错误列表记录,可以枚举出当前发生的所有错误代码:
GLenum err;
while((err = glGetError()) != GL_NO_ERROR)
{
// Process/log the error.
}一个简单的方法是注册一个错误处理回调函数:
void GLAPIENTRY
MessageCallback( GLenum source,
GLenum type,
GLuint id,
GLenum severity,
GLsizei length,
const GLchar* message,
const void* userParam )
{
fprintf( stderr, "GL CALLBACK: %s type = 0x%x, severity = 0x%x, message = %s\n",
( type == GL_DEBUG_TYPE_ERROR ? "** GL ERROR **" : "" ),
type, severity, message );
}
// During init, enable debug output
glEnable ( GL_DEBUG_OUTPUT );
glDebugMessageCallback( MessageCallback, 0 );在 OpenGL Insights 的第一章展示了以下旧风格的 OpenGL 应用程序:
#include <GL/glut.h>
void display(void)
{
glClear(GL_COLOR_BUFFER_BIT);
glBegin(GL_POLYGON);
glVertex2f(-0.5, -0.5);
glVertex2f(-0.5, 0.5);
glVertex2f(0.5, 0.5);
glVertex2f(0.5, -0.5);
glEnd();
glutSwapBuffers();
}
int main(int argc, char **argv)
{
glutInit (&argc, argv);
glutInitDisplayMode(GLUT_RGBA | GLUT_DOUBLE);
glutCreateWindow("Hello World");
glutDisplayFunc(display);
glutMainLoop();
}
// OpenGL Insights Chapter 1: Teaching Computer Graphics Starting with Shader-Based OpenGL
// Listing 1.1. Hello World: Old Style可以通过 git 克隆随书代码:
git clone git@github.com:OpenGLInsights/OpenGLInsightsCode这个示范程序用旧风格的代码画了一个方块,有三个主要的问题:
- 使用即时模式。
- 依赖固定功能管线。
- 使用状态变量的默认值。
在基于着色器的新式渲染管线上,以上使用到的 API 基本都废弃了,除了用于清理画布的 glClear()。理解这些函数为何要移除,是理解为何要使用最新的可编程的 OpenGL 管道的关键。
将渲染管线简化一下,表达这个示范程序的缺点:
Application Fragments Pixels
------------ --------------- ----------
+========+ +========+ +=================+ +============+ +===========+ +========+
| Vertex | | Vertex | | Clipping and | | Rasterizer | -> | Fragment | -> | Frame |
| States | -> | Shader | -> | Primitive Setup | -> | Evaluation | | Shader | | Buffer |
+========+ +===^====+ +=================+ +============+ +=====^=====+ +========+
| |
---------- +--------------------------------------------------------+
CPU GPU Rendering Pipeline
Figure 1.2. Simplified pipeline.作为 OpenGL 早期的基础管道模型,它强调即时模式图形。一旦生成每个顶点,就触发顶点着色器的执行。因为几何处理是由顶点着色器在 GPU 上执行的,所以这个简单的示范程序需要在每次显示矩形时向 GPU 发送四个顶点位置。
基于早期的 OpenGL 渲染管线模型的程序掩盖了 CPU 和 GPU 之间的瓶颈,并隐藏了现代 GPU 上可用的并行性。
其次,尽管能够依靠数量不多的数据直接调用 API 进行绘图,但是这种方式在处理更复杂的几何图形时,应用程序的性能就会形成大问题。
最后,也是最主要的问题是,这种将 OpenGL 作为状态机的程序开发类型有些过时。尽管状态很重要,但使用固定函数管道和默认值隐藏了 OpenGL 中控制几何体渲染方式的大量状态变量。随着简单程序的扩展,开发者往往会迷失在大量的状态变量中,并且很难处理状态变量变化的意外副作用。在 OpenGL 的最新版本中,大多数状态变量都已被弃用,应用程序会创建自己的状态变量。
术语固定函数管道“Fixed Function Pipeline”通常指 OpenGL 旧版本中存在的一组可配置处理状态,这些状态后来被相应的着色器取代。虽然当前的 OpenGL 管道仍然保持不可编程状态,但这通常不是人们所说的“固定功能”。
OpenGL 的目的是向应用程序开发人员公开底层图形硬件的功能,通用的 OpenGL 渲染管道与现代 GPU 硬件大致相同。然而,取代可编程阶段的是内置的数学运算。用户将提供特定的矩阵和其他配置参数。通过这种方式,用户可以让系统做一些有用的事情,但它缺乏完全可配置系统的弹性。
尽管,OpenGL 2.0 已经引入着色器语言,支持可编程的管道,但是它仅仅是个可选项,因为开发者仍然可以访问所有现在不推荐使用的功能。应用程序可以有自己的着色器,也可以使用旧式的即时模式进行绘图。着色器可以访问大多数 OpenGL 状态变量,这简化了使用着色器编写应用程序的过程。并且,在第一个以即时模式和固定函数管道开始的 OpenGL 课程中,很少有讲师真正深入接触到可编程着色器。充其量,着色器在课程结束时会有一个简短的介绍。
OpenGL 3.0 发布时声明,不在 OpenGL 3.1 提供向后兼容,但迫于现状,还是提供了 Compatibility Profile 工作模式。而要使用更先进的 GPU 渲染能力,就要使用 OpenGL 3.1 Core Profile 工作模式,这是基于着色器程序的绘图模式。显然,OpenGL 同时提供这两套工作模式,不仅为自身规范的定制增加了工作量,同时也为从事 OpenGL 的开发者增加了学习难度。
在 OpenGL Insights 的第一章展示的第二个 OpenGL 示范程序是基于可编程管道的,也就是新的 OpenGL 工作模式。顶点着色器和片断着色器是唯一两个必需提供的着色器,其它是可选,代码也简化到只为演示使用。
即使是最简单的应用程序也可以分为三个部分:
- 设置着色器和与窗口系统的接口的初始化;
- 构造数据并将数据发送到 GPU 的阶段;
- 最后在 GPU 上呈现数据的阶段;
在基于着色器的方法中,可以实现一个函数 InitShaders,它读取着色器文件,编译它们,链接它们,如果成功,返回一个程序对象。即使使用 InitShader,第一阶段并不比传统方法更简单。对于旧式的示例,第三阶段只需要清除一些缓冲区和调用 gldrawArray() 绘制给定顶点的图形。
中间阶段从根本上不同于即时模式编程,即使是最简单的程序,也必须引入顶点缓冲区对象和顶点数组对象,即:
- glGenVertexArrays() 在 GPU 专属内存区申请空间以存放一个保存顶点数据的 VAO 对象;
- glGenBuffers() 在 GPU 专属内存区申请空间存放一个 VBO 顶点缓冲区对象。
以下示范程序显示内容与前面旧式的即时绘图方式输出相同,输入顶点数据设置了 6 个顶点坐标,并通过 glDrawArrays() 函数以 GL_TRIANGLES 方式绘制出 2 个三角形。为了简化并突出结构,以下程序代码片断只作为展示使用,将着色器程序内容的读取和初始化设置放到后面。此代码并不完全,在 Github 仓库上有一份修改过的 FreeGLUT HelloWorld 供参考,仅作为显示如何加载 OpenGL 使用。
#include "Angel.h"
void init( void )
{
vec2 points[6] =
{
vec2( -0.5, -0.5 ), vec2( 0.5, -0.5 ),
vec2( 0.5, 0.5 ), vec2( 0.5, 0.5 ),
vec2( -0.5, 0.5 ), vec2( -0.5, -0.5 )
};
GLuint vao, buffer;
GLuint glGenVertexArrays(1, &vao);
glBindVertexArray(vao);
GLuint glGenBuffers(1, &buffer);
glBindBuffer(GL_ARRAY_BUFFER , buffer);
glBufferData(GL_ARRAY_BUFFER , sizeof(points), points, GL_STATIC_DRAW);
GLuint program = InitShader("vsimple.glsl", "fsimple.glsl");
glUseProgram(program);
GLuint loc = glGetAttribLocation(program, "vPosition");
glEnableVertexAttribArray(loc);
glVertexAttribPointer(loc, 2, GL_FLOAT, GL_FALSE, 0, 0);
glClearColor(0.0, 0.0, 0.0, 1.0);
}
void display(void)
{
glClear(GL_COLOR_BUFFER_BIT);
glDrawArrays(GL_TRIANGLES , 0, 6);
gutSwapBuffers();
}
int main(int argc, char **argv)
{
glutInit (&argc, argv);
glutInitDisplayMode(GLUT_RGBA | GLUT_DOUBLE);
glutCreateWindow("Hello World");
init();
glutDisplayFunc(display);
glutMainLoop();
}
// OpenGL Insights Chapter 1: Teaching Computer Graphics Starting with Shader-Based OpenGL
// 1.5 Hello World: New Style
// Listing 1.2. Hello World redux.关于向量类型的定义,可以参考 GLM - OpenGL Mathematics 数学库的实现,OpenGL Insights 随书代码就有用到它,可以在以下章节的代码中找到:
- Chapter 15 Depth of Field with Bokeh Rendering
- Chapter 26 Indexing Multiple Vertex Arrays
顶点着色器会将输入的顶点坐标 a_position 直接拷贝到输出变量。
in vec4 vPosition;
void main()
{
gl_Position = vPosition;
}
// Listing 1.3. Hello World vertex shader.out vec4 FragColor;
void main()
{
FragColor = vec4(1.0, 1.0, 1.0, 1.0);
}
// Listing 1.4. Hello World fragment shader.OpenGL 3.1 开始,像素处理就截然不同。位图和像素写入功能都是预先准备好的,并保留了一些相关的功能,例如使用累积缓冲区的功能。虽然这些功能易于使用,但效率极低。在这种情况下,编程的简单性会导致 GPU 的使用不佳,并且由于 CPU 和 GPU之 间来回传输大量数据而导致瓶颈。
另一种方法是使用片段着色器来操纵纹理,例如,以下这个简单片段着色器足以演示图像平滑处理,对周边 4 个像素进行平均值处理得到连续淡化的平滑效果,并且可以很容易地进行更改以执行其他成像操作。
in vec2 texCoord;
out vec4 FragColor;
uniform float d;
uniform sampler2D image;
void main()
{
FragColor =
( texture( image , vec2(texCoord.x + d, texCoord.y))
+ texture( image , vec2(texCoord.x, texCoord.y + d))
+ texture( image , vec2(texCoord.x - d, texCoord.y))
+ texture( image , vec2(texCoord.x, texCoord.y - d))) / 4.0;
}
// Listing 1.5. Image-smoothing shader.以下是 InitShaders 函数实现参考,它读取着色器文件,编译它们,链接它们,如果成功,返回一个程序对象。
在编写 ReadFile() 这个函数时,我就犯了两错误:
- 参数 out 没使用引用,这导致数据无法返回给函数外部;
- 读取使用的 getline() 这会过滤掉换行符号,这会导致正常着色器代码会被注解掉。
还好,在 main() 函数中使用了 function-try-block 进行处理,否则,发现不了问题所在,调试程序就无从下手。
以下代码演示了如何在 FreeGLUT 加载 OpenGL 扩展 API,只展示了 glDebugMessageCallback(),其它 API 加载可以参考 KHnoros 官方文档提供的头文件。
#include <iostream>
#include <fstream>
#include <string>
#include <sstream>
#include <stdexcept>
#include <GL/gl.h>
#include <GL/glext.h>
#include <GL/freeglut.h>
using namespace std;
/*
* OpenGL 2+ shader mode needs some function and macro definitions,
* avoiding a dependency on additional libraries like GLEW or the
* GL/glext.h header
* Reference:
* https://github.com/KhronosGroup/OpenGL-Registry/tree/main/api/GL/glext.h
*/
#ifndef GLAPIENTRY
#define GLAPIENTRY APIENTRY
#endif
PFNGLDEBUGMESSAGECALLBACKARBPROC glDebugMessageCallback;
void initExtensionEntries(void)
{
glDebugMessageCallback = (PFNGLDEBUGMESSAGECALLBACKARBPROC) glutGetProcAddress ("glDebugMessageCallback");
//...
}
bool ReadFile(string fileName, string &out)
{
string line;
stringstream ss;
ifstream file (fileName, ios::ate); // position at end for size
int size = file.tellg();
file.seekg (0, ios::beg); // position at beginning of content
if (!file.is_open()) return false;
while (getline (file, line))
{
ss << line << endl;
}
file.close();
out = ss.str();
return true;
}
class InitShaderError: public runtime_error
{
public:
InitShaderError(char *str): runtime_error(str) {}
InitShaderError(string str): runtime_error(str) {}
InitShaderError(const InitShaderError &other): runtime_error(other) {}
};
void AddShader(GLuint ShaderProgram, const char* pShaderText, GLenum ShaderType)
{
GLuint ShaderObj = glCreateShader(ShaderType);
if (ShaderObj == 0) {
throw InitShaderError(string("Error creating shader type ") + to_string(ShaderType));
}
const GLchar* p[1];
p[0] = pShaderText;
GLint Lengths[1];
Lengths[0]= strlen(pShaderText);
glShaderSource(ShaderObj, 1, p, Lengths);
glCompileShader(ShaderObj);
GLint success;
glGetShaderiv(ShaderObj, GL_COMPILE_STATUS, &success);
if (!success) {
GLchar InfoLog[1024];
glGetShaderInfoLog(ShaderObj, 1024, NULL, InfoLog);
throw InitShaderError(string("Error compiling shader type ") + to_string(ShaderType) + ": "+ InfoLog);
}
glAttachShader(ShaderProgram, ShaderObj);
}
GLuint InitShader(const char *vsFileName, const char *fsFileName)
{
GLuint ShaderProgram = glCreateProgram();
if (ShaderProgram == 0) {
throw InitShaderError(string("Error creating shader program."));
}
string vs, fs;
if (!ReadFile(vsFileName, vs)) {
throw InitShaderError(string("Faile to read file content: ")+vsFileName);
};
if (!ReadFile(fsFileName, fs)) {
throw InitShaderError(string("Faile to read file content: ")+fsFileName);
};
AddShader(ShaderProgram, vs.c_str(), GL_VERTEX_SHADER);
AddShader(ShaderProgram, fs.c_str(), GL_FRAGMENT_SHADER);
GLint Success = 0;
GLchar ErrorLog[1024] = { 0 };
glLinkProgram(ShaderProgram);
glGetProgramiv(ShaderProgram, GL_LINK_STATUS, &Success);
if (Success == 0) {
glGetProgramInfoLog(ShaderProgram, sizeof(ErrorLog), NULL, ErrorLog);
throw InitShaderError(string("Invalid shader program: ")+ErrorLog);
}
glValidateProgram(ShaderProgram);
glGetProgramiv(ShaderProgram, GL_VALIDATE_STATUS, &Success);
if (!Success) {
glGetProgramInfoLog(ShaderProgram, sizeof(ErrorLog), NULL, ErrorLog);
throw InitShaderError(string("Invalid shader program: ")+ErrorLog);
}
return ShaderProgram;
}
template <typename T>
class Vector2
{
public:
Vector2(){};
Vector2(T X, T Y);
T x; ///< X coordinate of the vector
T y; ///< Y coordinate of the vector
};
template <typename T>
Vector2<T>::Vector2(T X, T Y): x(X), y(Y) {};
typedef Vector2<float> vec2;
void init( void )
{
vec2 points[6] =
{
vec2( -0.5, -0.5 ), vec2( 0.5, -0.5 ),
vec2( 0.5, 0.5 ), vec2( 0.5, 0.5 ),
vec2( -0.5, 0.5 ), vec2( -0.5, -0.5 )
};
GLuint vao, buffer;
glGenVertexArrays(1, &vao);
glBindVertexArray(vao);
glGenBuffers(1, &buffer);
glBindBuffer(GL_ARRAY_BUFFER , buffer);
glBufferData(GL_ARRAY_BUFFER , sizeof(points), points, GL_STATIC_DRAW);
string vert = "../examples/opengl_insights_ch1.vert";
string frag = "../examples/opengl_insights_ch1.frag";
GLuint program = InitShader(vert.c_str(), frag.c_str());
glUseProgram(program);
GLuint loc = glGetAttribLocation(program, "vPosition");
glEnableVertexAttribArray(loc);
glVertexAttribPointer(loc, 2, GL_FLOAT, GL_FALSE, 0, 0);
glClearColor(0.1, 0.1, 0.1, 1.0);
}
void display(void)
{
glClear(GL_COLOR_BUFFER_BIT);
glDrawArrays(GL_TRIANGLES , 0, 6);
glutSwapBuffers();
}
void GLAPIENTRY
MessageCallback( GLenum source, GLenum type, GLuint id, GLenum severity,
GLsizei length, const GLchar* message, const void* userParam )
{
fprintf( stderr, "GL CALLBACK: %s type = 0x%x, severity = 0x%x, message = %s\n",
( type == GL_DEBUG_TYPE_ERROR ? "`GL ERROR`" : "" ), type, severity, message );
}
int main(int argc, char **argv) try
{
glutInit (&argc, argv);
glutInitDisplayMode(GLUT_RGBA | GLUT_DOUBLE);
glutCreateWindow("Hello World");
cout << "GL_SHADING_LANGUAGE_VERSION:" << glGetString(GL_SHADING_LANGUAGE_VERSION) << endl;
cout << "GL_SHADING_LANGUAGE_VERSION_ARB:" << glGetString(GL_SHADING_LANGUAGE_VERSION_ARB) << endl;
// cout << "GL_EXTENSIONS:" << glGetString(GL_EXTENSIONS) << endl;
cout << "GL_RENDERER:" << glGetString(GL_RENDERER) << endl;
cout << "GL_VENDOR:" << glGetString(GL_VENDOR) << endl;
cout << "GL_VERSION:" << glGetString(GL_VERSION) << endl;
initExtensionEntries();
// During init, enable debug output
glEnable ( GL_DEBUG_OUTPUT );
glDebugMessageCallback( MessageCallback, 0 );
init();
cout << "GL_GetError: 0x" << hex << glGetError() << endl;
glutDisplayFunc(display);
glutMainLoop();
}
catch (runtime_error ex)
{
cout << ex.what() << endl;
}程序中加入了信息打印功能,用于查询当前的 OpenGL 版本,以及已有的扩展名字列表。
因为使用了 FreeGLUT,在调用 glGetString() 函数之前,先调用 glutInit() 与 glutCreateWindow() 以初始化 OpenGL 上下文化,非则会返回 null,不能返回正确的值。通过 glGetError() 也可以查询到一个错误号 1282。
#define GL_INVALID_VALUE 0x050在 OpenGL Insights 随书代码中也可以看到在获取 OpenGL 接口信息时这种方法的应用:
GLFWvidmode vidmode;
// Initialise GLFW
glfwInit();
// Open a temporary OpenGL window just to determine the desktop size
if( !glfwOpenWindow(256, 256, 8,8,8,8, 32,0, GLFW_WINDOW) )
{
glfwTerminate(); // glfwOpenWindow failed, quit the program.
