这里使用工具为Python3.5,OpenCV-Python包(cv2),Numpy,matlablib
- 图像读取
import cv2
# 读取一张400x600分辨率的图像
color_img = cv2.imread('test_400x600.jpg')
print(color_img.shape)
# 直接读取单通道
gray_img = cv2.imread('test_400x600.jpg', cv2.IMREAD_GRAYSCALE)
print(gray_img.shape)
# 把单通道图片保存后,再读取,仍然是3通道,相当于把单通道值复制到3个通道保存
cv2.imwrite('test_grayscale.jpg', gray_img)
reload_grayscale = cv2.imread('test_grayscale.jpg')
print(reload_grayscale.shape)
# cv2.IMWRITE_JPEG_QUALITY指定jpg质量,范围0到100,默认95,越高画质越好,文件越大
cv2.imwrite('test_imwrite.jpg', color_img, (cv2.IMWRITE_JPEG_QUALITY, 80))
# cv2.IMWRITE_PNG_COMPRESSION指定png质量,范围0到9,默认3,越高文件越小,画质越差
cv2.imwrite('test_imwrite.png', color_img, (cv2.IMWRITE_PNG_COMPRESSION, 5))
- 缩放,裁剪,补边
import cv2
# 读取一张四川大录古藏寨的照片
img = cv2.imread('tiger_tibet_village.jpg')
# 缩放成200x200的方形图像
img_200x200 = cv2.resize(img, (200, 200))
# 不直接指定缩放后大小,通过fx和fy指定缩放比例,0.5则长宽都为原来一半
# 等效于img_200x300 = cv2.resize(img, (300, 200)),注意指定大小的格式是(宽度,高度)
# 插值方法默认是cv2.INTER_LINEAR,这里指定为最近邻插值
img_200x300 = cv2.resize(img, (0, 0), fx=0.5, fy=0.5,
interpolation=cv2.INTER_NEAREST)
# 在上张图片的基础上,上下各贴50像素的黑边,生成300x300的图像
img_300x300 = cv2.copyMakeBorder(img, 50, 50, 0, 0,
cv2.BORDER_CONSTANT,
value=(0, 0, 0))
# 对照片中树的部分进行剪裁
patch_tree = img[20:150, -180:-50]
cv2.imwrite('cropped_tree.jpg', patch_tree)
cv2.imwrite('resized_200x200.jpg', img_200x200)
cv2.imwrite('resized_200x300.jpg', img_200x300)
cv2.imwrite('bordered_300x300.jpg', img_300x300)
- 色调,明暗,直方图和Gamma曲线
# 通过cv2.cvtColor把图像从BGR转换到HSV
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# H空间中,绿色比黄色的值高一点,所以给每个像素+15,黄色的树叶就会变绿
turn_green_hsv = img_hsv.copy()
turn_green_hsv[:, :, 0] = (turn_green_hsv[:, :, 0]+15) % 180
turn_green_img = cv2.cvtColor(turn_green_hsv, cv2.COLOR_HSV2BGR)
cv2.imwrite('turn_green.jpg', turn_green_img)
# 减小饱和度会让图像损失鲜艳,变得更灰
colorless_hsv = img_hsv.copy()
colorless_hsv[:, :, 1] = 0.5 * colorless_hsv[:, :, 1]
colorless_img = cv2.cvtColor(colorless_hsv, cv2.COLOR_HSV2BGR)
cv2.imwrite('colorless.jpg', colorless_img)
# 减小明度为原来一半
darker_hsv = img_hsv.copy()
darker_hsv[:, :, 2] = 0.5 * darker_hsv[:, :, 2]
darker_img = cv2.cvtColor(darker_hsv, cv2.COLOR_HSV2BGR)
cv2.imwrite('darker.jpg', darker_img)
