The code for our network is inspired from timbmg's implementation of the same. The network is summarized in the following figure:
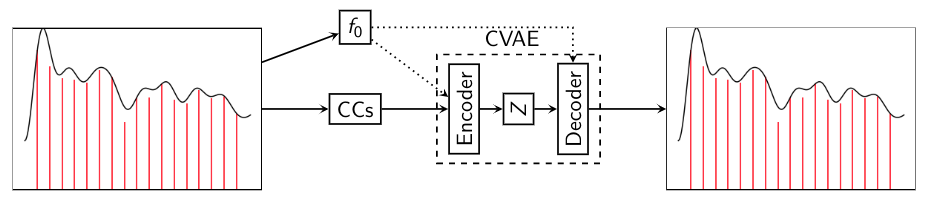
Network Source Code-
- simple_ae.py - Autoencoder (Deterministic feed-forward).
- vae_krishna.py - Conditional Variational Autoencoder. There is a β weighting term between the Variational loss and the reconstruction loss which can be changed accordingly (We use β = 0.1)
- dataset.py - Our custom PyTorch Data Loader. It has been written to take as input the output of the Pickle Dump (generated as the output of the Parametric/Spectral Modeling). It loads the data from the dump into the dataloader.
For both networks, checkout the code for additional parameters (number of layers, latent space dimensionality, CUDA availability etc). We use linear fully-connected layers with leaky-ReLU activations
Network Architecture-
Training on the parametric representation
- synth_vae.py - CVAE
- ae_synth.py - AE
Training on the magnitude spectrum
- synth_vae_fft.py - CVAE
- ae_synth_fft.py - AE
All the above networks save the weights of the trained network (and the network description) into a PyTorch .pth file (into the specified directory in the specific code)
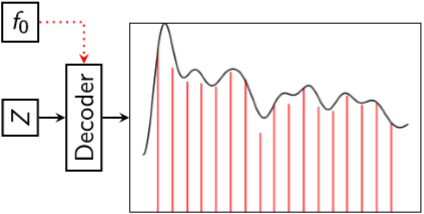
There is also code to 'sample' sound from the latent space - network_GenSynth.py. It samples sound from the trained CVAE network as shown below,
The code samples from the latent space and the decoder expects a pitch contour as a conditional input. With this code, you can either- 1. 'Draw' your own pitch contour or 2. Use a vibrato (frequency modulated) pitch contour. Refer to the code for more details.
To evaluate the network working we have written network_data_recon.py and network_data_recon_fft.py which performs 2 things-
- Reconstructs the input audio using the network
- Compute the MSE (averaged across all the input pitches)
The file requires the PyTorch network weights of both CVAE and AE to run (apologies for the inefficiently written code, hope to improve this!). When the code is run, it will ask you to select the .pth file for both CVAE and AE, and also specify the directory to save the network generated audio (along with the MSE plot for each pitch)
For the parametric representation, the audio is obtained by sampling the envelope and performing a sinusoidal reconstruction. For the magnitude spectrum reconstruction, Griffin-Lim is used to invert the magnitude spectrogram to obtain the audio.