return 1;
}
glfwGetDesktopMode(&vidmode);
glfwCloseWindow();
printf("GL vendor: %s\n", glGetString(GL_VENDOR));
printf("GL renderer: %s\n", glGetString(GL_RENDERER));
printf("GL version: %s\n", glGetString(GL_VERSION));
printf("Desktop size: %d x %d pixels\n", vidmode.Width, vidmode.Height);在 SFML 源代码中 GLLoader.hpp 可以找到 OpenGL 相关的符号定义,在 Powershell 可以使用 '{0:X4}' -f 1282 这样的脚本转换为 16 进制显示,也可调用数值对象的转换方法,进行任意进制的转换 [int64][convert]::ToString(1281, 2)。
0 .. 65535 | % { "{0:D16}" -f [int64][convert]::ToString($_,2) }- OpenGL Overview https://www.khronos.org/opengl/
- OpenGL Reference Cards https://www.khronos.org/developers/reference-cards/
OpenGL 开放图形库 “Open Graphics Library”,是图形硬件的软件接口,提供数百个 API 供开发者在绘制高质量图形时指定操作、以及对象,指定三维对象的图像颜色。
OpenGL 规范文档本身并不是整个图形规范的全部,除了最新带修正的文档,至少还应该包含 The OpenGL Shading Language 规范文档。
- glspec46.compatibility.withchanges.pdf
- glspec46.core.withchanges.pdf
- GLSLangSpec.4.60.pdf
从 OpenGL 4.3 版开始,规范经历了重大的重组,文档内容目录有较大改动,以对象模型、事件模型、数据流的方式重新组织,以专注于可编程着色。并在描述图形管道中使用的细节之前,在整个 API 的上下文中描述重要的概念和对象。
新的规范文档已经进行了实质性的重组,以引入高级概念并在使用前先介绍程序中使用到的对象,以及更清晰地划分可编程和固定功能处理的描述。
在不同的操作系统平台上,OpenGL 有着不同的实现,官方提供的文档可以直接克隆下载:
> git clone git@github.com:KhronosGroup/EGL-Registry
> git clone git@github.com:KhronosGroup/OpenGL-Refpages
> git clone git@github.com:KhronosGroup/OpenGL-Registry
> git clone git@github.com:KhronosGroup/GLSL大多数 OpenGL 接口要求图形硬件提供一个帧缓冲区 framebuffer,许多 OpenGL 调用都与点、线、多边形和位图等图形对象有关,但某些图形的绘制方式,例如启用抗锯齿或纹理,取决于现有的帧缓冲区。此外,OpenGL 的一些部分特别关注帧缓冲区操作。
GLX API 是 X Window System 上专用的 OpenGL API,主要是针对 Linux 和 Unix 操作系统,但在 Microsoft Windows, MacOS X 或其它 X 图形系统上也有 GLX 的实现,规范文档在 Khronos EGL Registry。
WGL API 是 OpenGL 在 Windows 系统平台下的封装,相应的文档也在 MSDN 资源库中。
MacOS X Windows 窗口系统,Quartz 中使用的 OpenGL API 有几套,包括 CGL - Core OpenGL、AGL - Apple Graphics Library 和 NSOpenGLView,这些 API 档案都在苹果的开发者网站上。
EGL API 规范也就是 The Khronos Native Platform Graphics Interface,用于移动设备或嵌入式设备的 OpenGL ES 使用的编程接口。
另外,GLU - OpenGL Utility Library 实用程序库提供了一组函数,用于从基础图像创建纹理贴图,在屏幕和对象空间之间映射坐标,以及绘制二次曲面和 NURBS。GLU 1.2 是与 OpenGL 1.1 配套的版本。GLU 1.3 包括与 OpenGL 1.2 新功能相对应的功能。
GLU 与 GLUT 在名称上很相似,但后者的主要功能是提供一个跨平台的窗口适配环境,包括处理用户键盘、鼠标等输入。因为 OpenGL 只提供图形接口规范,而不包括用户输入部分的处理,这是开发者的工作。通过 GLUT 这样的工具,用户直接上手就可以使用 OpenGL 接口开发图形界面应用,而不必与操作系统的窗口图形底层打交道。
按照 C/C++ 的历史,调用 OpenGL 的源代码包含一个单独的头文件,<GL/GL.h>,除了核心 OpenGL API 之外,图形接口实现提供的所有扩展 API 都在这个头文件中定义。
当普遍的 OpenGL SDK 库和头文件使用中,它不一定来自与 OpenGL 驱动程序相同的源平台,如 Windows 和 Linux,这个标准头文件无法始终与驱动程序支持的新 Core API 版本和扩展保持同步。因此,OpenGL ARB 定义了一个新的头文件,<GL/glext.h>,可直接从 OpenGL 注册中心获取。这两个头文件一起使用,就可以提供最新 OpenGL 版本的所有 Profile 以及注册中心定义的所有扩展 API。
另外,<GL/glcorearb.h> 定义 Core Profile API,以及兼容的 ARB 扩展,但不包含 Compatibility Profile API 或其它扩展。
目前,没有 Khronos 支持的机制可以将供应商扩展与 <GL/glcorearb.h> 一起使用,因为缺乏需求,也不知道哪些供应商扩展与 Core Profile 兼容。将来,这可能会假设 <GL/glcoreext.h> 头文件来解决,定义那些未在 <GL/glcorearb.h> 中定义的,其他与核心配置兼容的供应商扩展定义 API。大多数旧的扩展与核心配置文件不兼容。
使用 Compatibility Profile API 的应用程序应该引用 <GL/GL.h> 和 <GL/glext.h> 头文件。
使用 Core Profile API 而且不需要供应商扩展的应用程序应该引用 <GL/glcorearb.h> 头文件。
通过使用核心 API 头文件,为新开发的应用程序提供了更高的保护,以防止意外使用已从核心配置中删除的旧功能,以及使用移植性较差的扩展或供应商扩展。当应用程序还打算在仅支持核心配置文件的其他平台上运行时,这有助于在支持 Compatibility Profile 的 OpenGL 接口实现上开发应用程序。
在旧式图形硬件还未引入可编程的着色器概念时,尽管可以通过一些状态配置来指定操作的细节,这就是 OpenGL 固定功能的图形渲染工作方式。当 GPU 概念引入可编程的着色器后,为了保留旧式的固定功能图形渲染工作方式,OpenGL 为上下文引入了 Compatibility Profile 工作模式,而 Core Profile 则更能细致地体现可编程着色器带来的性能提升。
对于程序员来说,OpenGL 是一组允许在二维或三维中指定几何对象的命令,以及控制如何将这些对象渲染到帧缓冲区的命令。
典型 OpenGL 程序首先应该调用打开一个窗口,进入将要绘制的帧缓冲区。然后,调用以分配 OpenGL 上下文与窗口关联。一旦分配了一个 OpenGL 上下文,程序员就可以自由地发出 OpenGL 命令。一些函数调用用于绘制简单的几何对象,即点、线段和多边形,而另一些则影响这些基本体的渲染,包括光照、着色,以及它们如何从用户的二维或三维模型空间映射到二维屏幕。还有一些调用可以直接控制帧缓冲区,例如读取和写入像素。
对于 OpenGL 规范的实现者来说,即硬件驱动开发者,OpenGL 是一组影响图形硬件操作的命令。如果硬件只包含一个可寻址的帧缓冲区,那么 OpenGL 必须几乎完全在主机 CPU 上实现。更典型的是,图形硬件可能包括不同程度的图形加速,从能够绘制二维线、多边形的光栅子系统,到能够转换、计算几何数据的复杂浮点处理器。OpenGL 规范实现者的任务是提供 CPU 软件接口,同时在 CPU 和图形硬件之间分配每个 OpenGL 命令的工作。并且必须根据可用的图形硬件进行定制,以在执行 OpenGL 调用时获得最佳性能。
OpenGL 维护着大量的状态信息,控制如何将对象绘制到帧缓冲区中。用户可以直接使用其中一些状态:通过函数调用获取其值。然而,有些只能通过它对所画内容的影响才能看得见。
OpenGL 可以视为一个渲染管道,它有一些可编程的阶段,和一些状态驱动阶段,控制一组特定绘图操作。这个模型应该满足应用开发者和驱动实现者需求的规范,然而,它不一定为实现提供一个模型。驱动层的实现必须产生与指定方法产生的结果一致的结果,但可能有比指定方法更有效的方法来执行特定计算。
OpenGL 根据多种可选模式和着色器程序绘制图元,图元都是一个点、线段、多边形或像素矩形这样的基本图形元素,每种模式都可以独立改变。各种模式的设置不会相互影响,尽管许多模式可能会相互作用,以确定最终在帧缓冲区中的内容。通过以函数或过程调用的形式发送命令来设置模式、指定原语和描述其他操作。
图元 Primitives 由一组或多个顶点定义,一个 Vertex 顶点定义一个 Point,加一个终结点定义一个边,或者两条边相遇点作为多边形的边角。位置坐标、颜色、法线、纹理坐标等数据与一个顶点相关联,也就是作为顶点属性存在,每个顶点以相同的方式独立处理。这也就是 Vertex 和 Point 的内涵区别,在一般情况下,它们是等价的。
该规则的唯一例外是,如果必须剪裁顶点组,以使指示的基本体适合指定区域;在这种情况下,可以修改顶点数据并创建新的顶点。剪裁的类型取决于顶点组代表什么图元。
GL 命令总是按照接收的顺序进行处理,尽管在实现命令的效果之前可能会有不确定的延迟。这意味着,例如,在任何后续图元影响帧缓冲区之前,必须完全绘制一个图元,这还意味着查询和像素读取操作返回的状态与所有之前调用的命令的完整执行一致,除非另有明确规定。一般来说,GL 命令对 GL 模式或帧缓冲区的效果必须在任何后续命令产生任何此类效果之前完成。
在 GL 命令中,数据绑定在调用时发生。这意味着,当接收到某个命令时,将解释传递给该命令的数据。即使命令需要指向数据的指针,在调用时也会解释这些数据,并且对数据的任何后续更改对当前 GL 命令没有影响,除非在后续命令中使用相同的指针。
GL 命令直接控制 3D/2D 图形的基本操作,包括指定应用程序定义的着色器程序的参数,这些着色器程序执行变换、照明、纹理和着色操作,以及抗锯齿和纹理过滤等内置功能。OpenGL 描述复杂几何对象渲染方式的机制,而不是描述复杂对象本身的建模机制。
用于解释 GL 命令的模型是 Client-Server 模型,也就是说,应用程序作为客户端向 OpenGL 接口服务发出命令,这些命令由 GL 服务器解释和处理。服务器可能与客户端在同一台计算机上运行,也可能与客户端不在同一台计算机上运行。从这个意义上说,这是网络透明的服务器,可以维护多个 GL 上下文,每个都是当前 GL 状态的封装。客户端可以选择连接到这些上下文中的任何一个,当程序未连接到上下文时发出 GL 命令会导致未定义的行为。
GL 命令与两类帧缓冲区交互:窗口系统提供的和应用程序创建的。任何时候都只有一个窗口系统提供的帧缓冲区,称为默认帧缓冲区,Default Framebuffer。应用程序创建的帧缓冲区,称为帧缓冲区对象,Framebuffer Object,可以根据需要创建。这两种类型的帧缓冲区主要通过配置和管理其状态的接口来区分。
GL 命令对默认帧缓冲区的影响最终由窗口系统控制,该系统分配帧缓冲区资源,在任何给定时间确定 GL 可以访问默认帧缓冲区的哪些部分,并向 GL 传达这些部分的结构。因此,没有用于初始化 GL 上下文或配置默认帧缓冲区的 GL 命令。
类似地,帧缓冲区内容在物理显示设备上的显示不由 GL 命令处理,包括通过伽马校正等技术对单个帧缓冲区值的转换。
默认帧缓冲区的分配和配置在 GL 之外的窗口系统进行,使用前面介绍的各个系统配套的 API 操作。GL 上下文的分配和初始化也使用这些配套 API 完成。GL 上下文通常可以与不同的默认帧缓冲区相关联,某些上下文状态在执行此关联时确定。也可以在不使用默认帧缓冲区的情况下使用 GL 上下文,在这种情况下,必须使用帧缓冲区对象来执行所有渲染,应用程序需要执行离屏渲染时非常有用,Offscreen Rendering。
GL 设计用于在一系列图形平台上运行,具有不同的图形功能和性能。为了适应这种变化,某些 GL 操作指定了理想行为,而不是实际行为。在允许偏离理想的情况下,还指定了实现必须遵守的规则,以有效地近似理想行为。这种允许的 GL 行为变化意味着,即使在相同的帧缓冲区配置上运行,两个不同的 GL 实现在相同的输入条件下,也可能呈现不一致的结果。
最后,命令名、常量和类型在基本名字前加上前缀,gl 或 GL 或 GL_ 以避免和其它的包名冲突,文档中为了简化,可能会省略这些前缀。
虽然 GL 经常在帧缓冲区上执行操作,但帧缓冲区不是 GL 状态的一部分。GL 保持着相当大的状态数据,有对应的命令更改每个状态变量。为了便于讨论,状态变量根据其函数进行了任意分类。
要区分两种状态:
- 第一种状态称为 GL 服务器状态,位于 GL 服务器中,大多数状态都属于这一类。
- 第二种状态称为客户机状态,位于客户程序中,客户状态是专门确定的。
除非另有规定,本文件中提及的所有状态均为服务器状态。GL 上下文的每个实例都意味着一套完整的 GL 服务器状态,从客户机到服务器的每个连接都意味着一组客户机状态和服务器状态。
虽然 GL 的实现可能依赖于硬件,但本讨论与实现 GL 的特定硬件无关。因此,只有当图形硬件的状态与 GL 状态精确对应时,才需要关注图形硬件的状态。
一组上下文通过共享对象来共享状态是可行的,通过前面提到的窗口系统的绑定 API 操作,这些 API 负责创建和管理上下文对象,可以参数规范文档中的附录 D,Shared Objects and Multiple Contexts。除本附录中的定义外,上下文中的所有状态仅特定于该上下文对象。
以下是 Compatibility Profile 和 Core Profile 模式的工作流程图。
+==============+ +=======================+ +===============+ +==============+
==> | Evaluator | => | Per−Vertex Operations | => | Rasterization | => | Per−Fragment |
+===^======^===+ | Primitive Assembly | +====^=====^====+ | Operations |
| | +=======================+ | | +======v=======+
| | | | |
| | +================+ | |
| +==================+ +====> | Texture Memory | | |
| | Pixel Operations | ====+ +================+ | |
| +==^==========^====+ | | |
| | | +==========================+ +======v======+
| | | | |
+===^======^===+ | | Framebuffer |
==> | Display List | +=============================================> | |
+==============+ +======^======+
Figure 2.1. Block diagram of the GL [Compatibility Profile]
Vertex +=======================+ +====================+
Data | Vertex Shading and | | Primitive Assembly |
Input => | Per-Vertex Operations | => | and Rasterization |
+=======================+ +=======^=======v====+
| | |
| +=========+ | |
+===========+ | | Texture | >=============+ |
| Transferm | <==+ +==> | Memory | |
| Feedback | | +=========+ +================v========+
+===========+ | | Fragment Shading and |
| | Per−Fragment Operations |
| +=============v===========+
+======^======+ |
Pixel | Pixel | +=============+ |
Data <==> | Pack/Unpack | <==> | Framebuffer | <=====+
Output +=============+ +=============+
Figure 2.1. Block diagram of the GL [Core Profile]
虽然以上两种 OpenGL 工作模式不同,但它们都是在描述渲染管线的工作流程,在 OpenGL 4.3 以后的规范文档中,已经不使用这种过时的流程描述。
示意图还是明确展示了 Compatibility Profile 模式下,最大的区别之一就是使用的 Display List。
命令在左侧输入,一些命令指定要绘制的几何对象,而另一些命令控制各个阶段如何处理对象。大多数命令可能会在显示列表中排队执行,否则,命令将直接通过渲染管道执行。
第一阶段通过计算输入值的多项式函数,提供了一种逼近曲线和曲面几何的有效方法。
下一阶段操作由顶点描述的几何图元:点、线段和多边形。在此阶段中,顶点被变换和照亮,然后组装成几何图元。
再下一阶段,几何体着色可以选择使用几何图元来生成新的图元。最终生成的图元被剪切到一个观察空间,为下一阶段的光栅化做准备。
光栅化器使用点、线段或多边形的二维描述生成一系列帧缓冲区地址和值。这样产生的每个片段都会被送入下一个阶段,在它们最终改变帧缓冲区之前,在片段着色器中对各个片段执行操作。这些操作包括基于传入和以前存储的深度值(以实现深度缓冲)对帧缓冲区进行条件更新,将传入的片段颜色与存储的颜色混合,以及对片段值进行掩蔽和其他逻辑操作。
最后,有一种方法绕过管道的顶点处理部分,将片段块直接发送到各个片段操作,最终将像素块写入帧缓冲区,也可以读取值。
规范文档讨论命令的执行,都是按单线程序环境进行的,驱动程序为了高效执行命令,可能会在显示列表队列中缓存多条等待执行的命令。
为了确保命令完全执行,OpenGL 提供以下两个命令,它们都是将所有等待执行的命令推送出去立即执行,但 Finish() 函数调用会等待它们真正执行完成后才返回:
void Flush( void );
void Finish( void );在 OpenGL 4.3 之前的规范文档中,第二部分 OpenGL Operation 详细讲解了固定功能的各个阶段操作相关的命令,但 Compatibility Profile 和 Core Profile 模式下使用不同的命令。
例如,指定顶点坐标数据,可以看到 Core Profile 的命令名字中多了 Attrib:
// Compatibility Profile vertex specification
// Vertices are specified by giving their coordinates in two, three, or four dimensions.
void Vertex{234}{sifd}( T coords );
void Vertex{234}{sifd}v( const T coords );
// Vertex coordinates may be stored as packed components within a larger natural type.
void VertexP{234}ui(enum type,uint coords)
void VertexP{234}uiv(enum type,const uint *coords)
// Core Profile vertex specification
void VertexAttrib{1234}{sfd}( uint index, T values );
void VertexAttrib{123}{sfd}v( uint index, const T values );
void VertexAttrib4{bsifd ub us ui}v( uint index, const T values );
void VertexAttrib4Nub( uint index, T values );
void VertexAttrib4N{bsi ub us ui}v( uint index, const T values );
void VertexAttribP{1234}ui(uint index,enum type,boolean normalized,uint value)
void VertexAttribP{1234}uiv(uint index,enum type,boolean normalized,const uint *value)当定义数据的顶点数组未启用时,定义顶点的通用属性,可以通过发出 VertexAttrib 命令随时更改通用着色器属性中声明为浮点标量、向量或矩阵的当前值。
大多数几何对象的绘制都会在 Begin/End 命令对之间完成,可以根据要绘制的图形数量来成对地使用它们:
void glBegin (GLenum mode);
void glEnd (void);这些输入的顶点会构成什么图元 Primitive 就通过 mode 指定一个相应的枚举值:
| GL2.1 | GL3.3 | GL4.5 | 基本图元类型 |
|---|---|---|---|
| ✓ | ✓ | ✓ | GL_POINTS 点 |
| ✓ | ✓ | ✓ | GL_LINES 线段 |
| ✓ | ✓ | ✓ | GL_LINE_STRIP 多段线 |
| ✓ | ✓ | ✓ | GL_LINE_LOOP 线圈 |
| ✓ | ✓ | ✓ | GL_TRIANGLES 三角形 |
| ✓ | ✓ | ✓ | GL_TRIANGLE_STRIP 三角形条带 |
| ✓ | ✓ | ✓ | GL_TRIANGLE_FAN 三角形扇 |
| ✓ | ✄ | ✄ | GL_QUADS 四边形 |
| ✓ | ✄ | ✄ | GL_QUAD_STRIP 四边形条带 |
| ✓ | ✄ | ✄ | GL_POLYGON 多边形(凸) |
| - | ✓ | ✓ | GL_LINE_STRIP_ADJACENCY |
| - | ✓ | ✓ | GL_LINES_ADJACENCY |
| - | ✓ | ✓ | GL_TRIANGLE_STRIP_ADJACENCY |
| - | ✓ | ✓ | GL_TRIANGLES_ADJACENCY |
| - | - | ✓ | GL_PATCHES |
OpenGL 中的命令取名都与数据类型相关,命令除了基本名还后缀了数据类型,以顶点数据指定命令为例:
void Vertex3f( float x, float y, float z );
void Vertex2sv( short v[2] );通常命令结构如下定义,v 表示向量,即有多个分量:
rtype Name{∈1234}{∈ b s i f d ub us ui}{∈v}
( [args ,] T arg1 , ... , T argN [, args] );
类型简写与对应 OpenGL 数据类型:
| Letter | GL Type |
|---|---|
| b | byte |
| s | short |
| i | int |
| f | float |
| d | double |
| ub | ubyte |
| us | ushort |
| ui | uint |
| i64 | int64 (OpenGL v3.3+) |
| ui64 | uint64 (OpenGL v3.3+) |
OpenGL 数据类型与 bit 宽度:
| GL Type | Bit Width | Description |
|---|---|---|
| boolean | 1 | Boolean |
| byte | 8 | Signed twos complement binary integer |
| ubyte | 8 | Unsigned binary integer |
| char | 8 | Characters making up strings |
| short | 16 | Signed twos complement binary integer |
| ushort | 16 | Unsigned binary integer |
| int | 32 | Signed twos complement binary integer |
| uint | 32 | Unsigned binary integer |
| int64 | 64 | Signed twos complement binary integer |
| uint64 | 64 | Unsigned binary integer |
| sizei | 32 | Non-negative binary integer size |
| enum | 32 | Enumerated binary integer value |
| intptr | ptrbits | Signed twos complement binary integer |
| sizeiptr | ptrbits | Non-negative binary integer size |
| sync | ptrbits | Sync object handle (see section 5.7) |
| bitfield | 32 | Bit field |
| half | 16 | Half-precision floating-point value |
| encoded | in | an unsigned scalar |
| float | 32 | Floating-point value |
| clampf | 32 | Floating-point value clamped to [0,1] |
| double | 64 | Floating-point value |
| clampd | 64 | Floating-point value clamped to [0,1] |
其中 ptrbits 表示指针类型所需的位数;换句话说,intptr、sizeiptr 和 sync 类型必须足够大,以存储任何指针地址。
- 2.7 Vertex Specification
- 2.8 Vertex Arrays
- 2.8.1 Packed Vertex Data Formats
- 2.8.2 Drawing Commands
- 2.9 Buffer Objects
- 2.9.1 Creating and Binding Buffer Objects
- 2.9.2 Creating Buffer Object Data Stores
- 2.9.3 Mapping and Unmapping Buffer Data
- 2.9.4 Effects of Accessing Outside Buffer Bounds
- 2.9.5 Copying Between Buffers
- 2.9.6 Vertex Arrays in Buffer Objects
- 2.9.7 Array Indices in Buffer Objects