- 直方图和Gamma变换
无论是HSV还是RGB,我们都较难一眼就对像素中值的分布有细致的了解,这时候就需要直方图。如果直方图中的成分过于靠近0或者255,可能就出现了暗部细节不足或者亮部细节丢失的情况。比如图6-2中,背景里的暗部细节是非常弱的。这个时候,一个常用方法是考虑用Gamma变换来提升暗部细节。Gamma变换是矫正相机直接成像和人眼感受图像差别的一种常用手段,简单来说就是通过非线性变换让图像从对曝光强度的线性响应变得更接近人眼感受到的响应。具体的定义和实现,还是接着上面代码中读取的图片,执行计算直方图和Gamma变换的代码如下:
import numpy as np
# 分通道计算每个通道的直方图
hist_b = cv2.calcHist([img], [0], None, [256], [0, 256])
hist_g = cv2.calcHist([img], [1], None, [256], [0, 256])
hist_r = cv2.calcHist([img], [2], None, [256], [0, 256])
# 定义Gamma矫正的函数
def gamma_trans(img, gamma):
# 具体做法是先归一化到1,然后gamma作为指数值求出新的像素值再还原
gamma_table = [np.power(x/255.0, gamma)*255.0 for x in range(256)]
gamma_table = np.round(np.array(gamma_table)).astype(np.uint8)
# 实现这个映射用的是OpenCV的查表函数
return cv2.LUT(img, gamma_table)
# 执行Gamma矫正,小于1的值让暗部细节大量提升,同时亮部细节少量提升
img_corrected = gamma_trans(img, 0.5)
cv2.imwrite('gamma_corrected.jpg', img_corrected)
# 分通道计算Gamma矫正后的直方图
hist_b_corrected = cv2.calcHist([img_corrected], [0], None, [256], [0, 256])
hist_g_corrected = cv2.calcHist([img_corrected], [1], None, [256], [0, 256])
hist_r_corrected = cv2.calcHist([img_corrected], [2], None, [256], [0, 256])
# 将直方图进行可视化
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
pix_hists = [
[hist_b, hist_g, hist_r],
[hist_b_corrected, hist_g_corrected, hist_r_corrected]
]
pix_vals = range(256)
for sub_plt, pix_hist in zip([121, 122], pix_hists):
ax = fig.add_subplot(sub_plt, projection='3d')
for c, z, channel_hist in zip(['b', 'g', 'r'], [20, 10, 0], pix_hist):
cs = [c] * 256
ax.bar(pix_vals, channel_hist, zs=z, zdir='y', color=cs, alpha=0.618, edgecolor='none', lw=0)
ax.set_xlabel('Pixel Values')
ax.set_xlim([0, 256])
ax.set_ylabel('Channels')
ax.set_zlabel('Counts')
plt.show()

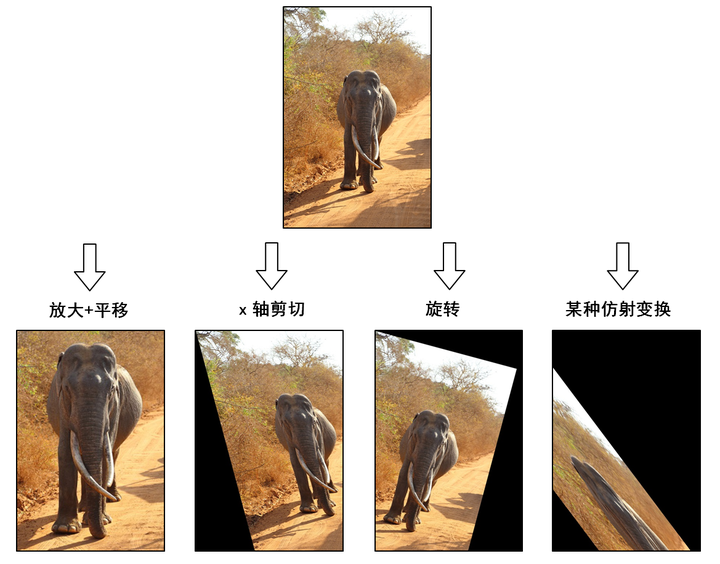
- 图像的仿射变换
图像的仿射变换涉及到图像的形状位置角度的变化,是深度学习预处理中常到的功能,在此简单回顾一下。仿射变换具体到图像中的应用,主要是对图像的缩放,旋转,剪切,翻转和平移的组合。 需要注意的是,对于图像而言,宽度方向是x,高度方向是y,坐标的顺序和图像像素对应下标一致。所以原点的位置不是左下角而是右上角,y的方向也不是向上,而是向下。在OpenCV中实现仿射变换是通过仿射变换矩阵和cv2.warpAffine()这个函数,还是通过代码来理解一下,例子中图片的分辨率为600×400:
import cv2
import numpy as np
# 读取一张斯里兰卡拍摄的大象照片
img = cv2.imread('lanka_safari.jpg')
# 沿着横纵轴放大1.6倍,然后平移(-150,-240),最后沿原图大小截取,等效于裁剪并放大
M_crop_elephant = np.array([