- 2.9.8 Buffer Object State
- 2.10 Vertex Array Objects
- 2.11 Rectangles
- 2.12 Fixed-Function Vertex Transformations
- 2.12.1 Matrices
- 2.12.2 Normal Transformation
- 2.12.3 Generating Texture Coordinates
- 2.13 Fixed-Function Vertex Lighting and Coloring
- 2.13.1 Lighting
- 2.13.2 Lighting Parameter Specification
- 2.13.3 ColorMaterial
- 2.13.4 Lighting State
- 2.13.5 Color Index Lighting
- 2.13.6 Clamping or Masking
- 2.14 Vertex Shaders
- 2.14.1 Shader Objects
- 2.14.2 Program Objects
- 2.14.3 Vertex Attributes
- 2.14.4 Uniform Variables
- 2.14.5 Samplers
- 2.14.6 Varying Variables
- 2.14.7 Shader Execution
- 2.14.8 Required State
- 2.15 Geometry Shaders
- 2.15.1 Geometry Shader Input Primitives
- 2.15.2 Geometry Shader Output Primitives
- 2.15.3 Geometry Shader Variables
- 2.15.4 Geometry Shader Execution Environment
- 2.16 Coordinate Transformations
- 2.16.1 Controlling the Viewport
- 2.17 Asynchronous Queries
- 2.18 Conditional Rendering
- 2.19 Transform Feedback
- 2.20 Primitive Queries
- 2.21 Flatshading
- 2.22 Primitive Clipping
- 2.22.1 Color and Associated Data Clipping
- 2.23 Final Color Processing
- 2.24 Current Raster Position
OpenGL 4.6 Core Profile 规范手册的封面上,完整地描绘了最新渲染管道中数据的流向。还有官方的 OpenGL API Reference Card 文档也有详细的 OpenGL Pipeline 流程图。

- https://www.khronos.org/opengl/wiki/History_of_OpenGL
- https://learnopengl.com/Getting-started/Hello-Window
- https://www.khronos.org/opengl/wiki/OpenGL_Extension
- https://www.khronos.org/opengl/wiki/Load_OpenGL_Functions
- https://www.khronos.org/opengl/wiki/OpenGL_Loading_Library
- https://www.khronos.org/opengl/wiki/Related_toolkits_and_APIs
- GLFW: OpenGL, OpenGL ES and Vulkan https://www.glfw.org
- GLEW: The OpenGL Extension Wrangler Library http://glew.sourceforge.net
- Glad: Multi-Language GL/GLES/EGL/GLX/WGL Loader-Generator https://glad.dav1d.de
OpenGL 所有 API 文档及已注册的扩展都可以通过 git 克隆下载:
> git clone git@github.com:KhronosGroup/OpenGL-Refpages
> git clone git@github.com:KhronosGroup/OpenGL-Registry
> git clone git@github.com:KhronosGroup/GLSL如果想深入了解 OpenGL 扩展,官方的 OpenGL Extension Registry 信息文档是必不可少的参考。目前包含超过 300 个扩展的信息,以及 OpenGL 和 OpenGL ES/SC 各个版本的技术规范文档,各种 OpenGL API 加载器也需要根据这些文档进行开发。在这个仓库中的文件都是以扩展前缀目录进行管理的,前缀含义主要是硬件供应商,如 AMD、APPLE,还有部分前缀具有特殊含义:
- ARB 前缀表示 OpenGL Architecture Review Board 体系结构审核委员会认可的扩展。
- ANGLE 前缀表示 Google ANGLE - Almost Native Graphics Layer Engine 项目提供的扩展。
- ARM 前缀表示。
- EXT 前缀表示多个厂商共同协商使用一致的扩展。
- KHR Khronos-approved (ARB, OES, or KHR vendor suffixed) extensions
- OES 前缀表示 OpenGL ES Extension。
Google ANGLE 扩展的主要目的是为 OpenGL ES 和 WebGL 应用实现无缝迁移,也就是要实现 OpenGL ES 的网页版本,目前已经实现 OpenGL ES 2.0, 3.0 和 3.1 到 Vulkan, OpenGL, OpenGL ES, Direct3D 9, Direct3D 11。未来还会可能实现 OpenGL ES 3.2,转译到 Metal 和 MacOS, Chrome OS, Fuchsia 的支持。
利用扩展,即便是 OpenGL 低版本也能实现大部分高版本的功能。使用扩展时,要注意优先级,标准 > ARB >EXT,优先使用标准功能,其次 ARB 扩展,然后 EXT 扩展。通常,ARB, OES, KHR, EXT 扩展大多可以跨平台,其他扩展大多都是平台相关的。
OpenGL 作为图形库规范,本身并没有 SDK,想要启用高级 OpenGL 都是通过扩展获取相应的函数指针来完成的,当然必须由显卡的驱动支持才行。不过有些库可以帮你完成这类繁琐的工作,比如 GLEW,或者 GLAD。
OpenGL 作为一个跨平台的通用图形标准规范,其所规定接口的具体的实现是由显卡的硬件驱动程序开发商提供的。由于支持 OpenGL 接口的硬件驱动版本众多,规范又不能替代操作系统对相应的驱动程序进行接口规范,驱动程序大多数函数的位置都无法在编译时确定下来,需要在 OpenGL 程序在运行时查询。
因为通用性好,在各个平台上都会有 OpenGL 接口规范的基本实现,也会提供相应的头文件,例如 Windows 会提供 opengl32.lib 基本库,并提供 wglGetProcAddress() 函数用来查询 OpenGL 扩展函数的地址,尽管这个平台为了自家的 DirectX 会不露声色地打压 OpenGL。在 Linux 系统上,通常使用 glXGetProcAddress() or glXGetProcAddressARB() 函数来查询 OpenGL 扩展函数的地址。
基本的功能可以提供现成的,而其它更多的扩展功能却不能,只能通过运行时检测是否有硬件及驱动支持。所以,任务就落在了开发者身上,开发者需要在运行时获取函数地址并将其保存在一个函数指针中供以后使用。函数地址的获取方法因平台而异,代码非常复杂,而且很繁琐,我们需要对每个可能使用的函数都要重复这个过程。幸运的是,有些库能简化此过程,其中 GLAD 是目前最新,也是最流行的库。GLAD 是用来管理 OpenGL 的函数指针的 OpenGL API 加载库,可以使 OpenGL 基础渲染变得简单。所以在使用 GLAD 时,调用任何 OpenGL 的函数之前需要初始化 GLAD。
GLAD 是一个网络服务,提供了根据页面选择 OpenGL 版本及配置,生成相应的导出库的源码,多语言支持。GLAD 应该提供了一个 zip 压缩文件供下载使用,包含两个头文件目录,和一个 glad.c 文件,这是 API 加载器的实现。将两个头文件目录 glad 和 KHR 复制到系统默认的 Include 文件夹中。或者为编译配置增加一个额外的配置项指向这些目录,最后将 glad.c 文件引入到工程中。
还有其它好用的 OpenGL API 加载器,如 GLFW 和 GLEW,它们都实现了运行时查询机制,以获取系统支持的 OpenGL 扩展。GLFW 基于 C 语言开发的针对 OpenGL、OpenGL ES 和 Vulkan 提供了一些渲染物体所需的最低限度的接口。它允许用户 创建 OpenGL 上下文,定义窗口参数以及处理用户输入。GLEW 全称 The OpenGL Extension Wrangler Library 是基于 C/C++ 开发的 OpenGL 扩展加载器。
GL3W 加载器主要关注 OpenGL 3/4 Core Profile,它只加载核心函数入口点地址,支持 Windows, Mac OS X, Linux, FreeBSD。
DevIL 是图象纹理处理、加载库,旧称 OpenIL,加载各种常见格式的图片,API 接口跟 OpenGL 一致性很强。
更早期的工具是 GLUT - The OpenGL Utility Toolkit,太旧了不要再用,现在已经改为 FreeGLUT。
OpenGL 程序要使用独显运行,需要根据显卡驱动来设置。根据 NVIDIA Optimus Rendering Policies 文档,在代码中定义相应的符号可以激活独显。以下激活 N 卡或 A 卡,程序打开时就会默认使用独显运行。
// https://docs.nvidia.com/gameworks/content/technologies/desktop/optimus.htm
// The following line is to favor the high performance NVIDIA GPU if there are multiple GPUs
// Has to be .exe module to be correctly detected.
extern "C" __declspec(dllexport) DWORD NvOptimusEnablement = 0x00000001;
// And the AMD equivalent
// Also has to be .exe module to be correctly detected.
extern "C" __declspec(dllexport) int AmdPowerXpressRequestHighPerformance = 0x00000001;激活独显后,就可以查询到 OpenGL 程序使用的独立显卡信息:
GL_SHADING_LANGUAGE_VERSION:4.60 NVIDIA
GL_SHADING_LANGUAGE_VERSION_ARB:4.60 NVIDIA
GL_RENDERER:GeForce GTX 1050/PCIe/SSE2
GL_VENDOR:NVIDIA Corporation
GL_VERSION:4.6.0 NVIDIA 461.40这个方法是系统层显卡驱动在程序执行时检测的一个标记,有这个标记,则用独显运行。NVIDIA 的 Optimus 技术可以在笔记本上兼顾耗电量和性能,并能做到自动无缝切换。除了上面的方法,还有多种方法可以切换程序所使用的显卡:
- 在 BIOS 设置:支持 Optimus 的平台上,在 BIOS 中可以找到选项,可以选择使用 NV、Intel 或者自动切换。但这个是静态的,每次切换都得重启,肯定不是我们想要的。
- 在右键菜单中控制:在程序文件的图标上按右键,菜单里有一个“用图形处理器运行”的项,里面可以选择 NV 卡或者 Intel 卡。
- 在驱动中控制:在 NV 的驱动中,可以通过全局 profile,来控制所有程序是通过 NV 卡或者 Intel 卡来执行。另外还有个 per-app 的 profile,可以让每个程序有不同的显卡配置。
有趣的是,在双卡系统上,如果你在程序中枚举显卡,总会返回两块显卡。如果给程序指定的是 NV 卡,那么枚举结果两块显卡都是 NV 卡。如果选的是 Intel 卡,那么第一显卡是 Intel,第二是 NV。
dxgiFactory -> EnumAdapters(1, &dxgiAdapter),1 is Nvidia GPU index, 0 - intel HD GPU index
使用 OpenGL 接口规范的最新、最佳方案就是 GLAD + GLEW,前者只负载 API 装入,后者带有窗口界面适配。通过它们可以很好地管理 OpenGL 和 OpenGL ES 等扩展。它可以使 OpenGL 基础渲染变得十分简单,只需要简单四个步骤就可以完成基础渲染:
- 初始化 GLAD 库,加载所有 OpenGL 函数指针。
- 创建着色器并附加到着色器程序。
- 构建缓冲对象并附加到顶点属性。
- 使用着色器程序,利用渲染接口将缓冲对象按照指定图元类型渲染出来。
首先,打开 GLAD 主页,这是一个挑选 OpenGL 扩展 API 的配置程序,提供以下配置选项:
- Language 提供 C/C++/D/Nim/Pacal 等多种语言支持
- Specification 可选 OpenGL/WGL/EGL/GLX 等 API 规范
- API Version 选择版本
- Profile 选择模式
- Extensions 选择要使用的扩展 API
- Options 其它选项
- Generate a loader 勾选生成加载器,并在生成的
gladLoadGL执行加载器函数gladLoadGLLoader。 - Omit KHR 勾选忽略生成 khrplatform.h,这是 Khronos 平台规范类型定义文件。
- Local Files 只生成本地,不生成目录结构。
- Generate a loader 勾选生成加载器,并在生成的
以下以加载 glCreateShader() 这个 OpenGL 2.0 引入的扩展 API 为例,说明一下 GLAD 在 Windows 平台下的加载流程:
- 首先,在 glad.h 头文件中声明函数原型;
- 基次,在 glad.c 文件中定义函数指针,并执行加载,然后将返回的指针赋值给定义好的函数指针。
- 执行 gladLoadGL(void) 或者 gladLoadGLLoader(&get_proc) 开始调用系统 API 获取函数地址。
加载 OpenGL API 地址的方法主要是通过以下 Windows 系统调用完成的:
- LoadLibraryW 加载 opengl32.dll;
- GetProcAddress 获取函数地址;
- FreeLibrary 释放 DLL 文件;
// Step 1: declare function prototype in glad.h
#ifndef GL_VERSION_2_0
#define GL_VERSION_2_0 1
GLAPI int GLAD_GL_VERSION_2_0;
...
typedef GLuint (APIENTRYP PFNGLCREATESHADERPROC)(GLenum type);
GLAPI PFNGLCREATESHADERPROC glad_glCreateShader;
...
#endif
// Step 2: define function pointer in glad.c and load
PFNGLCREATESHADERPROC glad_glCreateShader = NULL;
static void load_GL_VERSION_2_0(GLADloadproc load) {
if(!GLAD_GL_VERSION_2_0) return;
...
glad_glCreateShader = (PFNGLCREATESHADERPROC)load("glCreateShader");
...
}
// Step 3: execute loader in glad.c
#include <windows.h>
static HMODULE libGL;
typedef void* (APIENTRYP PFNWGLGETPROCADDRESSPROC_PRIVATE)(const char*);
static PFNWGLGETPROCADDRESSPROC_PRIVATE gladGetProcAddressPtr;
static int open_gl(void) {
libGL = LoadLibraryW(L"opengl32.dll");
if(libGL != NULL) {
void (* tmp)(void);
tmp = (void(*)(void)) GetProcAddress(libGL, "wglGetProcAddress");
gladGetProcAddressPtr = (PFNWGLGETPROCADDRESSPROC_PRIVATE) tmp;
return gladGetProcAddressPtr != NULL;
}
return 0;
}
static void close_gl(void) {
if(libGL != NULL) {
FreeLibrary((HMODULE) libGL);
libGL = NULL;
}
}
static void* get_proc(const char *namez) {
void* result = NULL;
if(libGL == NULL) return NULL;
if(result == NULL) {
result = (void*)GetProcAddress((HMODULE) libGL, namez);
}
return result;
}
int gladLoadGL(void) {
int status = 0;
if(open_gl()) {
status = gladLoadGLLoader(&get_proc);
close_gl();
}
return status;
}
int gladLoadGLLoader(GLADloadproc load) {
GLVersion.major = 0; GLVersion.minor = 0;
glGetString = (PFNGLGETSTRINGPROC)load("glGetString");
if(glGetString == NULL) return 0;
if(glGetString(GL_VERSION) == NULL) return 0;
find_coreGL();
...
load_GL_VERSION_2_0(load);
...
if (!find_extensionsGL()) return 0;
load_GL_ARB_sample_shading(load);
load_GL_ARB_shading_language_include(load);
return GLVersion.major != 0 || GLVersion.minor != 0;
}以下是摘抄自 Learn OpenGL 教程的示范,例子搭配了 GLEW 和 GLAD:
#include <glad/glad.h>
#include <GLFW/glfw3.h>
#include <iostream>
void framebuffer_size_callback(GLFWwindow* window, int width, int height);
void processInput(GLFWwindow *window);
// settings
const unsigned int SCR_WIDTH = 800;
const unsigned int SCR_HEIGHT = 600;
int main()
{
// glfw: initialize and configure
// ------------------------------
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
#ifdef __APPLE__
glfwWindowHint(GLFW_OPENGL_FORWARD_COMPAT, GL_TRUE);
#endif
// glfw window creation
// --------------------
GLFWwindow* window = glfwCreateWindow(SCR_WIDTH, SCR_HEIGHT, "LearnOpenGL", NULL, NULL);
if (window == NULL)
{
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
glfwMakeContextCurrent(window);
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
// glad: load all OpenGL function pointers
// ---------------------------------------
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress))
{
std::cout << "Failed to initialize GLAD" << std::endl;
return -1;
}
// render loop
// -----------
while (!glfwWindowShouldClose(window))
{
// input
// -----
processInput(window);
// render
// ------
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
// glfw: swap buffers and poll IO events (keys pressed/released, mouse moved etc.)
// -------------------------------------------------------------------------------
glfwSwapBuffers(window);
glfwPollEvents();
}
// glfw: terminate, clearing all previously allocated GLFW resources.
// ------------------------------------------------------------------
glfwTerminate();
return 0;
}
// process all input: query GLFW whether relevant keys are pressed/released this frame and react accordingly
// ---------------------------------------------------------------------------------------------------------
void processInput(GLFWwindow *window)
{
if(glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
}
// glfw: whenever the window size changed (by OS or user resize) this callback function executes
// ---------------------------------------------------------------------------------------------
void framebuffer_size_callback(GLFWwindow* window, int width, int height)
{
// make sure the viewport matches the new window dimensions; note that width and
// height will be significantly larger than specified on retina displays.
glViewport(0, 0, width, height);
}- https://www.opengl.org/resources/libraries/glut/glut_downloads.php
- OpenGL Utility Libraries https://www.opengl.org/resources/libraries
- GLUT API version 3 https://www.opengl.org/resources/libraries/glut/spec3/spec3.html
- The Free OpenGL Utility Toolkit http://freeglut.sourceforge.net/
- Khronos EGL Registry https://www.khronos.org/registry/EGL/
- Beginner's Guide to Linkers by David Drysdale https://www.lurklurk.org/linkers/linkers.html
以下基于 FreeGLUT 进行原理上的简要分析,但并不建议实际中使用,毕竟太过落后,很多该有的配置都没有。
最后一版是 GLUT Release 3.7, May 7, 1998,Mark Kilgard 为了支持 OpenGL 红宝书第二版示范代码而编写的一套工具。OpenGL 'RedBook' 命名是 OpenGL Programming Guide。注意,Mark 不是这本书的作者,他本人有另外一本书 Programming OpenGL for the X Window System 是用 GLUT 作演示的。
GLUT 负责创建窗口、初始化 OpenGL 上下文和处理输入事件所需的所有系统特定的杂务,以实现真正可移植的 OpenGL 程序,在当时这些功能有的整合确实非常好用,包括现在也是这种逻辑框架。但是它并不是现在最合适、最好的工具,GLUT 曾经大流行过,也给现在带来了相当大的影响,也正是因为如此,才有必要对 GLUT 有一点清晰的认识。
根本原因是 GLUT 其许可证不允许任何人分发修改过的库代码,所以在作者不再更新后就没有人去做这个工作了。这真的很不幸,因为功能过时,但需求功能越来越多,确实需要改进。
FreeGLUT 使用 X-Consortium 许可证,非盈利性质,最初由 Pawel W.Olszta 编写,Andreas Umbach 和 Steve Baker 也有贡献。John F.Fay、John Tsiombikas 和 Diederick C.Niehorster 是 freeglut 项目的当前维护者,最后一版是 29 September 2019, freeglut 3.2.1,已经基本完全实现并替换 GLUT 所有功能。
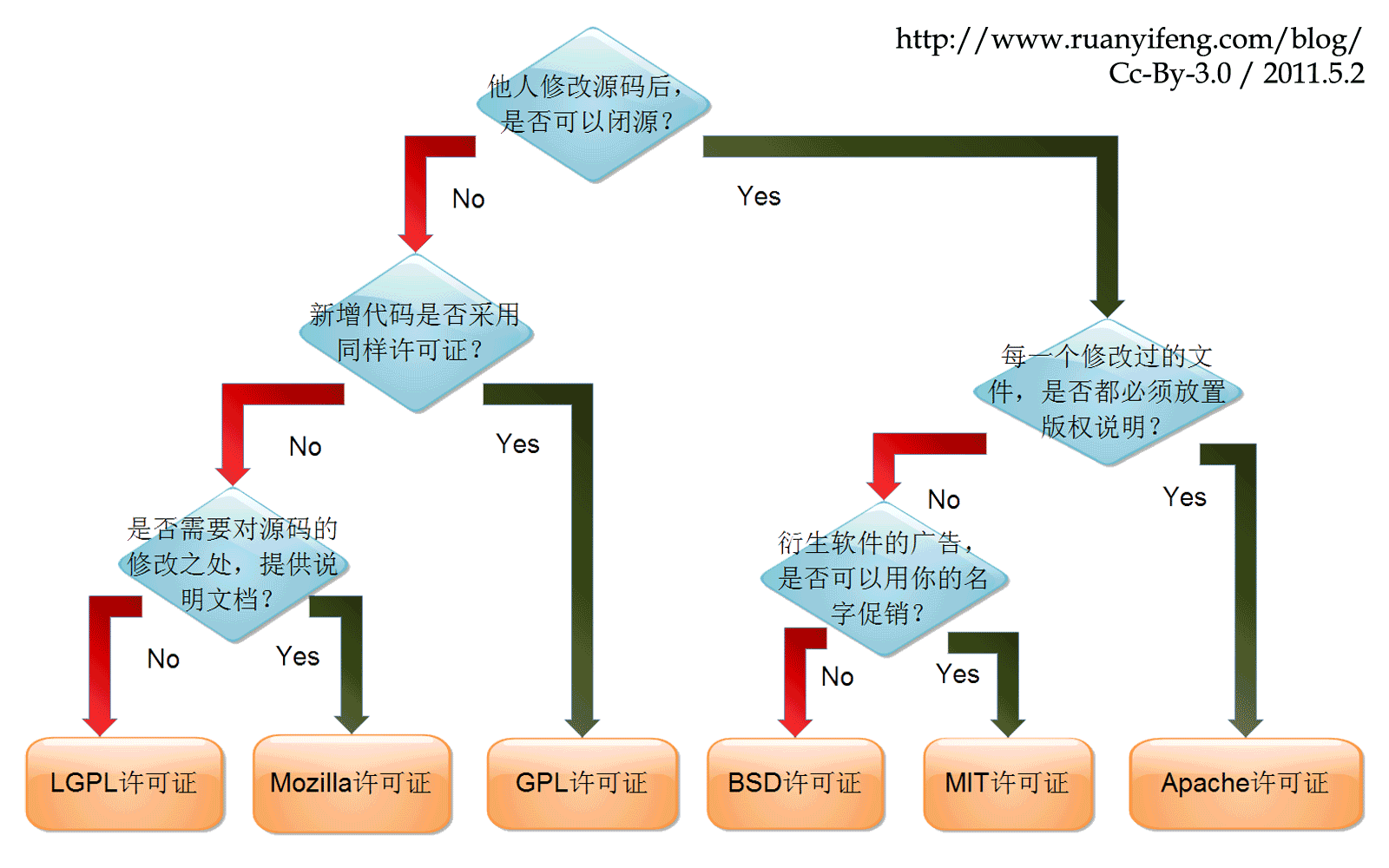
世界上流行的开源许可证大概有 6 种,在这些许可证之中做选择,也已经是复杂的事,但可以通过 5 个问题简单化处理:
他人修改软件后可以闭源吗?
├── YES!每一个改动是否必需放置版权声明?
│ ├── Yes! 👉 Apache License
│ └── No!衍生软件的广告是否可以用自己的署名?
│ ├── Yes! 👉 MIT License
│ └── No! 👉 BSD License
└── NO!新增代码采用同样许可证吗?
├── Yes! 👉 GLP License
└── NO!是否需要对源代码的改动提供文档?
├── Yes! 👉 Mozilla License
└── No! 👉 LGPL License
以下是源自乌克兰程序员 Paul Bagwell 制作的许可证筛选流程图,只用两分钟,你就能搞清楚这六种许可证之间的最大区别。
如果 FreeGLUT 配合 MinGW GCC 编译器,需要正确设置相应的库,可以先编译 FreeGLUT,引用生成的库文件。并且,在 Windows 系统上需要 opengl32 基本库,尽管它只提供的 OpenGL 1.1 的实现。为链接程序设置子系统类型 --subsystem,windows 可以让程序运行在 GUI 窗口模式,隐藏掉控制台窗口。
gcc -c -o example.o example.c -I"C:\Program Files (x86)\freeglut\include"
gcc -o example.exe example.o -L"C:\Program Files (x86)\freeglut\lib" -lfreeglut -lopengl32 -Wl,--subsystem,windows在 Linux 系统上,libGL 通常会导出完整的 OpenGL API,所以不需要使用 API Loader,这种情况下可以直接使用 FreeeGLUT,并在引用头文件之前,设定义 GL_GLEXT_PROTOTYPES 符号,启用官方头文件中提供的 API 原型声明。MinGW-W64 GCC 8.1.0 包含了 KHnoros 官方文档提供的头文件。 官方 2015 发布的规范头文件,最高版本到 GL_VERSION_4_5,而官方最新的头文件包含到 GL_VERSION_4_6 版本的扩展。
#define GL_GLEXT_PROTOTYPES
#include <GL/glext.h>Khnoros 官方提供的头文件包含的内容类似如下结构:
#include <KHR/khrplatform.h>
// - https://github.com/KhronosGroup/EGL-Registry/tree/main/api/KHR/khrplatform.h
typedef void (APIENTRYP PFNGLDEBUGMESSAGECALLBACKPROC) (GLDEBUGPROC callback, const void *userParam);
#ifdef GL_GLEXT_PROTOTYPES
GLAPI void APIENTRY glDebugMessageCallback (GLDEBUGPROC callback, const void *userParam);
#endif启用 API 原型声明后,在 FreeeGLUT 就不能将 glutGetProcAddress() 获取到的函数指针赋值给函数名。
官方头文件会引用 Khronos platform-specific types and definitions,KHR/khrplatform.h,这个文件可以在 EGL 或 GLAD 项目中找到。主要是定义了一些规范类型,可以不使用:
Types defined in khrplatform.h:
khronos_int8_t signed 8 bit
khronos_uint8_t unsigned 8 bit
khronos_int16_t signed 16 bit
khronos_uint16_t unsigned 16 bit
khronos_int32_t signed 32 bit
khronos_uint32_t unsigned 32 bit
khronos_int64_t signed 64 bit
khronos_uint64_t unsigned 64 bit
khronos_intptr_t signed same number of bits as a pointer
khronos_uintptr_t unsigned same number of bits as a pointer
khronos_ssize_t signed size
khronos_usize_t unsigned size
khronos_float_t signed 32 bit floating point
khronos_time_ns_t unsigned 64 bit time in nanoseconds
khronos_utime_nanoseconds_t unsigned time interval or absolute time in
nanoseconds
khronos_stime_nanoseconds_t signed time interval in nanoseconds
khronos_boolean_enum_t enumerated boolean type.
Win32 存在一个恼人的问题,即存在多个 C 运行时库(CRT)。如果可执行文件与 GLUT DLL 使用不同的 CRT 链接,GLUT DLL 与可执行程序文件将不会共享相同 CRT 静态数据。特别是,如果 GLUT 调用其(不同的)退出例程,则不会调用在可执行文件中注册的 atexit 回调。
GLUT 通常是用“/MD”选项构建的,CRT 和多线程 DLL 支持,但是 Visual C++ 链接器默认为“/ml”(单线程CRT)。
解决这个问题的一个办法是要求用户始终使用与 GLUT 编译时使用的相同 CRT 进行链接。这要求用户提供非标准选项。GLUT 3.7 有自己的内置解决方案,可执行文件的“退出”函数指针被秘密传递给 GLUT。然后,GLUT 调用可执行文件的退出函数指针,以确保在 GLUT 出现时调用应用程序注册的任何“atexit”调用
另外,使用 MSVC 和 GCC 编译器,相应的头文件也有些差别,前者会使用 WINGDIAPI 声明原型,当然也仅限 OpenGL 1.1 版本的 API,需要引入 windows.h 头文件。GCC 使用官方提供的 GLAPI 修饰接口原型。
另外,因为使用了 strdup() 这些函数,在做静态链接时会出现符号找不到的错误:
#if defined(_MSC_VER) || defined(__WATCOMC__)
/* strdup() is non-standard, for all but POSIX-2001 */
#define strdup _strdup
#endif通常,MSVC 编译程序做静态链接时应该采用 /MT,而 FreeGLUT 则不是,虽然使用的是 freeglut_static.lib 静态链接库,但是却采用 /MD 方式链接,需要在 CMake 配置中为静态链接的程序指定:
add_compile_options(/MT)
target_compile_options(${EXE_NAME} PUBLIC "/MD")简单的说,无法解析的外部符号、符号未定义问题这种常见无非以下几种原因:
- 引用了外部库函数,但在编译器未将库文件引入,或者引入的路径错误、版本不对,所使用编译器不匹配、链接方式不匹配;
- 自己声明的符号却没有提供实现,也有可能是语法错误导致不能正确识别符号,这种容易解决,因为自己清楚;
像 MSVC 基础库不对版这种问题才隐蔽,它本身有多个库,而且有多个链接版本的 CRT(C Run-Time library,C 语言运行库),容易造成不一致问题。另外,在不清楚工程需要引用什么库的这种情况很常见,一般需要先学习认识才能了解需要引用什么库。
GLUT 中有大量的宏应用,以注册键盘事件回调为例,只能直接找到两个相应的原型声明:
/*
* Window-specific callback functions, see fg_callbacks.c
*/
FGAPI void FGAPIENTRY glutKeyboardFunc( void (* callback)( unsigned char, int, int ) );
// * Callbacks with user data arguments.
FGAPI void FGAPIENTRY glutKeyboardFuncUcall( void (* callback)( unsigned char, int, int, void* ), void* user_data );根据 fg_callback_macros.h 头文件中的宏定义,可以找到宏展开式生成一个 fghKeyboardFuncCallback 回调函数。在它内部会调用一个 FGCBKeyboard 函数指针,这个指针由 FGCBUserData 类型的参数传入。
继续展开后面的宏,展开式生成一个 glutKeyboardFunc, glutKeyboardFuncUcall,也就是前面的函数原型的实现。
最后可以跟踪到所有回调函数都会在 SET_WCB 这个宏中记录在通过 SFG_Structure 结构体引用的窗口 tagSFG_Window 对象的 CallBacks 成员中。这个成员是 SFG_Proc 数组,使用 WCB_Keyboard 这样的索引值来设置,一个回调对应一种事件。
总结下来,这套宏为键盘事件的处理生成了以下三个函数的实现:
- glutKeyboardFunc() 用户注册事件回调的函数;
- glutKeyboardFuncUcall() 登记回调函数到窗口对象上;
- fghKeyboardFuncCallback() 执行用户注册的事件回调;
/*
* Freeglut callbacks type definitions
* freeglut-3.2.1\src\fg_internal.h
*
* If anything here is modified or added, update fg_callback_macros.h functions.
*
* This is not ideal, but freeglut needs to either define minimal compiler specs,
* or update header every time this is changed or updated.
*/
typedef void* FGCBUserData;
typedef void (* FGCBKeyboard )( unsigned char, int, int );
// freeglut-3.2.1\src\fg_callback_macros.h
/* Implement all these callback setter functions... */
IMPLEMENT_CURRENT_WINDOW_CALLBACK_FUNC_ARG3_USER(Keyboard,unsigned char,int,int)
#define IMPLEMENT_CURRENT_WINDOW_CALLBACK_FUNC_ARG3_USER(a,arg1,arg2,arg3) \
IMPLEMENT_CALLBACK_FUNC_CB_ARG3_USER(a,a,arg1,arg2,arg3) \
IMPLEMENT_CURRENT_WINDOW_CALLBACK_FUNC_2NAME_GLUT(a,a)
#define IMPLEMENT_CALLBACK_FUNC_CB_ARG3_USER(a,b,arg1,arg2,arg3) \
static void fgh##a##FuncCallback( arg1 arg1val, arg2 arg2val, arg3 arg3val, FGCBUserData userData ) \
{ \
FGCB##b* callback = (FGCB##b*)&userData; \
(*callback)( arg1val, arg2val, arg3val ); \
}
#define IMPLEMENT_CURRENT_WINDOW_CALLBACK_FUNC_2NAME_GLUT(a,b) \
IMPLEMENT_CURRENT_WINDOW_CALLBACK_FUNC_2NAME_GLUT_UCALL(a,b) \
IMPLEMENT_CALLBACK_FUNC_2NAME_GLUT_BASE(a,b)
/*
* And almost every time the callback setter function can be implemented with these:
*/
#define IMPLEMENT_CURRENT_WINDOW_CALLBACK_FUNC_2NAME_GLUT_UCALL(a,b) \
void FGAPIENTRY glut##a##FuncUcall( FGCB##b##UC callback, FGCBUserData userData ) \
{ \
SET_CURRENT_WINDOW_CALLBACK( b ); \
}
#define SET_CURRENT_WINDOW_CALLBACK(a) \
do \
{ \
if( fgStructure.CurrentWindow == NULL ) \
return; \
SET_WCB( ( *( fgStructure.CurrentWindow ) ), a, callback, userData ); \
} while( 0 )
/* SET_WCB() is used as:
*
* SET_WCB( window, cbname, func, udata );
*
* ...where {window} is the freeglut window to set the callback,
* {cbname} is the window-specific callback to set,
* {func} is a function-pointer,
* {udata} is a void* pointer for user data.
*/
#define IMPLEMENT_CALLBACK_FUNC_2NAME_GLUT_BASE(a,b) \
void FGAPIENTRY glut##a##Func( FGCB##b callback ) \
{ \
if( callback ) \
{ \
FGCB##b* reference = &callback; \
glut##a##FuncUcall( fgh##a##FuncCallback, *((FGCBUserData*)reference) ); \
} \
else \
glut##a##FuncUcall( NULL, NULL ); \
}再往深一层就是 FreeGLUT 如何处理窗口消息机制,如何将事件消息数据通过回调传回到用户注册的回调函数上。不同操作系统,实现逻辑不同,Windows 系统的对应实现在 mswin 目录下。
和键盘相关的 Windows 窗口消息就是 WM_KEYDOWN 或 WM_KEYUP 等消息,最后使用 INVOKE_WCB 宏
case WM_SYSKEYDOWN:
case WM_KEYDOWN:
{
window = fghWindowUnderCursor(window);
lRet = fghWindowProcKeyPress(window,uMsg,GL_TRUE,wParam,lParam);
}
case WM_SYSKEYUP:
case WM_KEYUP:
{
window = fghWindowUnderCursor(window);
lRet = fghWindowProcKeyPress(window,uMsg,GL_FALSE,wParam,lParam);
}
INVOKE_WCB( *window, KeyboardUp,
( (char)(wParam & 0xFF), /* and with 0xFF to indicate to runtime that we want to strip out higher bits - otherwise we get a runtime error when "Smaller Type Checks" is enabled */
window->State.MouseX, window->State.MouseY )
);
#define INVOKE_WCB(window,cbname,arg_list) \
do \
{ \
if( FETCH_WCB( window, cbname ) ) \
{ \
FGCB ## cbname ## UC func = (FGCB ## cbname ## UC)(FETCH_WCB( window, cbname )); \
FGCBUserData userData = FETCH_USER_DATA_WCB( window, cbname ); \
fgSetWindow( &window ); \
func EXPAND_WCB( cbname )(( arg_list, userData )); \
} \
} while( 0 )
#define FETCH_WCB(window,cbname) ((window).CallBacks[WCB_ ## cbname])如果是使用老旧的 GLUT 还会涉及 glut.lib、glut32.lib 和对应的 glut.dll、 glut32.dll 两级链接库文件,这些旧文件很烦人,上面出现的多个运行库退出函数问题都处理得不够好。至少应该使用 FreeGLUT 替代它,链接时使用 libfreeglut.a 或者静态库 libfreeglut_static.a。当然还有 Windows 系统提供的基础 opengl32 库。
#include <iostream>
#include <GL/gl.h>
#include <GL/glext.h>
#include <GL/freeglut.h>
using namespace std;
int main(int argc, char *argv[])
{
glutInit (&argc, argv);
glutInitDisplayMode(GLUT_RGBA | GLUT_DOUBLE);
glutCreateWindow("Hello World");
cout << "GL_SHADING_LANGUAGE_VERSION:" << glGetString(GL_SHADING_LANGUAGE_VERSION) << endl;
cout << "GL_SHADING_LANGUAGE_VERSION_ARB:" << glGetString(GL_SHADING_LANGUAGE_VERSION_ARB) << endl;
cout << "GL_VERSION:" << glGetString(GL_VERSION) << endl;
cout << "GL_GetError:" << glGetError() << endl;
return 0;
}当然,使用 FreeGLUT 并不是就没有问题,作为一个相当旧的 OpenGL 加载器,它连 OpenGL 2.0 着色器扩展的相关 API 都没有加载进来,许多规范符号也没有定义。所以默认也是使用不了着色器的,如果程序中使用了这些未在加载器中得到支持的扩展 API,就会出现一堆的未定义引用的错误消息:
opengl.cpp:(.text+0x347): undefined reference to `glCreateShader'
opengl.cpp:(.text+0x3a1): undefined reference to `glShaderSource'
opengl.cpp:(.text+0x3a8): undefined reference to `glCompileShader'
opengl.cpp:(.text+0x3b9): undefined reference to `glGetShaderiv'
opengl.cpp:(.text+0x3d7): undefined reference to `glGetShaderInfoLog'
opengl.cpp:(.text+0x40a): undefined reference to `glAttachShader'
opengl.cpp:(.text+0x433): undefined reference to `glCreateProgram'
opengl.cpp:(.text+0x559): undefined reference to `glLinkProgram'在最后一个版本的 freeglut-3.2.1 示范代码中,有两个例子演示了如何加载着色器扩展:
- demos\shapes\shapes.c
- demos\smooth_opengl3\smooth_opengl3.c
根据当前使用的系统不同而执行不同的 API 去查询扩展接口:
- Windows: wglGetProcAddress( ( LPCSTR )procName )
- EGL: eglGetProcAddress(procName)
- X11: glXGetProcAddressARB( ( const GLubyte * )procName )
WGL 是 OpenGL 在 Windows 平台下的 API 前缀,wglGetProcAddress() 函数在系统提供的 wingdi.h 头文件中声明。
EGL 是 OpenGL ES 和本地窗口系统(native platform window system)之间的一个中间接口层,它主要由系统制造商实现。EGL 提供如下机制:
- 与设备的原生窗口系统通信
- 查询绘图表面的可用类型和配置
- 创建绘图表面
- 在 OpenGL ES 和其他图形渲染 API 之间同步渲染
- 管理纹理贴图等渲染资源
OpenGL ES 是针对 Embedded Systems 嵌入式设备:手机、PDA 和游戏主机等而设计一个 OpenGL 子集,各显卡制造商和系统制造商来实现这组 API。为了让 OpenGL ES 能够绘制在当前设备上,需要 EGL 作为 OpenGL ES 与设备的桥梁。
所以,一个 OpenGL 接口加载器要做的适配工作也是要跨平台的,否则就失去了 OpenGL 通用性的意义。
- GLSL Essentials: Enrich your 3D scenes with the power of GLSL! by Jacobo Rodríguez
- OpenGL Shading Language
- Hello Traiangle
- Getting started Shader
- GLM - OpenGL Mathematics
- LearnOpenGL Shaders https://learnopengl.com/Getting-started/Shaders
- GLSL Built-in Variables https://www.khronos.org/opengl/wiki/Built-in_Variable_(GLSL)
- GLSL Validator https://github.com/KhronosGroup/glslang
- SPIR-V https://en.wikipedia.org/wiki/Standard_Portable_Intermediate_Representation
- The OpenGL® API & GLSL specifications https://www.khronos.org/opengl/
- The OpenGL® Graphics System: A Specification (Version 4.6 (Core Profile) - October 22, 2019)
GLSL 和其 C/C++ 等编程语言一样有数据类型,如 int, float, double, uint, bool,也有数组、结构体,条件判断、循环控件等等,预处理、运算符也类似。有 C 语言基础可以快速掌握着色器语言的基本语言规则。
以下是摘选自 SFML Ensentials Chapter 6 Setting shader uniforms 的一个顶点颜色器程序代码:
#version 110
//varying "out" variables to be used in the fragment shader
varying vec4 vColor;
varying vec2 vTexCoord;
void main()
{
vColor = gl_Color;
vTexCoord = (gl_TextureMatrix[0] * gl_MultiTexCoord0).xy;
gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
}以下是相应的片断着色器部分,这才是魔术的地方:
#version 110
//varying attributes from the vertex shader
varying vec4 vColor;
varying vec2 vTexCoord;
//declare uniforms
uniform sampler2D uTexture;
uniform float uPositionFreq;
uniform float uSpeed;
uniform float uStrength;
uniform float uTime;
void main()
{
vec2 texCoord = vTexCoord;
float coef = sin(gl_FragCoord.x * uPositionFreq + uSpeed + uTime);
texCoord.y += coef * uStrength;
gl_FragColor = vColor * texture2D(uTexture, texCoord);
}
// SFML Ensentials 在 SFML 环境中,应该通过着色器对象的方法设置着色器的输入变量:
auto shader = AssetManager::GetShader("shader.vert", "ripple.frag");
sf::Sprite sprite(AssetManager::GetTexture("myTexture.png"));
sf::Clock clock;
shader->setUniform("uTexture", *sprite.getTexture());
shader->setUniform("uPositionFreq", 0.1f);
shader->setUniform("uSpeed", 20);
shader->setUniform("uStrength", 0.03f);
shader->setUniform("uTime", clock.getElapsedTime().asSeconds());代码中使用到一些 GLSL 关键字,如:
- varying 定义了一个可变量;
- vec2 和 vec4 是向量类型,分别是二维向量和四维向量;
- gl 前缀的是内置变量,可以通过 GLSL specifications 着色器语言规范文档查询;
OpenGL 扩展会影响 GLSL 功能,和 OpenGL 的扩展不同,要使用 GLSL 扩展必需在着色器程序中显式设置:
#extension extension_name : behavior固定以下几个扩展使用行为方式:
- enable: 启用相应扩展,如果没硬件实现,没提示错误信息。
- require: 启用相应扩展,如果没硬件实现,则出错。
- warn: 启用相应扩展,并提示信息。
- disable: 不使用相应的扩展。
GLSL 也有以下宏定义:
__FILE__着色器文件的序号。__LINE__代码行号。__VERSION__版本号,如 330 表示 3.30。
GLSL 流程控制语句结构有几下这些:
- 条件选择 (if-else, switch-case-default)
- 迭代 (for, while, do-while)
- 跳转 (discard, return, break, continue)
GLSL 的主函数和 C 语言的同名,但是没有传入参数,也不返回值。
函数定义格式参考如下,使用 in/out/inout 来确定参数的数据流向:
void MyFunction(in float inputValue, out int outputValue, inout float inAndOutValue);调用函数时,参数必须使用左值,不能使用表达式:MyFunction(in1, 2+4, out2) 这种是错误用法,不能使用 2 + 4 这种表达式作参数。也不能在一个 unsettable 值上调用,包括着色器输入(全局 in 变量)、uniforms 或 const 限定的值。
GLSL 有大量内置函数,常用的数学函数都,例如:
| Syntax | Description |
|---|---|
| genFType radians(genFType degrees) | Converts degrees to radians, i.e., (π / 180)·degrees. |
| genFType degrees(genFType radians) | Converts radians to degrees, i.e., (180 / π)·radians. |
| genFType sin(genFType angle) | The standard trigonometric sine function. |
| genFType cos(genFType angle) | The standard trigonometric cosine function. |
| genFType tan(genFType angle) | The standard trigonometric tangent. |
GLSL 内置函数大多数所有着色器中通用,部分专用,大概分成三类:
- 暴露硬件功能的函数,着色器无法模拟这些函数,如纹理贴图访问。
- 代表一个简单的操作,如 clamp、mix 等函数,用户编写起来非常简单,但它们非常常见,可能有直接的硬件支持。对于编译器来说,将表达式映射到复杂的汇编指令是一个非常困难的问题。
- 图形硬件加速的操作,三角函数属于这一类。
可以参考 GLM 数学函数库,这个库的实现参考 GLSL 规范,GLM is a header only library,只提供头文件的实现方式,不需要构建。
git clone git@github.com:g-truc/glm.git
预处理器使用的运算符:
| Precedence | Operator class | Operators | Associativity |
|-------------|----------------------------|-----------------|---------------|
| 1 (highest) | parenthetical grouping | ( ) | NA |
| 2 | unary | defined + - ~ ! | Right to Left |
| 3 | multiplicative | * / % | Left to Right |
| 4 | additive | + - | Left to Right |
| 5 | bit-wise shift | << >> | Left to Right |
| 6 | relational | < > <= >= | Left to Right |
| 7 | equality | == != | Left to Right |
| 8 | bit-wise and | & | Left to Right |
| 9 | bit-wise exclusive or | ^ | Left to Right |
| 10 | bit-wise inclusive or | | | Left to Right |
| 11 | logical and | && | Left to Right |
| 12 (lowest) | logical inclusive or | || | Left to Right |
通用运算符:
| Precedence | Operator Class | Operators | Associativity |
|-------------|-----------------------------------------|------------|---------------|
| 1 (highest) | parenthetical grouping | ( ) | NA |
|-------------|-----------------------------------------|------------|---------------|
| 2 | array subscript | [ ] | Left to Right |
| | function call and constructor structure | ( ) | |
| | field or method selector, swizzler | . | |
| | post fix increment and decrement | ++ -- | |
|-------------|-----------------------------------------|------------|---------------|
| 3 | prefix increment and decrement unary | ++ -- | Right to Left |
| | | + - ~ ! | |
|-------------|-----------------------------------------|------------|---------------|
| 4 | multiplicative | * / % | Left to Right |
| 5 | additive | + - | Left to Right |
| 6 | bit-wise shift | << >> | Left to Right |
| 7 | relational | < > <= >= | Left to Right |
| 8 | equality | == != | Left to Right |
| 9 | bit-wise and | & | Left to Right |
| 10 | bit-wise exclusive or | ^ | Left to Right |
| 11 | bit-wise inclusive or | | | Left to Right |
| 12 | logical and | && | Left to Right |
| 13 | logical exclusive or | ^^ | Left to Right |
| 14 | logical inclusive or | || | Left to Right |
| 15 | selection | ? : | Right to Left |
|-------------|-----------------------------------------|------------|---------------|
| 16 | Assignment arithmetic assignments | = | Right to Left |
| | | += -= | |
| | | *= /= | |
| | | %= <<= >>= | |
| | | &= ^= |= | |
|-------------|-----------------------------------------|------------|---------------|
| 17 (lowest) | sequence | , | Left to Righ |
Table 2.1 Basic Data Types in GLSL
| Type | Description |
|---|---|
| float | IEEE 32-bit floating-point value |
| double | IEEE 64-bit floating-point value |
| int | signed two ’ s-complement 32-bit integer value |
| uint | unsigned 32-bit integer value |
| bool | Boolean value |
GLSL 的类型系统:
- Basic types
- 1.1 Scalars
- 1.2 Vectors
- 1.3 Matrices
- 1.4 Opaque types
- 1.4.1 Samplers
- 1.4.2 Images
- 1.4.3 Atomic counters
- Arrays
- 2.1 Opaque arrays
- 2.2 Arrays of arrays
- Structs
其中,有三种不透明类型,表示着色器以某种方式引用的外部对象。不透明变量不像常规类型那样具有一个值,它们只是引用真实数据的标记。因此,它们只能用作函数的参数,由这些函数返回、修改实际引用的数据。
它们有两种方式声明:
- 使用 uniform 声明为全局中变量,包含 Opaque Array 类型;
- 作为 uniform 结构体的成员进行声明;
不透明类型不能作为表达式的部分使用,不可以是 buffer-blacked 接口块,或者 in/out 变量,但可以作为函数的输入参数,以允许作为参数传入。
不透明类型不能是左值,Non-array Opaque 类型只能是和参数的同样类型才能传入函数。
数组化的不透明类型可以使用数组索引和结构体字段选择,通过 .length() 方法。
接口块 Interface Block 是一批变量定义,有名字,等价于结构体,并冠以 input, output, uniform 类型修饰符,或者 buffer 变量。如内置的 out gl_PerVertex { ... } 变量就是用于输出的接口块,叫做 gl_PerVertex 名字。
storage_qualifier block_name
{
<define members here>
} instance_name;原子计数器类型 Atomic Counter 是 GLSL 的一种变量类型 atomic_uint,内存来自 Buffer Object,用于内存的原子操作,可以认为是缓冲区图像变量的一种非常有限的形式。也只能声明为 uniform 或是 in 函数参数。
原子操作可以对一个内存位置的图像数据进行 read/modify/write,并且操作保证是原子的:如果两个着色器对同个内存的图像执行同样的原子操作,只有一个会先执行完毕,然后再轮到下一个。
相比着色器对图像进行 load/store 或使用 Shader Storage Buffer Objects,原子计数器的主要的功能限制是只能使用无符号整数,旧版中还限制增、减量为 1。如果功能满足要求,应该尽量使用它它来替代图像的 Load/Store。
GLSL 中的 Sampler 是变量类型集合,其中的变量必需为 uniform 或者使用函数参数类型。程序中的每个 Sampler 表示某种纹理类型的一个纹理,对应类型的纹理可以被 Sampler 使用。
Table 6.1 Texture Targets and Corresponding Sampler Types
| Target (GL_TEXTURE* | Sampler Type | Dimensionality |
|----------------------|------------------|----------------------|