[1.6, 0, -150],
[0, 1.6, -240]
], dtype=np.float32)
img_elephant = cv2.warpAffine(img, M_crop_elephant, (400, 600))
cv2.imwrite('lanka_elephant.jpg', img_elephant)
# x轴的剪切变换,角度15°
theta = 15 * np.pi / 180
M_shear = np.array([
[1, np.tan(theta), 0],
[0, 1, 0]
], dtype=np.float32)
img_sheared = cv2.warpAffine(img, M_shear, (400, 600))
cv2.imwrite('lanka_safari_sheared.jpg', img_sheared)
# 顺时针旋转,角度15°
M_rotate = np.array([
[np.cos(theta), -np.sin(theta), 0],
[np.sin(theta), np.cos(theta), 0]
], dtype=np.float32)
img_rotated = cv2.warpAffine(img, M_rotate, (400, 600))
cv2.imwrite('lanka_safari_rotated.jpg', img_rotated)
# 某种变换,具体旋转+缩放+旋转组合可以通过SVD分解理解
M = np.array([
[1, 1.5, -400],
[0.5, 2, -100]
], dtype=np.float32)
img_transformed = cv2.warpAffine(img, M, (400, 600))
cv2.imwrite('lanka_safari_transformed.jpg', img_transformed)
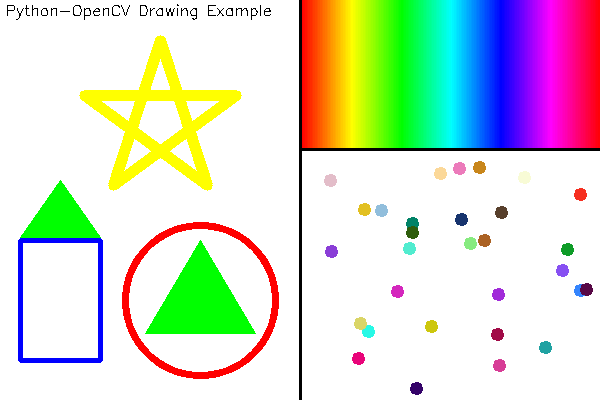
- 基本绘图
import numpy as np
import cv2
# 定义一块宽600,高400的画布,初始化为白色
canvas = np.zeros((400, 600, 3), dtype=np.uint8) + 255
# 画一条纵向的正中央的黑色分界线
cv2.line(canvas, (300, 0), (300, 399), (0, 0, 0), 2)
# 画一条右半部份画面以150为界的横向分界线
cv2.line(canvas, (300, 149), (599, 149), (0, 0, 0), 2)
# 左半部分的右下角画个红色的圆
cv2.circle(canvas, (200, 300), 75, (0, 0, 255), 5)
# 左半部分的左下角画个蓝色的矩形
cv2.rectangle(canvas, (20, 240), (100, 360), (255, 0, 0), thickness=3)
# 定义两个三角形,并执行内部绿色填充
triangles = np.array([
[(200, 240), (145, 333), (255, 333)],
[(60, 180), (20, 237), (100, 237)]])
cv2.fillPoly(canvas, triangles, (0, 255, 0))
# 画一个黄色五角星
# 第一步通过旋转角度的办法求出五个顶点
phi = 4 * np.pi / 5
rotations = [[[np.cos(i * phi), -np.sin(i * phi)], [i * np.sin(phi), np.cos(i * phi)]] for i in range(1, 5)]
pentagram = np.array([[[[0, -1]] + [np.dot(m, (0, -1)) for m in rotations]]], dtype=np.float)
# 定义缩放倍数和平移向量把五角星画在左半部分画面的上方
pentagram = np.round(pentagram * 80 + np.array([160, 120])).astype(np.int)
# 将5个顶点作为多边形顶点连线,得到五角星
cv2.polylines(canvas, pentagram, True, (0, 255, 255), 9)
# 按像素为间隔从左至右在画面右半部份的上方画出HSV空间的色调连续变化
for x in range(302, 600):
color_pixel = np.array([[[round(180*float(x-302)/298), 255, 255]]], dtype=np.uint8)
line_color = [int(c) for c in cv2.cvtColor(color_pixel, cv2.COLOR_HSV2BGR)[0][0]]