| 1D | sampler1D | 1D |
| 1D_ARRAY | sampler1DArray | 1D array |
| 2D | sampler2D | 2D |
| 2D_ARRAY | sampler2DArray | 2D array |
| 2D_MULTISAMPLE | sampler2DMS | 2D multisample |
| 2D_MULTISAMPLE_ARRAY | sampler2DMSArray | 2D multisample array |
| 3D | sampler3D | 3D |
| CUBE | samplerCube | cube-map texture |
| ARRAY | samplerCubeArray | cube-map array |
| RECTANGLE | samplerRect | 2D rectangle |
| BUFFER | samplerBuffer | 1D buffer |
上表展示了 GLSL 着色器程序中可以使用的纹理采样类型和对应维度信息,对应的 OpenGL 纹理枚举类型名称相应添加 GL_TEXTURE 前缀。
GLSL Type Modifiers:
- const 标识只读变量,可以是编译时常量,如果在编译时初始化。
- in 数据会输入到颜色器的变量;
- out 数据会从着色器输出的变量;
inoutCopy in and copy out- uniform 数据会从应用程序传递到着色器,并在给定的图元中保持不变,可以理解从 CPU 到 GPU。
- buffer 标记应用程序读写的内存块,它会被着色器程序引用。
- shared 标记变量在本地工作组共享,只在计算着色器时用建立内存共享。
补充一个在 OpenGL 1.3 版本开始标记为 deprecated 的存储修饰 varying,它用来链接顶点着色器与片段着色器的数据插值,相当顶点着色器的 out 变量,和片段着色器的 in 变量。存储的是顶点着色器的输出,同时作为片段着色器的输入。顶点着色器把需要传递给片段着色器的数据存储在一个或多个 varying 变量中,这些变量在片段着色器中需要有相对应的声明且数据类型一致,然后在光栅化过程中进行插值计算。
着色器是各自独立的小程序,每个着色器都有输入和输出,着色器之间可以上下串联,这也是渲染管道的一层含义。GLSL 定义了 in 和 out 关键字专门来实现输入和输出,只要一个输出变量与下一个着色器阶段的输入匹配,它就会传递下去,但在顶点和片段着色器中会有点不同。顶点着色器从顶点数据中直接接收输入,接收的是一种特殊形式的输入,否则就会效率低下。
所以,在渲染管线中,如果从 A 着色器向 B 着色器发送数据,必须在 A 着色器中声明输出变量,并在接收方 B 着色器中声明一个相同的输入变量。当类型和名字都一样的时候,数据就会从上一级着色器的 out 变量流向下一级着色器的 in 变量。
在渲染流水线上,不同的着色器会按顺序进行工作,着色器前后存在数据输入输出,这样所有着色器才能串联起来完成一项完整的渲染工作。
此外,还扩展的指令修饰符,如 require、enabled、disable、warn 等。
注意 uniform 类型修饰符是专用于从应用程序数据传递到着色器的一种方式,它表明变量、接口或者代码块是全局的 Global,意味着 uniform 变量必须在每个着色器程序对象中都是独一无二的,而且它可以被着色器程序的任意着色器在任意阶段访问。第二,无论你把 uniform 值设置成什么,uniform 会一直保存它们的数据,直到它们被重置或更新。
Uniform 代码块可以使用 Layout 修饰符:
- shared 表示 uniform block 在多个着色程序中共享,默认。
- packed 最小化 uniform block 的内存使用,通常会色色色他 shareed 布局。
- std140 使用 GLSL Version 1.40 标准布局。
- std430 使用 GLSL Version 4.30 标准布局。
- row_major 使用 uniform block 中的矩阵在行主序元素共享。
- column_major 使用 uniform block 中的矩阵在列主序元素共享,默认方式。
GLSL 还有两个容器类型向量和矩阵 vectors and matrices。
GLSL 中的向量是一个可以包含有 1、2、3 或者 4 个分量的容器,分量的类型可以是默认基础类型,也可以是下面的形式,n 代表分量的数量:
- vecn 包含 n 个 float 分量的默认向量。
- bvecn 包含 n 个 bool 分量的向量。
- ivecn 包含 n 个 int 分量的向量。
- uvecn 包含 n 个 unsigned int 分量的向量。
- dvecn 包含 n 个 double 分量的向量。
Table 2.3 GLSL Vector and Matrix Types
| Base Type | 2D vec | 3D vec | 4D vec | Matrix Types |
|-----------|--------|--------|--------|--------------|---------|---------|
| float | vec2 | vec3 | vec4 | mat2 | mat3 | mat4 |
| | | | | mat2x2 | mat2x3 | mat2x4 |
| | | | | mat3x2 | mat3x3 | mat3x4 |
| | | | | mat4x2 | mat4x3 | mat4x4 |
|-----------|--------|--------|--------|--------------|---------|---------|
| double | dvec2 | dvec3 | dvec4 | dmat2 | dmat3 | dmat4 |
| | | | | dmat2x2 | dmat2x3 | dmat2x4 |
| | | | | dmat3x2 | dmat3x3 | dmat3x4 |
| | | | | dmat4x2 | dmat4x3 | dmat4x4 |
|-----------|--------|--------|--------|--------------|---------|---------|
| int | ivec2 | ivec3 | ivec4 | - | - | - |
| uint | uvec2 | uvec3 | uvec4 | - | - | - |
| bool | bvec2 | bvec3 | bvec4 | - | - | - |
向量的运算是一种叫做 Swizzling 的灵活方法,可以访问各个分量:
vec4 someVec;
someVec.x + someVec.y;
vec2 someVec2;
vec4 otherVec = someVec2.xyxx;
vec3 thirdVec = otherVec.zyy;
// someVec.xx = vec2(4.0, 4.0); is not allowed.
vec4 someVec3;
someVec4.wzyx = vec4(1.0, 2.0, 3.0, 4.0); // Reverses the order.
someVec4.zx = vec2(3.0, 5.0); // Sets the 3rd component of someVec to 3.0 and the 1st component to 5.0
// in OpenGL 4.2 or ARB_shading_language_420pack
float aFloat; // scalar type variable
vec4 someVec4 = aFloat.xxxx;可以通过 x, y, z, w 访问具体的数据,分别是数据中的第一、二、三、四个分量。可以在赋值号右侧中重复使用某些分量,也可以对顺序进行重新排序,并通过赋值产生新的交换过不同分量的值。
注意,只有四维向量才有四个分量,如果通过 vec3 变量去访问 w 分量就会编译出错。
有三组 Swizzle masks,没有什么功能区别,只是字符不同,是语法糖。但是不能混用,如 .xrs 就不正确:
- xyzw 用于向量;
- rgba 用于颜色;
- stpq 用于纹理坐标;
在 OpenGL 4.2 或 ARB_shading_language_420pack 中,标量也可以使用 Swizzling 语法,它们虽然只有一个分量。
矩阵类型中,每个行就是一个向量,同样适用 Swizzling 方法。
mat3 theMatrix;
theMatrix[1] = vec3(3.0, 3.0, 3.0); // Sets the second column to all 3.0s
theMatrix[2][0] = 16.0; // Sets the first entry of the third column to 16.0.
// However, the result of the first array accessor is a vector, so you can swizzle that:
mat3 theMatrix;
theMatrix[1].yzx = vec3(3.0, 1.0, 2.0);着色器中使用的像 gl_Position 这样以 gl 开头的都是内置常量或变量,可以参考最新的 The OpenGL® Shading Language, v4.60.7 - Chapter 7. Built-In Variables。
顶点、几何着色器是两种最基本的着色器,在它们的处理器之间的固定功能中有许多内置的变量,着色器利用这些固定 OpenGL 功能提供的内置变量进行数据通信。
以下内容根据 GLSL 3.3/4.5 文档进行整理,需要了解的内容包括:
- Built-in Variables
- Vertex and Geometry Shader Special Variables
- Compatibility Profile Vertex and Geometry Shader Special Variables
- Fragment Shader Special Variables
- Compatibility Profile Vertex Shader Built-In Inputs
- Built-In Constants
- Compatibility Profile Built-In Constants
- Built-In Uniform State
- Compatibility Profile State
- Compatibility Profile Vertex and Fragment Interface
根据不同阶段使用着色器,可用内置变量也不相同。
在顶点着色器中,相应的内置变量如下:
// Vertex Shaders have the following built-in input variables.
in int gl_VertexID; // only present when not targeting Vulkan
in int gl_InstanceID; // only present when not targeting Vulkan
in int gl_VertexIndex; // only present when targeting Vulkan
in int gl_InstanceIndex; // only present when targeting Vulkan
in int gl_DrawID;
in int gl_BaseVertex;
in int gl_BaseInstance;
// Vertex Shaders have the following predefined outputs.
out gl_PerVertex {
vec4 gl_Position;
float gl_PointSize;
float gl_ClipDistance[];
float gl_CullDistance[];
};可以看到 gl_PerVertex 代码块中定义了四维向量 gl_Position,是每一个输入顶点自动绑定的内置变量。
如果顶点着色器可执行文件未写入 gl_Position,则在顶点处理阶段之后,其值未定义;如果几何体可执行文件调用 EmitVertex(),但自上一次执行此函数以来未写入 gl_Position 或根本未写入,则其值在几何体处理后未定义。
变量 gl_PointSize 用于定义着色器写入要光栅化的点的大小,以像素为单位。如果未写入 gl_PointSize,则其值在后续管道阶段中未定义。
变量 gl_VertexID 保存顶点的整数索引,如 OpenGL 图形系统规范中的“着色器输入”所定义。虽然变量 gl_VertexID 始终存在,但它的值并不总是有定义。
变量 gl_InstanceID 保存 Draw Call 调用中当前图元的整数索引,参考 OpenGL 图形系统规范 OpenGL Graphics System Specification -> Vertex Shaders。如果当前图元不是来自 Draw Call 实例,gl_VertexID 的值为 0。
在片段着色器中,内置变量声明如下:
in gl_PerVertex {
vec4 gl_Position;
float gl_PointSize;
float gl_ClipDistance[];
float gl_CullDistance[];
} gl_in[];
in int gl_PrimitiveIDIn;
in int gl_InvocationID;
out gl_PerVertex {
vec4 gl_Position;
float gl_PointSize;
float gl_ClipDistance[];
float gl_CullDistance[];
};
out int gl_PrimitiveID;
out int gl_Layer;
out int gl_ViewportIndex;在几何着色器中,内置变量声明如下:
// Geometry Shaders provide the following built-in input variables:
in gl_PerVertex
{
vec4 gl_Position;
float gl_PointSize;
float gl_ClipDistance[];
} gl_in[];
// Geometry Shaders have the following built-in outputs.
out gl_PerVertex
{
vec4 gl_Position;
float gl_PointSize;
float gl_ClipDistance[];
};在新版本中,会有些更新的内置变量,同时一些旧的内置变量会被标记为过时:
// OpenGL 4.0 and above define additional system-generated input values:
in int gl_SampleID;
in vec2 gl_SamplePosition;
in int gl_SampleMaskIn[];
// Compute Shaders have the following built-in input variables.
// work group dimensions
in uvec3 gl_NumWorkGroups;
const uvec3 gl_WorkGroupSize; // GLSL ≥ 4.30
// work group and invocation IDs
in uvec3 gl_WorkGroupID;
in uvec3 gl_LocalInvocationID;
// derived variables
in uvec3 gl_GlobalInvocationID;
in uint gl_LocalInvocationIndex;常用的这些内置变量如下:
- gl_ModelViewProjectionMatrix 表示是模型、视图、投射变换矩阵的复合,计算顶点在屏幕空间的位置。
- gl_TextureMatrix 纹理变换矩阵;
- gl_MultiTexCoord0 输入的顶点纹理坐标;
- gl_Vertex 顶点着色器中的输入顶点;
- gl_FragColor 片断着色器输出的像素颜色;
根据 GLSL 1.30 规范文档,这些内置变量标注为过期,取而代之的是采用 uniform 的形式向着色器传递矩阵,当然还可以以 compatible 方式继续使用。但是,直到 GLSL 1.40 还是可以在默认状态下使用这些兼容模式的内置变量,除非在着色器语言中指定版本为 #version 150,这样会出现许多符号未定义的错误。
Failed to compile vertex shader:
ERROR: 0:6: 'gl_ModelViewProjectionMatrix' : undeclared identifier
ERROR: 0:6: 'gl_Vertex' : undeclared identifier
ERROR: 0:9: 'gl_TexCoord' : undeclared identifier
ERROR: 0:9: 'gl_TextureMatrix' : undeclared identifier
ERROR: 0:9: 'gl_MultiTexCoord0' : undeclared identifier
ERROR: 0:12: 'gl_FrontColor' : undeclared identifier
ERROR: 0:12: 'gl_Color' : undeclared identifier根据规范文档说明,这些内置变量都属性 Compatibility Profile,并不属于最新的 Core Profile:
// 7.4.1. Compatibility Profile State compatibility profile only
uniform mat4 gl_ModelViewMatrix;
uniform mat4 gl_ProjectionMatrix;
uniform mat4 gl_ModelViewProjectionMatrix;
uniform mat4 gl_TextureMatrix[gl_MaxTextureCoords];
// Compatibility profile: fragment shader output variables
out vec4 gl_FragColor;
out vec4 gl_FragData[gl_MaxDrawBuffers];
// Compatibility Profile Vertex Shader Built-In Input
in vec4 gl_Color;
in vec4 gl_SecondaryColor;
in vec3 gl_Normal;
in vec4 gl_Vertex;
in vec4 gl_MultiTexCoord0;
in vec4 gl_MultiTexCoord1;
in vec4 gl_MultiTexCoord2;
in vec4 gl_MultiTexCoord3;
in vec4 gl_MultiTexCoord4;
in vec4 gl_MultiTexCoord5;
in vec4 gl_MultiTexCoord6;
in vec4 gl_MultiTexCoord7;
in float gl_FogCoord;以下是 GLSLangSpec.3.30 规范文档目录罗列的 Built-in Functions 原型,基本都是泛型函数,genType 就是表示泛型,以下省略掉相应 template 声明部分:
// 8.1 Angle and Trigonometry Functions
namespace trigonometric{
genType radians(genType const & degrees);
genType degrees(genType const & radians);
genType sin(genType const & angle);
genType cos(genType const & angle);
genType tan(genType const & angle);
genType asin(genType const & x);
genType acos(genType const & x);
genType atan(genType const & y, genType const & x);
genType atan(genType const & y_over_x);
genType sinh(genType const & angle);
genType cosh(genType const & angle);
genType tanh(genType const & angle);
genType asinh(genType const & x);
genType acosh(genType const & x);
genType atanh(genType const & x);
}
// 8.2 Exponential Functions
namespace exponential{
genType pow(genType const & x, genType const & y);
genType exp(genType const & x);
genType log(genType const & x);
genType exp2(genType const & x);
genType log2(genType const & x);
genType sqrt(genType const & x);
genType inversesqrt(genType const & x);
}
// 8.3 Common Functions
namespace common{
genFIType abs(genFIType const & x);
genFIType sign(genFIType const & x);
genType floor(genType const & x);
genType trunc(genType const & x);
genType round(genType const & x);
genType roundEven(genType const & x);
genType ceil(genType const & x);
genType fract(genType const & x);
genType mod(genType const & x, genType const & y);
genType mod(genType const & x, typename genType::value_type const & y);
genType modf(genType const & x, genType & i);
genType min(genType const & x, genType const & y);
genType min(genType const & x, typename genType::value_type const & y);
genType max(genType const & x, genType const & y);
genType max(genType const & x, typename genType::value_type const & y);
genType clamp(genType const & x, genType const & minVal, genType const & maxVal);
genType clamp(genType const & x, typename genType::value_type const & minVal,
typename genType::value_type const & maxVal);
genTypeT mix(genTypeT const & x, genTypeT const & y, genTypeU const & a);
genType step(genType const & edge, genType const & x);
genType step(typename genType::value_type const & edge, genType const & x);
genType smoothstep(genType const & edge0, genType const & edge1, genType const & x);
genType smoothstep(typename genType::value_type const & edge0,
typename genType::value_type const & edge1, genType const & x);
typename genType::bool_type isnan(genType const & x);
typename genType::bool_type isinf(genType const & x);
genIType floatBitsToInt(genType const & value);
genUType floatBitsToUint(genType const & value);
genType intBitsToFloat(genIType const & value);
genType uintBitsToFloat(genUType const & value);
genType fma(genType const & a, genType const & b, genType const & c);
genType frexp(genType const & x, genIType & exp);
genType ldexp(genType const & x, genIType const & exp);
}
// 8.4 Geometric Functions
namespace geometric{
typename genType::value_type length(genType const & x);
typename genType::value_type distance(genType const & p0, genType const & p1);
typename genType::value_type dot(genType const & x, genType const & y);
detail::tvec3<T> cross(detail::tvec3<T> const & x, detail::tvec3<T> const & y);
genType normalize(genType const & x);
genType faceforward(genType const & N, genType const & I, genType const & Nref);
genType reflect(genType const & I, genType const & N);
genType refract(genType const & I, genType const & N, typename genType::value_type const & eta);
}
// 8.5 Matrix Functions
namespace matrix{
matType matrixCompMult(matType const & x, matType const & y);
matType outerProduct(vecType const & c, vecType const & r);
typename matType::transpose_type transpose(matType const & x);
typename detail::tmat2x2<T>::value_type determinant(detail::tmat2x2<T> const & m);
typename detail::tmat3x3<T>::value_type determinant(detail::tmat3x3<T> const & m);
typename detail::tmat4x4<T>::value_type determinant(detail::tmat4x4<T> const & m);
detail::tmat2x2<T> inverse(detail::tmat2x2<T> const & m);
detail::tmat3x3<T> inverse(detail::tmat3x3<T> const & m);
detail::tmat4x4<T> inverse(detail::tmat4x4<T> const & m);
}
// 8.6 Vector Relational Functions
namespace vector_relational{
typename vecType<T>::bool_type lessThan( vecType<T> const & x, vecType<T> const & y )
typename vecType<T>::bool_type lessThanEqual( vecType<T> const & x, vecType<T> const & y )
typename vecType<T>::bool_type greaterThan( vecType<T> const & x, vecType<T> const & y )
typename vecType<T>::bool_type greaterThanEqual( vecType<T> const & x, vecType<T> const & y )
typename vecType<T>::bool_type equal( vecType<T> const & x, vecType<T> const & y )
typename vecType<T>::bool_type notEqual( vecType<T> const & x, vecType<T> const & y )
bool any(vecType<bool> const & v);
bool all(vecType<bool> const & v);
vecType<bool> not_(vecType<bool> const & v);
}
// 8.7 Texture Lookup Functions
// Texture Query Functions
int textureSize( gsampler1D sampler, int lod)
ivec2 textureSize( gsampler2D sampler, int lod)
ivec3 textureSize( gsampler3D sampler, int lod)
ivec2 textureSize( gsamplerCube sampler, int lod)
int textureSize( sampler1DShadow sampler, int lod)
ivec2 textureSize( sampler2DShadow sampler, int lod)
ivec2 textureSize( samplerCubeShadow sampler, int lod)
ivec3 textureSize( samplerCubeArray sampler, int lod)
ivec3 textureSize( samplerCubeArrayShadow sampler, int lod)
ivec2 textureSize( gsampler2DRect sampler)
ivec2 textureSize( sampler2DRectShadow sampler)
ivec2 textureSize( gsampler1DArray sampler, int lod)
ivec3 textureSize( gsampler2DArray sampler, int lod)
ivec2 textureSize( sampler1DArrayShadow sampler, int lod)
ivec3 textureSize( sampler2DArrayShadow sampler, int lod)
int textureSize( gsamplerBuffer sampler)
ivec2 textureSize( gsampler2DMS sampler)
ivec2 textureSize( gsampler2DMSArray sampler)
vec2 textureQueryLod(gsampler1D sampler, float P)
vec2 textureQueryLod(gsampler2D sampler, vec2 P)
vec2 textureQueryLod(gsampler3D sampler, vec3 P)
vec2 textureQueryLod(gsamplerCube sampler, vec3 P)
vec2 textureQueryLod(gsampler1DArray sampler, float P)
vec2 textureQueryLod(gsampler2DArray sampler, vec2 P)
vec2 textureQueryLod(gsamplerCubeArray sampler, vec3 P)
vec2 textureQueryLod(sampler1DShadow sampler, float P)
vec2 textureQueryLod(sampler2DShadow sampler, vec2 P)
vec2 textureQueryLod(samplerCubeShadow sampler, vec3 P)
vec2 textureQueryLod(sampler1DArrayShadow sampler, float P)
vec2 textureQueryLod(sampler2DArrayShadow sampler, vec2 P)
vec2 textureQueryLod(samplerCubeArrayShadow sampler, vec3 P)
// Texture Lookup Functions
gvec4 texture( gsampler1D sampler, float P [, float bias] )
gvec4 texture( gsampler2D sampler, vec2 P [, float bias] )
gvec4 texture( gsampler3D sampler, vec3 P [, float bias] )
gvec4 texture( gsamplerCube sampler, vec3 P [, float bias] )
float texture( sampler1DShadow sampler, vec3 P [, float bias] )
float texture( sampler2DShadow sampler, vec3 P [, float bias] )
float texture( samplerCubeShadow sampler, vec4 P [, float bias] )
gvec4 texture( gsampler1DArray sampler, vec2 P [, float bias] )
gvec4 texture( gsampler2DArray sampler, vec3 P [, float bias] )
float texture( sampler1DArrayShadow sampler, vec3 P [, float bias] )
float texture( sampler2DArrayShadow sampler, vec4 P)
gvec4 texture( gsampler2DRect sampler, vec2 P)
float texture( sampler2DRectShadow sampler, vec3 P)
float textureProj( sampler1DShadow sampler, vec4 P [, float bias] )
float textureLod( sampler1DShadow sampler, vec3 P, float lod)
float textureOffset( sampler2DRectShadow sampler, vec3 P, ivec2 offset )
gvec4 texelFetch( gsampler1D sampler, int P, int lod)
float textureProjOffset( sampler2DRectShadow sampler, vec4 P, ivec2 offset )
float textureLodOffset( sampler1DShadow sampler, vec3 P, float lod, int offset)
float textureProjLod( sampler1DShadow sampler, vec4 P, float lod)
float textureProjLodOffset( sampler1DShadow sampler, vec4 P, float lod, int offset)
float textureGrad( sampler2DRectShadow sampler, vec3 P, vec2 dPdx, vec2 dPdy)
float textureGradOffset( sampler2DRectShadow sampler, vec3 P, vec2 dPdx, vec2 dPdy, ivec2 offset)
float textureProjGrad( sampler2DRectShadow sampler, vec4 P, vec2 dPdx, vec2 dPdy)
float textureProjGradOffset( sampler2DRectShadow sampler,
vec4 P,
vec2 dPdx, vec2 dPdy, ivec2 offset)
// Texture Gather Functions
vec4 textureGather(sampler2DShadow sampler, vec2 P, float refZ)
vec4 textureGatherOffset(sampler2DShadow sampler, vec2 P, float refZ, ivec2 offset)
// 8.8 Fragment Processing Functions
// Derivative Functions
genType dFdx( genType p);
genType dFdy( genType p);
genType dFdxFine( genType p);
genType dFdyFine( genType p);
genType dFdxCoarse( genType p);
genType dFdyCoarse( genType p);
genType fwidth( genType p);// Returns abs( dFdx( p)) + abs( dFdy( p)).
genType fwidthFine( genType p);// Returns abs(dFdxFine(p)) + abs(dFdyFine(p)).
genType fwidthCoarse( genType p);
genType dFdxCoarse( genType p);
genType dFdyCoarse( genType p);
genType fwidth( genType p);// Returns abs (dFdx (p)) + abs (dFdy (p)).
genType fwidthFine( genType p);// Returns abs(dFdxFine(p)) + abs(dFdyFine(p)).
genType fwidthCoarse( genType p);// Returns abs(dFdxCoarse(p)) + abs(dFdyCoarse(p)).
// Interpolation Functions
float interpolateAtCentroid( float interpolant);
float interpolateAtSample( float interpolant, int sample);
float interpolateAtOffset( float interpolant, vec2 offset);
vec2 interpolateAtCentroid( vec2 interpolant)
vec3 interpolateAtCentroid( vec3 interpolant)
vec4 interpolateAtCentroid( vec4 interpolant)
vec2 interpolateAtSample( vec2 interpolant, int sample)
vec3 interpolateAtSample( vec3 interpolant, int sample)
vec4 interpolateAtSample( vec4 interpolant, int sample)
vec2 interpolateAtOffset( vec2 interpolant, vec2 offset)
vec3 interpolateAtOffset( vec3 interpolant, vec2 offset)
vec4 interpolateAtOffset( vec4 interpolant, vec2 offset)
// 8.9 Noise Functions
float noise1( genType x);// Returns a 1D noise value based on the input value x.
vec2 noise2( genType x);// Returns a 2D noise value based on the input value x.
vec3 noise3( genType x);// Returns a 3D noise value based on the input value x.
vec4 noise4( genType x);// Returns a 4D noise value based on the input value x.
// 8.10 Geometry Shader Functions
void EmitStreamVertex (int stream);
void EndStreamPrimitive (int stream);
void EmitVertex ();
void EndPrimitive ();纹理函数分为以下几种:
- Texture Query Functions
- Texel Lookup Functions
- Texture Gather Functions
虽然,在 GLSL 4.0 中声明废弃了大量名字包含 1D/2D/3D/Cube 字样的纹理函数,如 texture1D。但是在后续版本中,还是将它们归为 Compatibility Profile Texture Functions。
纹理查询函数 textureSize 查询指定精细级别的纹理尺寸,textureQueryLod 只用于片段着色器,获取 LOD - Level of Detail 信息。
片段着色器处理函数有两类,偏导函数(头皮发麻)和插值函数:
- Derivative Functions
- Interpolation Functions
导数可能在计算上很消耗硬件资源,或在数值上不稳定。因此,OpenGL 实现可以通过使用快速但不完全精确的导数计算来近似真实导数。在非均匀控制流中未定义导数。使用 forward/backward differencing 指定导数的预期行为。
在 GLSL 4.4 版本后弃用了 noise1, noise2, noise3, noise4 等噪点函数,它们只返回 0.0 值或向量。与之前的版本一样,它们在语义上不被认为是编译时常量表达式。
GLSLangSpec.4.60 比旧版本规范新增了大量内置函数,以下是各个规范文档的内置函数目录部分对比,前面两个版本分别对应 OpenGL 2.0 和 3.0:
| 1.1 | 1.3 | 3.3 | 4.0 |4.5 | 4.6 | Contents |
|-----|-----|-----|-----|----|-----|-----------------------------------------------|
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 8.1. Angle and Trigonometry Functions |
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 8.2. Exponential Functions |
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 8.3. Common Functions |
| ❌ | ❌ | ❌ | ✔ | ✔ | ✔ | 8.4. Floating-Point Pack and Unpack Functions |
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 8.5. Geometric Functions |
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 8.6. Matrix Functions |
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 8.7. Vector Relational Functions |
| ❌ | ❌ | ❌ | ✔ | ✔ | ✔ | 8.8. Integer Functions |
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 8.9. Texture Functions |
| ❌ | ❌ | ❌ | ❌ | ✔ | ✔ | 8.10. Atomic Counter Functions |
| ❌ | ❌ | ❌ | ❌ | ✔ | ✔ | 8.11. Atomic Memory Functions |
| ❌ | ❌ | ❌ | ❌ | ✔ | ✔ | 8.12. Image Functions |
| ❌ | ❌ | ✔ | ✔ | ✔ | ✔ | 8.13. Geometry Shader Functions |
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 8.14. Fragment Processing Functions |
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 8.15. Noise Functions |
| ❌ | ❌ | ❌ | ✔ | ✔ | ✔ | 8.16. Shader Invocation Control Functions |
| ❌ | ❌ | ❌ | ❌ | ✔ | ✔ | 8.17. Shader Memory Control Functions |
| ❌ | ❌ | ❌ | ❌ | ❌ | ✔ | 8.18. Subpass-Input Functions |
| ❌ | ❌ | ❌ | ❌ | ❌ | ✔ | 8.19. Shader Invocation Group Functions |
- Vulkan® SDK
- Vulkan® Tutorials
- Vulkan® Specification
- Khronos Vulkan Registry
- Vulkan Guide
- Vulkan® Memory Allocator
- Vulkan Tutorial
- Ray Tracing in One Weekend
- NVIDIA Vulkan Ray Tracing Tutorial
- Vulkan in 30 minutes
- Brief guide to Vulkan layers
- Frameworks and Helper Libraries
- API without Secrets: Introduction to Vulkan
- SDL version 2.0.20 (stable)
- Metal by Tutorials: Beginning Game Engine Development with Metal
Vulkan Docs, Guide & Code Samples ...:
git clone git@github.com:KhronosGroup/Vulkan-Docs.git git clone git@github.com:KhronosGroup/Vulkan-Guide.git git clone git@github.com:KhronosGroup/Vulkan-Samples.git git clone git@github.com:KhronosGroup/Vulkan-Loader.git
教程示范代码:
git clone git@github.com:LunarG/VulkanSamples.git git clone git@github.com:gametechdev/IntroductionToVulkan.git git clone git@github.com:SaschaWillems/Vulkan.git git clone git@github.com:Overv/VulkanTutorial.git
VMA 内存分配器、图形库及 GML 数学函数库等等:
git clone git@github.com:GPUOpen-LibrariesAndSDKs/VulkanMemoryAllocator.git git clone git@github.com:glfw/glfw.git git clone git@github.com:g-truc/glm.git git clone git@github.com:ocornut/imgui.git git clone git@github.com:bkaradzic/bgfx.git git clone git@github.com:SFML/SFML.git git clone git@github.com:libsdl-org/SDL.git
DOOM 3,Quake3 等开源射击类 3D 游戏引擎源码:
git clone git@github.com:DustinHLand/vkDOOM3.git git clone git@github.com:Novum/vkQuake.git
Vulkan 是由 Khronos 集团开发的高级图形 API,作为 OpenGL 的接棒者,它比其他图形 API,如 Direct3D,要求驱动程序从执行高级 API 切换到到适合硬件的必要转换。
高级 API 设计目的是让开发人员不必管理图形硬件更复杂的细节,但是随着图形 API 的不断发展,它们慢慢地将越来越多的低级硬件功能直接暴露给程序员。程序员要求对硬件进行较低级别的访问,这种需求牺牲掉高级 API 的易用性和安全性为代价,反过来说就是易用性代价是开销较高,性能较低。
Vulkan 旨在避免在高级 API 中的高开销,因此,在构建 Vulkan 应用程序时需要注意更多硬件细节。但这允许程序员更有效地管理应用程序资源和 GPU 硬件,这是需要程序员对应用程序的资源使用模式有更多的了解,因此不必做出其他 API 被迫做出的代价高昂的假设。
此外,Vulkan 还致力于成为比其他图形 API 更具跨平台性,不仅针对高端系统,还针对低端移动设备。
本质上,Vulkan 与 OpenGL 都是图形库规范,都是描述渲染管线的一套系统,但新生的 Vulkan 不需要负担 OpenGL 中所特有的历史遗产。所以,从设计开始,Vulkan 架构就以渲染管线精细化操作为目标:

Vulkan API 调用的几种方式:
- 直接加载实现了 Vulkan API 的驱动程序动态链接库,获取相应的函数指针;
- 通过 Vulkan SDK 链接到提供 Vulkan Runtime (Vulkan Loader) 的静态链接库;
- 通过 Vulkan SDK 运行时动态加载器并获取函数指针;
第一种方法不建议使用,因为驱动程序会经常更新,这会导致兼容性问题。第三种方法很像在使用 OpenGL,通过基本的接口函数 wglGetProcAddress() 或 Windows 系统调用 GetProcAddress(),Linux 系统调用 dlsym() 动态获取函数指针,通常会借助 GLEW 或 GL3W 加载器实现这些基本加载功能。
以下示范如何加载 Vulkan API,在不同的系统中,Vulkan 动态链接库名称有些许差别,代码摘自 API without Secrets:
#if defined(VK_USE_PLATFORM_WIN32_KHR)
VulkanLibrary = LoadLibrary( "vulkan-1.dll" );
#elif defined(VK_USE_PLATFORM_XCB_KHR) || defined(VK_USE_PLATFORM_XLIB_KHR)
VulkanLibrary = dlopen( "libvulkan.so", RTLD_NOW );
#endif
if ( VulkanLibrary == nullptr ) {
std::cout << "Could not load Vulkan library!" << std::endl;
return false;
}
// 1. Tutorial01.cpp, function LoadVulkanLibrary()加载动态链接库返回的 VulkanLibrary 变量在 Windows 系统表示为一个 HMODULE 类型,也就是 Linux 系统下的 void* 指针。
Vulkan 作为一个分层化的 API,最底层是 Vulkan 核心层,由规范文档定义。应用程序可以按需要添加更多的层,如 debugging, validation 或用于其它目的层。
核心层假设应用程序正确使用 API。除非规范中另有说明,否则对于不正确使用 API 的应用程序,核心层的行为是未定义的,可能引起程序异常终止。
但是,驱动实现必须确保应用程序的错误使用不会影响操作系统、Vulkan 实现或系统中其他 Vulkan 客户端应用程序的完整性。特别是,对于任何内存分配,Vulkan 实现都不能违反操作系统对一个进程的内存是否对另一个进程可见的任何保证。Vulkan 实现只需要在操作系统提供的安全性或完整性保证之内即可,除非应用程序使用特定功能或扩展明确指示需要额外的安全性或完整性保证。
Vulkan 的一个设计原则就是高效地构建并提交命令缓存,使错误及状态验证最小化,这就导致 Vulkan 的错误机制和 OpenGL 完全不同。
Vulkan 中没有等效的 glGetError(),这是主要优点之一,驱动程序的实现上不会浪费时间检查有效输入。在 OpenGL 中,实现必须始终检查有效使用情况,这会增加明显的开销。
尽管通过使用层可以实现更严格的验证,但验证层会专门验证 API 使用的正确性。开发应用程序时应启用验证层,以帮助捕获和消除错误。一旦通过验证,后续发布的应用程序默认情况下就不再启用验证层以提升效率。
规范文档中,在每个功能和结构之后将列出有效用途。例如,在 VkBindImageMemory() 中进行 VUID 检查看是否存在无效的 VkImage,则规范中的有效用法可在函数介绍后面下找到。
一个 VUID - Valid Usage ID 是一个有效用法的唯一标识,通过它可以在规范文档中快速定位到相关信息。
例如,以下这个 VUID 指示 vkBindImageMemory 函数接收的参数 memoryOffset 必需小于内存大小:
VUID-vkBindImageMemory-memoryOffset-01046
memoryOffset must be less than the size of memory
在 HTML 版本的规范文档中,就可以直接使用 vkspec.html#VUID-vkBindImageMemory-memoryOffset-01046 进行定位,浏览器就会自动跳转到对应的 VUID 内容中。但是,目前 Vulkan 1.3 带完整扩展的规范文档已经有接近 20MB,浏览器打开它需要超过 500MB 的内存。
由于 Vulkan 不进行错误检测,因此在开发过程中启用 Validation Layers 就非常必要。但是,应用程序也不应该随应用程序发行一起交付验证层,因为它们会显著降低性能,并且是为开发阶段设计的。
以下示范分解一个 Validation Error Message:
Validation Error: [ VUID-vkBindBufferMemory-memory-parameter ] Object 0: handle =
0x20c8650, type = VK_OBJECT_TYPE_INSTANCE; | MessageID = 0xe9199965 | Invalid
VkDeviceMemory Object 0x60000000006. The Vulkan spec states: memory must be a valid
VkDeviceMemory handle (https://www.khronos.org/registry/vulkan/specs/1.1-extensions/
html/vkspec.html#VUID-vkBindBufferMemory-memory-parameter)
本例显示了触发隐式有效用法的情况,注意 VUID 的末尾不会有数字。
- 首先是 VUID-vkBindBufferMemory-memory-parameter,消息末尾还有相应的链接;
- 然后还有 The Vulkan spec states 陈述了规范中相应的信息;
- 还有 VK_OBJECT_TYPE_INSTANCE 表示一个 VkObjectType 的类型;
- Invalid VkDeviceMemory Object 0x60000000006 这部分是调度句柄,用于提示哪个 VkDeviceMemory 句柄产生错误。
第二个是例子是 Explicit Valid Usage:
Validation Error: [ VUID-vkBindImageMemory-image-01044 ] Object 0: handle =
0x90000000009, name = myTextureMemory, type = VK_OBJECT_TYPE_DEVICE_MEMORY; Object 1:
handle = 0x70000000007, type = VK_OBJECT_TYPE_IMAGE; Object 2: handle = 0x90000000006,
name = myIconMemory, type = VK_OBJECT_TYPE_DEVICE_MEMORY; | MessageID = 0x6f3eac96 |
In vkBindImageMemory(), attempting to bind VkDeviceMemory 0x90000000009[myTextureMemory]
to VkImage 0x70000000007[] which has already been bound to VkDeviceMemory
0x90000000006[myIconMemory]. The Vulkan spec states: image must not already be
backed by a memory object (https://www.khronos.org/registry/vulkan/specs/1.1-extensions/
html/vkspec.html#VUID-vkBindImageMemory-image-01044)
这个例子是 VkImage 尝试绑定到两个不同的 VkDeviceMemory 对象产生的错误信息。
与前一个示例大致相同,只是附加到不同的对象名称(myTextureMemory)。这是使用 VK_EXT_debug_util 扩展完成的。请注意,在不支持这个扩展的旧设备上,可能需要使用 VK_EXT_debug_report 的旧方法。
这个错误产生和三个对象有关系:
- Object 0 是 VkDeviceMemory 对象,变量名字为 myTextureMemory;
- Object 1 是 VkImage 对象,无变量名字;
- Object 2 是 VkDeviceMemory 对象,变量名字为 myIconMemory;
通过 vkBindImageMemory() 函数名可以很容易看到, 尝试绑定 VkDeviceMemory 设备内存 myTextureMemory 到已经绑定 myIconMemory 的图像上。
对于开发者,理解 Vulkan 的组织结构,要掌握一些非常重要的基础概念。Vulkan Instance 和 Device,可以将 Vulkan 实例理解为 OpenGL 上下文类似的东西。在一个应用程序中可以创建多个实例,这些实例之间相互独立,互不干扰,实例通过 Driver 调用的具体设备。每个 Device 暴露了一个或多个任务队列,它保存着应用程序调用的命令操作。
在 Vulkan API 结构中,可以将许多对象、函数、扩展及其它功能行为分成两组:
- Instance-specific
- Device-specific
Vulkan Instance 使用 VkInstance 类型表达,这是提供当前 Vulkan 系统信息及函数的高级抽象类型。