cv2.line(canvas, (x, 0), (x, 147), line_color)
# 如果定义圆的线宽大于半斤,则等效于画圆点,随机在画面右下角的框内生成坐标
np.random.seed(42)
n_pts = 30
pts_x = np.random.randint(310, 590, n_pts)
pts_y = np.random.randint(160, 390, n_pts)
pts = zip(pts_x, pts_y)
# 画出每个点,颜色随机
for pt in pts:
pt_color = [int(c) for c in np.random.randint(0, 255, 3)]
cv2.circle(canvas, pt, 3, pt_color, 5)
# 在左半部分最上方打印文字
cv2.putText(canvas,
'Python-OpenCV Drawing Example',
(5, 15),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
(0, 0, 0),
1)
cv2.imshow('Example of basic drawing functions', canvas)
cv2.waitKey()
- 视频功能
视频中最常用的就是从视频设备采集图片或者视频,或者读取视频文件并从中采样。所以比较重要的也是两个模块,一个是VideoCapture,用于获取相机设备并捕获图像和视频,或是从文件中捕获。还有一个VideoWriter,用于生成视频。还是来看例子理解这两个功能的用法,首先是一个制作延时摄影视频的小例子:
import cv2
import time
interval = 60 # 捕获图像的间隔,单位:秒
num_frames = 500 # 捕获图像的总帧数
out_fps = 24 # 输出文件的帧率
# VideoCapture(0)表示打开默认的相机
cap = cv2.VideoCapture(0)
# 获取捕获的分辨率
size =(int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
# 设置要保存视频的编码,分辨率和帧率
video = cv2.VideoWriter(
"time_lapse.avi",
cv2.VideoWriter_fourcc('M','P','4','2'),
out_fps,
size
)
# 对于一些低画质的摄像头,前面的帧可能不稳定,略过
for i in range(42):
cap.read()
# 开始捕获,通过read()函数获取捕获的帧
try:
for i in range(num_frames):
_, frame = cap.read()
video.write(frame)
# 如果希望把每一帧也存成文件,比如制作GIF,则取消下面的注释
# filename = '{:0>6d}.png'.format(i)
# cv2.imwrite(filename, frame)
print('Frame {} is captured.'.format(i))
time.sleep(interval)
except KeyboardInterrupt:
# 提前停止捕获
print('Stopped! {}/{} frames captured!'.format(i, num_frames))
# 释放资源并写入视频文件
video.release()
cap.release()
从视频中截取帧也是处理视频时常见的任务,下面代码实现的是遍历一个指定文件夹下的所有视频并按照指定的间隔进行截屏并保存:
import cv2
import os
import sys
# 第一个输入参数是包含视频片段的路径
input_path = sys.argv[1]
# 第二个输入参数是设定每隔多少帧截取一帧
frame_interval = int(sys.argv[2])
# 列出文件夹下所有的视频文件
filenames = os.listdir(input_path)
# 获取文件夹名称
video_prefix = input_path.split(os.sep)[-1]
# 建立一个新的文件夹,名称为原文件夹名称后加上_frames
frame_path = '{}_frames'.format(input_path)
if not os.path.exists(frame_path):
os.mkdir(frame_path)
# 初始化一个VideoCapture对象
cap = cv2.VideoCapture()
# 遍历所有文件
for filename in filenames:
filepath = os.sep.join([input_path, filename])
# VideoCapture::open函数可以从文件获取视频
cap.open(filepath)