实例对象 Instance Object 直接相关的有以下这些类型:
- VkInstance
- VkPhysicalDevice
- VkPhysicalDeviceGroup
实例函数 Instance Functions 是一类接收 Vulkan 实例对象为参数,或者没有对象作为参数的函数,如:
- vkEnumerateInstanceExtensionProperties()
- vkEnumeratePhysicalDevices()
- vkCreateInstance()
- vkDestroyInstance()
应用程序可以通过 Vulkan 加载程序的头直接链接到所有核心实例函数。或者,使用 vkGetInstanceProcAddr() 查询函数指针,查询所有核心入口点之外的任何实例或设备入口点。如果通过 VkInstance 调用它,则返回的任何函数指针都特定用于该 VkInstance 以及由此创建的其他对象。
实例扩展 Instance Extensions 类似函数一样基于其提供的函数类型进行关联,因为扩展也分成实例扩展、设备扩展两种。
一个 Vulkan 设备使用 VkDevice 类型表达,它代表用户系统中一个物理设备VkPhysicalDevice的逻辑标识,用来关联相应的函数调用。
各设备对象直接关联的有如下类型:
- VkDevice
- VkQueue
- VkCommandBuffer
设备函数 Device Functions 是一类执行关联设备操作的函数,首个参数就是设备,或者设备的子对象,有大量设备相关的函数,如:
- vkQueueSubmit()
- vkBeginCommandBuffer()
- vkCreateEvent()
设置函数指针可以通过 vkGetInstanceProcAddr() or vkGetDeviceProcAddr() 获得,通过前者获取到的设备函数会在调用链中内置额外的函数调用,这会略微降低性能。所以,一般使用前者查询实例扩展函数,使用后者获取设备关联的函数,以针对特定设备优化调用链,但返回的函数指针将仅适用于查询它们时使用的设备。
一个基本的 Vulkan 应用程序结构及创建步骤如下:
+=============+ +===============+ +=========+ +=========+ +========+
| Application | => | Vulkan Loader | => | Layer 1 | ... | Layer N | => | Driver |
+=============+ +===============+ +=========+ +=========+ +========+
Vulkan 加载器的位置非常核心,它的上层是应用程序,它管理着各种 Layer 的加载或配置,并联接应用程序与驱动。每个驱动可以控制任意个实现了 Vulkan 接口的物理设备,驱动器将 Vulkan 接口转换成 GPU 图形硬件的 API 调用,如 MoltenVK。如果只是调用通过 CPU 模拟的设备,如 SwiftShader 或 LavaPipe。
Vulkan 加载器的作用及设计目标:
- 在用户系统上提供一个或多个支持 Vulkan 的驱动程序,而不会相互干扰。
- 加载支持的 Vulkan 层,可由应用程序、开发人员或标准系统设置启用的可选模块。
- 将加载器的开销保持在尽可能低的水平。
上面这个基本的程序流程隐含了两种调用链:
- 从应用程序到所有驱动的调用链称为 Instance Call Chain,应用程序创建 Vulkan 实例来进行操作;
- 从应用程序到具体设备的这一个调用链称为 Device Call Chain,所以这个过程要简单些;
Vulkan 使用一个 Dispatchable 对象模型来控制 API 操作范围,可派发对象下面包装了一个结构体指针,指向加载程序维护的调度表,这个表包含指向适用于该对象的 Vulkan 函数指针。
Vulkan 加载器管理着两种调度表:
- Instance Dispatch Table,在调用 vkCreateInstance() 期间创建;
- Device Dispatch Table,在调用 vkCreateDevice() 期间创建;
应用程序和系统指定要加载的层后,Vulkan 加载器初始化指定的层,并为每个 Vulkan 函数创建调用链,调度表中的条目都会指向这个调用链的第一个对象。然后,为加载器创建的每个 VkinInstance 构建实例调用链,并为其创建的每个 VkDevice 构建设备调用链。
当应用程序调用 Vulkan 函数时,这通常会首先命中加载程序中一些小而简单的 Trampoline 函数,这些蹦床函数结构如下,可以跳转到给定对象的相应调度表条目。此外,对于实例调用链中的函数,加载器还会调用一个额外的 Terminator 函数,会在所有启用的层执行之后调用,以便将适当的信息打包给所有可用的驱动程序。这两个部分并未在前面的 Vulkan 程序结构简图上表现。
typedef struct _trampoline_data {
void(*callback)(struct _trampoline_data*);
void* parameters;
} trampoline_data;
void trampoline(trampoline_data* data) {
while(data->callback != NULL)
data->callback(data);
}设备分组 Device Groups 是一种将同一供应商多个物理设备表示为单个逻辑设备的方法。例如,如果一个应用程序在一个系统中有两个相同的 GPU,由供应商提供的桥接接口连接,一种方法是在 Vulkan 中创建两个逻辑设备。这里的问题是,在两个 VkDevice 对象之间可以共享和同步的内容存在一些限制,在某些情况下,应用程序可能希望在两个 GPU 之间组合内存。应用程序可以创建单个 VkDevice 的“子设备”,设备组就是为这个用例设计的。对于设备组,VkCommandBuffers 和 VkQueue 等对象不会绑定到单个“子设备”,而是由驱动程序管理在哪个物理设备上运行。设备组的另一个用途是另一种帧呈现系统,其中每个帧由不同的“子设备”显示。
Vulkan 的 API 已经精细到图形硬件的内存管理上,所以会有 Physical Device Memory 对象。与 OpenGL 创建一个对象不同,比如 OpenGL 创建一个 Texture 就能直接使用 Uniform 命令上传数据直接用。而 Vulkan 将 GPU 的内存也放给程序员来管理了,VkDeviceMemory 这个对象就是代表分配的显存。这和 C/C++ 动态内存分配器是一个意思,可以定制很多更高级的分配策略,而且 Vulkan 非常不鼓励小内存分配,Vulkan 的分配次数每个设备都是有上限,就是为了让你做 suballocation。Vulkan 将内存分为 host memory 和 device memory 两类,可以映射设备内存到宿主内存。使用 vkAllocateMemory() 进行分配,并且要通过 vkFreeMemory() 释放,现成的内存分配器有 VMA - Vulkan Memory Allocator,AMD 提供的 Vulkan 内存分配管理器。
Layer 是增强 Vulkan 系统的可选组件,可以在从应用程序到硬件之间拦截、求值和修改现有的 Vulkan 函数。可以通过 vkEnumerateInstanceLayerProperties() 查询层特性。
层被打包为共享库,由加载程序动态加载,并插入到加载器和应用程序之间。使用层需要两件事:二进制文件的位置和要启用的层。要使用的层可以由应用程序显式启用,也可以通过加载程序使用它们来隐式启用。
驱动器是实现了 Kulkan 的函数库,或是通过物理设备直接实现,或者 CPU 模拟实现,都是一个 Driver。最普遍的驱动器类型是 ICD - Installable Client Driver,使用 VkPhysicalDevic 类型表达。加载器负责发现系统中存在的驱动器,枚举所有有效的物理设备并给应用程序提供一个列表。
+=============+ +===============================+ +========+ +=================+
| Application | --> | | --> | Driver | -----> | Physical Device |
+=============+ | | +========+ +=================+
... | Vulkan Loader | ...
+=============+ | | +========+ +=================+
| Application | --> | | --> | Driver | --+--> | Physical Device |
+=============+ +===^^===^^===========^^====^^==+ +========+ | +=================+
|| || || || +--> ...
+==============+ || || +============+ | +=================+
|| || || || +--> | Physical Device |
|| || +=====vv======+ +=====vv======+ +=================+
+===vv====+ +=======vv=+ | Application | | Environment |
| Implict | | Override | | Enabled | | Enabled |
| Layers | | Layers | | Explict | | Explict |
+==^======+ +=^=====^==+ | Layers | | Layers |
| | | +========^====+ +=========^===+
| | | | |
+=============|=====+===============+==================+
| |
+=========^====+ +=======^=============+
| Configurator | <==> | Layer Settings file |
+==============+ +=====================+
过去有实例层和设备层,但设备层在 Vulkan 的早期规范就被弃用了,应该避免使用。
每一层都可以 Hook 或拦截 Vulkan 函数,而 Vulkan 函数又可以被忽略、检查或扩充。没有 Hook 的任何函数跳过该层,控制流只会继续到下一个层或驱动程序,按示意图从左侧的 Implict Layers 开始执行。因此,层可以选择拦截全部或只截取感兴趣的所有已知的 Vulkan 函数。
部分层可以实现的功能如下:
- Validating API usage
- Tracing API calls
- Debugging aids
- Profiling
- Overlay
因为图层是可选的,并且是动态加载的,所以可以根据需要启用和禁用它们。例如,在开发和调试应用程序时,启用某些层可以帮助确保它正确使用 Vulkan API。但在发布应用程序时,这些层是不必要的,因此不会启用,从而提高了应用程序的速度。
VkConfig 配置工具可以生成以下有三种配置输出,前面两种可以由加载器使用:
- The Vulkan Override Layer
- The Vulkan Layer Settings File
- VkConfig Configuration Settings
在以下系统位置可以找到 Vulkan 层配置,Windows 系统在注册表中记录:
| Platform | Output | Location |
|---|---|---|
| Linux | Vulkan Override Layer | $USER/.local/share/vulkan/implicit_layer.d/VkLayer_override.json |
| Vulkan | Layer Settings | $USER/.local/share/vulkan/settings.d/vk_layer_settings.txt |
| VkConfig | Configuration Settings | $USER/.local/share/vulkan/settings.d/vk_layer_settings.txt |
| Windows | Vulkan Override Layer | %HOME%\AppData\Local\LunarG\vkconfig\override\VkLayerOverride.json |
| Vulkan | Layer Settings | HKEY_CURRENT_USER\Software\Khronos\Vulkan\Settings |
| VkConfig | Configuration Settings | HKEY_CURRENT_USER\Software\LunarG\vkconfig |
随 Vulkan 引入的 SPIR-V 作为图形着色器阶段和计算内核的二进制中间表示,它可以将通过各种交叉编译工具将 HLSL 着色器语言编译为不同图形接口使用的着色器程序:
- DXC 即 DirectXShaderCompiler 可以将 HLSL 编译为 SPIR-V,也可以编译为 DXIL;
- SPIRV-Cross 项目提供的工具可以为 OpenGL、OpenGL ES、Metal、D3D 提供 GLSL、ESSL、MSL、HLSL 转译。
{kind=link}
- Porting NAP OpenGL to Vulkan
- Drawing a trangle with Vulkan
- Vulkan API Overview
- GLFW Getting started
- Vulkan: the essentials
- VkStructureType(3) Manual Page
- Vulkan Guide
一个 Vulkan Hello World 实现步骤:
- Create a Vulkan Instance
- Enumerate Physical Devices
- Create a (Logical) Device
- Create a Command Buffer
- Create a Swapchain
- Create a Depth Buffer
- Create a Uniform Buffer
- Descriptor Set Layouts and Pipeline Layouts
- Create a Descriptor Set
- Create a Render Pass
- Crates Shaders
- Create the Framebuffers
- Create a Vertex Buffer
- Create a Graphics Pipeline
- Draw Cube
Vulkan Tutorial 教程画三角形的示范程序步骤安排:
- Step 1 - Instance and physical device selection
- Step 2 - Logical device and queue families
- Step 3 - Window surface and swap chain
- Step 4 - Image views and framebuffers
- Step 5 - Render passes
- Step 6 - Graphics pipeline
- Step 7 - Command pools and command buffers
- Step 8 - Main loop
遵循前期配置、设备指定、图形管道、绘制等基本流程操作。
与 OpenGL 相比,这种 HelloWorld 程序结构绝对是不能用简单来表达的。所以,把 OpenGL 称为图形 API,而 Vulkan 称为 GPU API 是十分正确的。
这么细致的绘图过程离不开以下这些关键对象:
- RenderPass Describes where you are rendering to. RenderPasses are bound to render targets. The ‘clear’ behaviour is also set here. RenderPasses can contain multiple subpasses, but we don’t use those, as they are primarily important for optimizing certain renderers in mobile hardware
- Pipeline Describes how you are going to render
- Descriptor Set Interface to a shader. Allows for binding uniforms (using a Uniform Buffer Object) and textures
- Command Buffer Used to record commands which can be subsequently submitted the the GPU for execution
Vulkan 调用 GPU 的流程细节可以参考 Vulkan and NVIDIA The Essentials 演示文档。

创建 Vulkan 实例,与相关的 API 及结构体:
VkInstance inst;
VkResult res;
res = vkCreateInstance(&inst_info, NULL, &inst);
if (res == VK_ERROR_INCOMPATIBLE_DRIVER) {
throw "cannot find a compatible Vulkan ICD\n";
} else if (res) {
throw "unknown error\n";
}
vkDestroyInstance(inst, NULL);
// Declarations
VkResult vkCreateInstance(
const VkInstanceCreateInfo* pCreateInfo,
const VkAllocationCallbacks* pAllocator,
VkInstance* pInstance);
typedef struct VkInstanceCreateInfo {
VkStructureType sType;
const void* pNext;
VkInstanceCreateFlags flags;
const VkApplicationInfo* pApplicationInfo;
uint32_t enabledLayerCount;
const char* const* ppEnabledLayerNames;
uint32_t enabledExtensionCount;
const char* const* ppEnabledExtensionNames;
} VkInstanceCreateInfo;
typedef struct VkApplicationInfo {
VkStructureType sType;
const void* pNext;
const char* pApplicationName;
uint32_t applicationVersion;
const char* pEngineName;
uint32_t engineVersion;
uint32_t apiVersion;
} VkApplicationInfo;注意 VkStructureType 枚举类型,在 Vulkan 架构中,有许多结构体类型都称为扩展规范结构体,extension-specific structure,使用 pNext 指针进行链接,使用 SType 指定结构体类型。
Any parameter that is a structure containing a sType member must have a value of sType which is a valid VkStructureType value matching the type of the structure.
注意,创建 Vulkan 实例的方法需要以下参数:
- 一个指向 creation info 结构的指针;
- 一个指向自定义的内存分配器回调函数的指针,这是可选的,教程中直接使用 nullptr;
- 一个指向存放实例句柄的变量指针;
创建实例时返回的 VkResult 值如果不为 VK_SUCCESS 就表示创建失败,原因可能是内存、中间层、扩展、驱动等方法的问题:
VK_ERROR_OUT_OF_HOST_MEMORY
VK_ERROR_OUT_OF_DEVICE_MEMORY
VK_ERROR_INITIALIZATION_FAILED
VK_ERROR_LAYER_NOT_PRESENT
VK_ERROR_EXTENSION_NOT_PRESENT
VK_ERROR_INCOMPATIBLE_DRIVER
CMake 3.18 对 Vulkan 良好支持,提供了 FindVulkan.cmake 脚本,只要系统安装了 SDK 就可以通过环境变量 $env:VULKAN_SDK 获取到依赖文件。
Vulkan 定义为 IMPORTED 模块,导入非常方便,执行以下命令就获得相应的依赖:
find_package (Vulkan REQUIRED)
- Vulkan::Vulkan The main Vulkan library.
- Vulkan::glslc New in version 3.19. The GLSLC SPIR-V compiler, if it has been found.
- Vulkan::Headers New in version 3.21. Provides just Vulkan headers include paths, if found. No library is included in this target. This can be useful for applications that load Vulkan library dynamically.
- Vulkan::glslangValidator New in version 3.21. The glslangValidator tool, if found. It is used to compile GLSL and HLSL shaders into SPIR-V.
- https://vulkan-tutorial.com/code/00_base_code.cpp
- https://vulkan-tutorial.com/code/01_instance_creation.cpp
Vulkan Tutorial 给出一个基于 FLFW 框架的程序基本骨架,这里修改了部分功能,添加了 C++ function-try-blocks 异常处理功能:
#define GLFW_INCLUDE_VULKAN
#include <GLFW/glfw3.h>
#include <iostream>
#include <stdexcept>
#include <cstdlib>
const uint32_t WIDTH = 800;
const uint32_t HEIGHT = 600;
class HelloTriangleApplication {
public:
void run() {
initWindow();
initVulkan();
mainLoop();
cleanup();
}
private:
GLFWwindow* window;
void initWindow() {
glfwInit();
glfwWindowHint(GLFW_CLIENT_API, GLFW_NO_API);
glfwWindowHint(GLFW_RESIZABLE, GLFW_FALSE);
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);
}
void initVulkan() {
}
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
}
}
void cleanup() {
glfwDestroyWindow(window);
glfwTerminate();
}
};
int main() try
{
HelloTriangleApplication app;
app.run();
return EXIT_SUCCESS;
}
catch (const char* e)
{
std::cout << e << std::endl;
return EXIT_FAILURE;
}
catch (const std::exception& e)
{
std::cout << e.what() << std::endl;
return EXIT_FAILURE;
}不像 OpenGL,Vulkan 的上下文直接通过 API 创建 Vulkan Instances,所以设置 GLFW_CLIENT_API 初始值为 GLFW_NO_API,不需要 GLFW 自行创建 OpenGL 上下文。
为了简化程序,也禁止窗口大小调整,因为根据窗口大小处理内容也是件增加复杂度的事。
创建窗口的方法中只使用了前面两个参数设置尺寸,第三个参数设置 GLFWmonitor 指定窗口在哪个显示器创建,最后一个指定 GLFWwindow 在 OpenGL 下用来创建上下文对象。
GLFW 所有初始参考值存放在一个 _GLFWlibrary 结构体中,hints 字段包含了初始化需要用到的配置参数。
在主循环中,使用 GLFW 3.0 最新的函数 glfwWindowShouldClose() 来检测是否要退出循环。
程序退出时,执行窗口关闭动作清理相关资源,并调用 GLFW 结束函数。
在 Vulkan 程序中,首先需要创建 Vulkan Instance。这一步操作需要使用一些信息,使用 VkApplicationInfo 和 VkInstanceCreateInfo 结构,驱动可以根据信息对于一些知名的引擎进行优化,当然是可选的内容。
void createInstance() {
VkApplicationInfo appInfo{};
appInfo.sType = VK_STRUCTURE_TYPE_APPLICATION_INFO;
appInfo.pApplicationName = "Hello Triangle";
appInfo.applicationVersion = VK_MAKE_VERSION(1, 0, 0);
appInfo.pEngineName = "No Engine";
appInfo.engineVersion = VK_MAKE_VERSION(1, 0, 0);
appInfo.apiVersion = VK_API_VERSION_1_0;
VkInstanceCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO;
createInfo.pApplicationInfo = &appInfo;
uint32_t glfwExtensionCount = 0;
const char** glfwExtensions;
glfwExtensions = glfwGetRequiredInstanceExtensions(&glfwExtensionCount);
createInfo.enabledExtensionCount = glfwExtensionCount;
createInfo.ppEnabledExtensionNames = glfwExtensions;
// createInfo.enabledLayerCount
// createInfo.ppEnabledLayerNames
createInfo.enabledLayerCount = 0;
if (vkCreateInstance(&createInfo, nullptr, &instance) != VK_SUCCESS) {
throw std::runtime_error("failed to create instance!");
}
}创建实例前,需要指定整个程序所使用的扩展、Layers,这是必需设置的,设置错误会产生 VK_ERROR_LAYER_NOT_PRESENT 或 VK_ERROR_EXTENSION_NOT_PRESENT 异常。这里没有使用到 Layer 相关的设置,即暂时没有加载、启用全局层,后面 Validation layers 部分专门解析。
GLFW 提供了函数用来获取扩展,也可以使用 Vulkan API 查询当前系统存在的扩展,查询结果存放在一个 VkExtensionProperties 结构体数组中,可以使用 C++ 标准模板库的向量容器保存,其 date() 方法可以访问到底层的数组:
std::vector<VkExtensionProperties> extensions(glfwExtensionCount);
vkEnumerateInstanceExtensionProperties(nullptr, &glfwExtensionCount, extensions.data());
std::cout << extensions.size() << " Available extensions:\n";
for (const auto& extension : extensions) {
std::cout << '\t' << extension.extensionName << "\t"
<< extension.specVersion << std::endl;
}
// Output:
// 2 Available extensions:
// VK_KHR_surface 25
// VK_KHR_win32_surface 5类似地,可以查询系统现有的中间层:
uint32_t layerCount;
vkEnumerateInstanceLayerProperties(&layerCount, nullptr);
std::vector<VkLayerProperties> availableLayers(layerCount);
vkEnumerateInstanceLayerProperties(&layerCount, availableLayers.data());
for (const auto& layerProperties : availableLayers)
std::cout << "Layer: " << layerProperties.layerName << std::endl;
// Layer: VK_LAYER_NV_optimus
// Layer: VK_LAYER_VALVE_steam_overlay
// Layer: VK_LAYER_VALVE_steam_fossilize
// Layer: VK_LAYER_RENDERDOC_Capture
// Layer: VK_LAYER_EOS_Overlay
// Layer: VK_LAYER_EOS_Overlay
// Layer: VK_LAYER_LUNARG_api_dump
// Layer: VK_LAYER_LUNARG_device_simulation
// Layer: VK_LAYER_LUNARG_gfxreconstruct
// Layer: VK_LAYER_KHRONOS_synchronization2
// Layer: VK_LAYER_KHRONOS_validation- https://github.com/KhronosGroup/Vulkan-ValidationLayers
- https://vulkan-tutorial.com/code/02_validation_layers.cpp
- https://www.intel.com/content/www/us/en/developer/articles/training/api-without-secrets-introduction-to-vulkan-part-1.html
- Layers Overview and Configuration https://vulkan.lunarg.com/doc/view/1.2.182.0/windows/layer_configuration.html
Vulkan 是一个以性能最大化为导向的 GUP API,和 OpenGL 的错误处理不同,Vulkan 尽量不做错误检查,所以任何不正确的 API 使用方式都会导致程序异常终止。
Vulkan 体系构架引入的中间层 Layer 的其中一个目的就是为整个 API 构架增加灵活性。
这部分内容就是介绍用于检查 API 正确用法的 Validation Layers,它主要作用包括:
- Checking the values of parameters against the specification to detect misuse
- Tracking creation and destruction of objects to find resource leaks
- Checking thread safety by tracking the threads that calls originate from
- Logging every call and its parameters to the standard output
- Tracing Vulkan calls for profiling and replaying
Vulkan 规范没有定义验证,这是 LunarG Vulkan SDK 提供的验证层实现,名称为 VK_LAYER_KHRONOS_validation,这是开源的项目:
git clone git@github.com:KhronosGroup/Vulkan-ValidationLayers
在旧规范中,验证层有两种类型:实例层和设备层,instance and device specific,但设备层在 Vulkan 的早期规范就被弃用了,应该避免使用。设备验证层目的是针对不同的 GPU 进行验证,而实例验证层对全局的 Vulkan 对象如 VkInstance 进行验证。
注意,VkApplicationInfo 和 VkInstanceCreateInfo 都是链式数据结构,可以链接任何 extension-specific structure,具体类型使用 VkStructureType 枚举值指定。通过 pNext 字段可以设置于任意的扩展规范结构体,通过 sType 字段指定结构体类型,比如设置调试信息。
获取调试信息使用了以下中间层及扩展:
- Validation Layer,由 LunarG Vulkan SDK 提供实现;
- VK_EXT_debug_utils 扩展,验证层隐含的,名称常量为 VK_EXT_DEBUG_UTILS_EXTENSION_NAME;
使用这个调试扩展并不需要确认是否会有 VK_ERROR_EXTENSION_NOT_PRESENT 异常,这个扩展是验证层默认提供的,直接使用就可以。
为了引入调试中间层,可以使用 NDEBUG 预处理符号,即 Not debug 符号有定义时,打开调试功能:
const std::vector<const char*> validationLayers = {
"VK_LAYER_KHRONOS_validation"
};
#ifdef NDEBUG
const bool enableValidationLayers = false;
#else
const bool enableValidationLayers = true;
#endif创建 Vulkan 实例时,同时根据调试符号设置相应的验证中间层,可以在 CMake 中设置以下脚本来激活调试设置:
set(CMAKE_BUILD_TYPE Debug)
另外,增加一个函数用于检查蹭层扩展的有效性,同时将扩展加载独立在一个函数处理:
std::vector<const char *> getRequiredExtensions()
{
uint32_t glfwExtensionCount = 0;
const char** glfwExtensions;
glfwExtensions = glfwGetRequiredInstanceExtensions(&glfwExtensionCount);
std::vector<const char*> exts(glfwExtensions, glfwExtensions+glfwExtensionCount);
exts.push_back(VK_EXT_DEBUG_UTILS_EXTENSION_NAME);
return exts;
}
void setupDebugerCreateInfo(VkInstanceCreateInfo &createInfo, VkDebugUtilsMessengerCreateInfoEXT debugCreateInfo)
{
if (!enableValidationLayers)
{
createInfo.enabledLayerCount = 0;
createInfo.pNext = nullptr;
return;
}
if (!checkValidationLayerSupport()) {
throw std::runtime_error("Validation layers requested, but not available!");
}
createInfo.enabledLayerCount = static_cast<uint32_t>(validationLayers.size());
createInfo.ppEnabledLayerNames = validationLayers.data();
populateDebugMessengerCreateInfo(debugCreateInfo);
createInfo.pNext = (VkDebugUtilsMessengerCreateInfoEXT*) &debugCreateInfo;
}
bool checkValidationLayerSupport() {
uint32_t layerCount;
vkEnumerateInstanceLayerProperties(&layerCount, nullptr);
std::vector<VkLayerProperties> availableLayers(layerCount);
vkEnumerateInstanceLayerProperties(&layerCount, availableLayers.data());
for (const char* layerName : validationLayers) {
bool layerFound = false;
for (const auto& layerProperties : availableLayers) {
if (strcmp(layerName, layerProperties.layerName) == 0) {
layerFound = true;
break;
}
}
if (!layerFound) {
return false;
}
}
return true;
}另外定义两个函数,一个用于填充 DebugMessengerCreateInfo 结构体,另一个是调试回调函数:
void populateDebugMessengerCreateInfo(VkDebugUtilsMessengerCreateInfoEXT& createInfo) {
createInfo = {};
createInfo.sType = VK_STRUCTURE_TYPE_DEBUG_UTILS_MESSENGER_CREATE_INFO_EXT;
createInfo.messageSeverity =
VK_DEBUG_UTILS_MESSAGE_SEVERITY_VERBOSE_BIT_EXT
| VK_DEBUG_UTILS_MESSAGE_SEVERITY_WARNING_BIT_EXT
| VK_DEBUG_UTILS_MESSAGE_SEVERITY_ERROR_BIT_EXT;
createInfo.messageType =
VK_DEBUG_UTILS_MESSAGE_TYPE_GENERAL_BIT_EXT
| VK_DEBUG_UTILS_MESSAGE_TYPE_VALIDATION_BIT_EXT
| VK_DEBUG_UTILS_MESSAGE_TYPE_PERFORMANCE_BIT_EXT;
createInfo.pfnUserCallback = debugCallback;
createInfo.pUserData = nullptr; // Optional
}
void setupDebugMessenger() {
if (!enableValidationLayers) return;
VkDebugUtilsMessengerCreateInfoEXT createInfo;
populateDebugMessengerCreateInfo(createInfo);
if (CreateDebugUtilsMessengerEXT(instance, &createInfo, nullptr, &debugMessenger) != VK_SUCCESS) {
throw std::runtime_error("failed to set up debug messenger!");
}
}
static VKAPI_ATTR VkBool32 VKAPI_CALL debugCallback(
VkDebugUtilsMessageSeverityFlagBitsEXT messageSeverity,
VkDebugUtilsMessageTypeFlagsEXT messageType,
const VkDebugUtilsMessengerCallbackDataEXT* pCallbackData,
void* pUserData)
{
if (messageSeverity >= VK_DEBUG_UTILS_MESSAGE_SEVERITY_WARNING_BIT_EXT)
// Message is important enough to show
std::cerr << "Validation layer: " << pCallbackData->pMessage << std::endl;
return VK_FALSE;
}在回调函数中,可以根据信息的等级 messageSeverity 确定是否要显示,以过滤掉多余的信息,枚举类型 VkDebugUtilsMessageSeverityFlagBitsEXT 提供了 VERBOSE、INFO、WARNING、ERROR 这些等级设置。创建调试信息结构体时,可以设置需要的信息等级。
messageType 参数可以是以下值:
- VK_DEBUG_UTILS_MESSAGE_TYPE_GENERAL_BIT_EXT: Some event has happened that is unrelated to the specification or performance
- VK_DEBUG_UTILS_MESSAGE_TYPE_VALIDATION_BIT_EXT: Something has happened that violates the specification or indicates a possible mistake
- VK_DEBUG_UTILS_MESSAGE_TYPE_PERFORMANCE_BIT_EXT: Potential non-optimal use of Vulkan
pCallbackData 用来传递一个 VkDebugUtilsMessengerCallbackDataEXT 结构体,它包含消息详细内容:
- pMessage: The debug message as a null-terminated string
- pObjects: Array of Vulkan object handles related to the message
- objectCount: Number of objects in array
如果有用户自定义的数据结构,可以通过 pUserData 进行传递。
这里还需要两个 Vulkan API,vkCreateDebugUtilsMessengerEXT 和 vkDestroyDebugUtilsMessengerEXT 分别用于绑定调试回调函数和结束时清理回调函数,以下演示如何通过 vkGetInstanceProcAddr 来获取 API 函数指针,参考 API without Secrets: Introduction to Vulkan:
VkResult CreateDebugUtilsMessengerEXT(VkInstance instance,
const VkDebugUtilsMessengerCreateInfoEXT* pCreateInfo,
const VkAllocationCallbacks* pAllocator,
VkDebugUtilsMessengerEXT* pDebugMessenger)
{
auto func = (PFN_vkCreateDebugUtilsMessengerEXT) vkGetInstanceProcAddr(instance, "vkCreateDebugUtilsMessengerEXT");
if (func != nullptr) {
return func(instance, pCreateInfo, pAllocator, pDebugMessenger);
} else {
return VK_ERROR_EXTENSION_NOT_PRESENT;
}
}
void DestroyDebugUtilsMessengerEXT(VkInstance instance, VkDebugUtilsMessengerEXT debugMessenger, const VkAllocationCallbacks* pAllocator) {
auto func = (PFN_vkDestroyDebugUtilsMessengerEXT) vkGetInstanceProcAddr(instance, "vkDestroyDebugUtilsMessengerEXT");
if (func != nullptr) {
func(instance, debugMessenger, pAllocator);
}
}在创建实例成功后,调用 setupDebugMessenger() 绑定调试回调函数,并且在结束程序时执行调试器回调清理函数:
if (enableValidationLayers) {
DestroyDebugUtilsMessengerEXT(instance, debugMessenger, nullptr);
}如果,在销毁子对象之前尝试销毁 Vulkan 实例,就会触发错误用法 VUID-vkDestroyInstance-instance-00629:
All child objects created using instance must have been destroyed prior to destroying instance
启用验证中间层后,并且在 Debug 编译模式下会输出类似以下的调试信息,:
loaderAddLayerProperties: \SDK1.2\Bin\VkLayer_api_dump.json invalid layer manifest file version 1.2.0. May cause errors.
loaderAddLayerProperties: \SDK1.2\Bin\VkLayer_device_simulation.json ... May cause errors.
loaderAddLayerProperties: \SDK1.2\Bin\VkLayer_gfxreconstruct.json ... May cause errors.
loaderAddLayerProperties: \SDK1.2\Bin\VkLayer_khronos_synchronization2.json ... May cause errors.
loaderAddLayerProperties: \SDK1.2\Bin\VkLayer_khronos_validation.json ... May cause errors.
loaderAddLayerProperties: \SDK1.2\Bin\VkLayer_screenshot.json ... May cause errors.
Instance Extension: VK_KHR_surface (...\igvk64.dll) version 0.0.25
Instance Extension: VK_KHR_win32_surface (...\igvk64.dll) version 0.0.5
Instance Extension: VK_KHR_external_memory_capabilities (...\igvk64.dll) version 0.0.1
Instance Extension: VK_KHR_external_semaphore_capabilities (...\igvk64.dll) version 0.0.1
Instance Extension: VK_KHR_external_fence_capabilities (...\igvk64.dll) version 0.0.1如果没有相应的调试信息,就需要检查 LunarG Vulkan SDK 的安装是否正确。
验证层还有许多功能设置,而不仅仅是 VkDebugUtilsMessengerCreateInfoEXT 结构体上指定的这此标记,在 Vulkan SDK 的安装目录下的 Config 子目录可以找到一个 vk_layer_settings.txt 文件,它解释了如何配置中间层。在 Tools 目录下还提供了一个中间层配置工具 Vulkan Configurator,可以用 vkconfig 这个程序来配置中间层,它会检测系统当前已安装的中间层,并可以给指定的程序配置中间层。
Vulkan Development Status:
- Layers override: "Validation" configuration
- VULKAN_SDK environment variable: C:\VulkanSDK\1.2.198.1B
- Vulkan Loader version: 1.2.162
- VK_LOADER_DEBUG=all
- User-Defined Layers Paths from VK_LAYER_PATH environment variable: None
- User-Defined Layers Paths from Vulkan Configurator: None
- `vk_layer_settings.txt` uses the default platform path:
C:\Users\OCEAN\AppData\Local\LunarG\vkconfig\override
- Available Layers:
- VK_LAYER_NV_optimus (1.2.155)
- VK_LAYER_VALVE_steam_overlay (1.2.136)
- VK_LAYER_VALVE_steam_fossilize (1.2.136)
- VK_LAYER_RENDERDOC_Capture (1.3.131)
- VK_LAYER_EOS_Overlay (1.2.136)
- VK_LAYER_EOS_Overlay (1.2.136)
- VK_LAYER_LUNARG_api_dump (1.2.198)
- VK_LAYER_LUNARG_device_simulation (1.2.198)
- VK_LAYER_LUNARG_gfxreconstruct (1.2.198)
- VK_LAYER_KHRONOS_synchronization2 (1.2.198)
- VK_LAYER_KHRONOS_validation (1.2.198)
- VK_LAYER_LUNARG_monitor (1.2.198)
- VK_LAYER_LUNARG_screenshot (1.2.198)
- Physical Devices:
- GeForce GTX 1050 (Discrete GPU) with Vulkan 1.2.155
- Intel(R) UHD Graphics 620 (Integrated GPU) with Vulkan 1.2.148
Vulkan Layers Configurations 面板显示中间层预置,每个配置都包含任意中间层,可以根据需要启用或禁用,也可以创建自定义配置,右侧的 New Configurations Settings 面板提供中间层覆盖设置。比如,Validation 配置,可以设置输出调试消息的等级,也可以添加 Mute Message VUIDs 设置,禁止显示指定的 VUID 调试信息。
Vulkan Application Launcher 面板指定要加载的程序,执行后会在日志面板及日志文件中输出调试信息。
- https://vulkan-tutorial.com/code/03_physical_device_selection.cpp
- https://vulkan-tutorial.com/code/04_logical_device.cpp
前面的操作只是建立了一个 Vulkan 实例,也就是相当于 Vulkan Loader 的初始化。因为还没有指定具体的硬件设备,所以离绘制图像还差很远,甚至图形管道都没有建立。
Vulkan 架构中使用了两个设备概念:硬件设备 VkPhysicalDevice 和逻辑设备 VkDevice。
指定设备前,需要通过设备枚举方法获取系统当前现有的设备,并且需要获取具体设备所有的功能特性,只有满足条件的设备才能使用,典型的就是选择渲染管线支持 Geometry Shader 可编程的独立 GPU。当然,现代的集成显卡通常也支持可编程几何着色器阶段。
选择好物理设备,Vulkan 还需要通过抽象的逻辑设备对象来使用这些物理设备,所以后续的操作就是创建 VkDevice。这和创建 Vulkan 实例类似,先需要通结构体给出描述信息,指明需要使用设备的什么功能及特性,并且指明使用哪些队列类型。如果有需要,可以在同一个硬件上创建多个逻辑设备。
到目前为止,已经使用到的扩展规范结构体 extension-specific structure 有以下这些:
VK_STRUCTURE_TYPE_APPLICATION_INFO
VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO
VK_STRUCTURE_TYPE_DEBUG_UTILS_MESSENGER_CREATE_INFO_EXT
VK_STRUCTURE_TYPE_DEVICE_QUEUE_CREATE_INFO
现在需要在程序基本结构中添加以下几个数据成员:
VkPhysicalDevice physicalDevice = VK_NULL_HANDLE;
VkDevice device;
VkQueue graphicsQueue;这里还可能会使用到 C++ 标准库的关联容器 multimap 类型,它是有有序关联容器。可以根据设备功能进行评分,最后取最佳的设备,以下代码片段给出一个示范。
#include <map>
void pickPhysicalDevice()
{
// Use an ordered map to automatically sort candidates by increasing score
std::multimap<int, VkPhysicalDevice> candidates;
for (const auto& device : devices) {
int score = rateDeviceSuitability(device);
candidates.insert(std::make_pair(score, device));
}
// Check if the best candidate is suitable at all
if (candidates.rbegin()->first > 0) {
physicalDevice = candidates.rbegin()->second;
} else {
throw std::runtime_error("failed to find a suitable GPU!");
}
}
int rateDeviceSuitability(VkPhysicalDevice device)
{
int score = 0;
// Discrete GPUs have a significant performance advantage
if (deviceProperties.deviceType == VK_PHYSICAL_DEVICE_TYPE_DISCRETE_GPU) {
score += 1000;
}
// Maximum possible size of textures affects graphics quality
score += deviceProperties.limits.maxImageDimension2D;
// Application can't function without geometry shaders
if (!deviceFeatures.geometryShader) {
return 0;
}
return score;
}使用函数获取设备的属性及特性数据,目前教程主要使用到的是 GPU 特性是独立显卡的几何着色器:
bool TestDevice(VkPhysicalDevice device) {
VkPhysicalDeviceProperties deviceProperties;
VkPhysicalDeviceFeatures deviceFeatures;
vkGetPhysicalDeviceProperties(device, &deviceProperties);
vkGetPhysicalDeviceFeatures(device, &deviceFeatures);
auto apiVersion = deviceProperties.apiVersion;
std::cout << deviceProperties.deviceName << std::endl
<< "\tapiVersion: "
<< VK_VERSION_MAJOR(apiVersion) << "."
<< VK_VERSION_MINOR(apiVersion) << "."
<< VK_VERSION_PATCH(apiVersion) << std::endl
<< "\tdriverVersion: " << deviceProperties.driverVersion << std::endl
<< "\tvendorID: " << deviceProperties.vendorID << std::endl
<< "\tdeviceID: " << deviceProperties.deviceID << std::endl
<< "\tdeviceType: " << deviceProperties.deviceType << std::endl;
return deviceProperties.deviceType == VK_PHYSICAL_DEVICE_TYPE_DISCRETE_GPU &&
deviceFeatures.geometryShader;
}输出内容,硬件供应商 ID 是在 PCI-SIG 注册分配的:
GeForce GTX 1050
apiVersion: 1.2.155
driverVersion: 1934229504
vendorID: 4318
deviceID: 7309
deviceType: 2
Intel(R) UHD Graphics 620
apiVersion: 1.2.148
driverVersion: 1647082
vendorID: 32902
deviceID: 22807
deviceType: 1
选定的图形卡保存在一个 VkPhysicalDevice 指针上,并且它会随着 Vulkan 实例的销毁而自动销毁,所以不要多余的清理工作。但是逻辑设备需要手动调用 vkDestroyDevice() 进行销毁,它第二个参数接收的是一个用户自定义的内存分配器。
vkDestroyDevice(device, nullptr);
和枚举实例扩展、中间层类似,物理设备也可以通过相应的枚举方法获取,只需要将查询到的设备保存在一个向量容器中即可。
队列族 Queue Family 就是各种命令按类型进行分组的队列,Vulkan 中几乎所有的操作,从绘图到上传纹理,都需要先将命令提交到队列中。不同类型的队列来自不同的队列族,每个队列族只允许相应的命令子集。例如,一个队列系列只允许处理计算命令,也可能有一个队列系列只允许处理与内存传输相关的命令。
使用设备前需要进行检测,看看设备是不是支持相应的命令。通过枚举方法获取设备的 VkQueueFamilyProperties 属性:
- queueFlags 标志位指定支持的队列类型,VkQueueFlags 枚举类型;
- queueCount 支持的队列数量,至少支持一个队列;
- timestampValidBits 是通过 VkCmdWriteTimestamp 写入的无符号整数时间戳中有意义位计数,0 值表示不支持时间戳。
- minImageTransferGranularity 是此队列系列中队列上的图像传输操作支持的最小粒度。
typedef enum VkQueueFlagBits {
VK_QUEUE_GRAPHICS_BIT = 0x00000001,
VK_QUEUE_COMPUTE_BIT = 0x00000002,
VK_QUEUE_TRANSFER_BIT = 0x00000004,
VK_QUEUE_SPARSE_BINDING_BIT = 0x00000008,
VK_QUEUE_PROTECTED_BIT = 0x00000010,
VK_QUEUE_FLAG_BITS_MAX_ENUM = 0x7FFFFFFF
} VkQueueFlagBits;不同的硬件可能支持不同的命令组合,规范指出,任何 Vulkan 设备至少有一种 Graphics 和 Compute 的组合,同时,都隐含的支持 Transfer 命令。
C++17 引入 optional 类型,可以用来表达未经过设置的状态:
#include <optional>
// ...
std::optional<uint32_t> graphicsFamily;
std::cout << std::boolalpha << graphicsFamily.has_value() << std::endl; // false
graphicsFamily = 0;
std::cout << std::boolalpha << graphicsFamily.has_value() << std::endl; // true在 CMake 脚本中需要加入相应的 C++17 规范变量设置:
set(CMAKE_CXX_STANDARD 17)
struct QueueFamilyIndices
{
std::optional<uint32_t> graphicsFamily;
bool isComplete() {
return graphicsFamily.has_value();
}
};
void pickPhysicalDevice()
{
uint32_t deviceCount = 0;
vkEnumeratePhysicalDevices(instance, &deviceCount, nullptr);
if (deviceCount == 0) {
throw std::runtime_error("failed to find GPUs with Vulkan support!");
}
std::vector<VkPhysicalDevice> devices(deviceCount);
vkEnumeratePhysicalDevices(instance, &deviceCount, devices.data());
for (const auto& device : devices) {
if (isDeviceSuitable(device)) {
physicalDevice = device;
break;
}
}
if (physicalDevice == VK_NULL_HANDLE) {
throw std::runtime_error("failed to find a suitable GPU!");
}
}
bool isDeviceSuitable(VkPhysicalDevice device)
{
QueueFamilyIndices indices = findQueueFamilies(device);
return indices.isComplete();
}
QueueFamilyIndices findQueueFamilies(VkPhysicalDevice device)
{
QueueFamilyIndices indices;
uint32_t queueFamilyCount = 0;
vkGetPhysicalDeviceQueueFamilyProperties(device, &queueFamilyCount, nullptr);
std::vector<VkQueueFamilyProperties> queueFamilies(queueFamilyCount);
vkGetPhysicalDeviceQueueFamilyProperties(device, &queueFamilyCount, queueFamilies.data());
int i = 0;
for (const auto& queueFamily : queueFamilies) {
if (queueFamily.queueFlags & VK_QUEUE_GRAPHICS_BIT) {
indices.graphicsFamily = i;
break;
}
i++;
}
return indices;
}