# 获取视频帧数
n_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 同样为了避免视频头几帧质量低下,黑屏或者无关等
for i in range(42):
cap.read()
for i in range(n_frames):
ret, frame = cap.read()
# 每隔frame_interval帧进行一次截屏操作
if i % frame_interval == 0:
imagename = '{}_{}_{:0>6d}.jpg'.format(video_prefix, filename.split('.')[0], i)
imagepath = os.sep.join([frame_path, imagename])
print('exported {}!'.format(imagepath))
cv2.imwrite(imagepath, frame)
# 执行结束释放资源
cap.release()
- 初始化图像对象,用Mat类
Mat M(3,2, CV_8UC3, Scalar(0,0,255));
第一行代码创建一个行数(高度)为 3,列数(宽度)为 2 的图像,图像元素是 8 位无符号整数类型,且有三个通道。图像的所有像素值被初始化为(0, 0, 255)。由于 OpenCV 中默认的颜色顺序为 BGR,因此这是一个全红色的图像。
-
创建多通道图像,使用Mat类
Mat M(3,2, CV_8UC(5));//创建行数为 3,列数为 2,通道数为 5 的图像 -
creat()函数也创建图像对象
Mat M(2,2, CV_8UC3);//构造函数创建图像
M.create(3,2, CV_8UC2);//释放内存重新创建图像
creat()函数无法设置图像像素的初始值
- 彩色,多维图像表示,多维矩阵
Vec3b color; //用 color 变量描述一种 RGB 颜色
color[0]=255; //B 分量
color[1]=0; //G 分量
color[2]=0; //R 分量
- 像素值的读写,at()函数,需要注意的是,如果要遍历图像,并不推荐使用 at()函数。使用这个函数的优点是代码的可读性高,但是效率并不是很高
uchar value = grayim.at<uchar>(i,j);//读出第 i 行第 j 列像素值
grayim.at<uchar>(i,j)=128; //将第 i 行第 j 列像素值设置为 128
如果要对图像进行遍历,可以参考下面的例程。这个例程创建了两个图像,分别是单通道的 grayim 以及 3 个通道的 colorim,然后对两个图像的所有像素值 进行赋值,最后现实结果。以下为代码:
#include <iostream>
#include "opencv2/opencv.hpp"
using namespace std;
using namespace cv;
int main(int argc, char* argv[])
{
Mat grayim(600, 800, CV_8UC1);
Mat colorim(600, 800, CV_8UC3);
//遍历所有像素,并设置像素值
for( int i = 0; i < grayim.rows; ++i)
for( int j = 0; j < grayim.cols; ++j )
grayim.at<uchar>(i,j) = (i+j)%255;
//遍历所有像素,并设置像素值
for( int i = 0; i < colorim.rows; ++i)
for( int j = 0; j < colorim.cols; ++j )
{
Vec3b pixel;
pixel[0] = i%255; //Blue
pixel[1] = j%255; //Green
pixel[2] = 0; //Red
colorim.at<Vec3b>(i,j) = pixel;
}
//显示结果
imshow("grayim", grayim);
imshow("colorim", colorim);
waitKey(0);
return 0;
}
- MatIterator 遍历像素
#include "opencv2/opencv.hpp"
using namespace std;
using namespace cv;
int main(int argc, char* argv[])
{
Mat grayim(600, 800, CV_8UC1);
Mat colorim(600, 800, CV_8UC3);
//遍历所有像素,并设置像素值
MatIterator_<uchar> grayit, grayend;
for( grayit = grayim.begin<uchar>(), grayend =
grayim.end<uchar>(); grayit != grayend; ++grayit)
*grayit = rand()%255;
//遍历所有像素,并设置像素值
MatIterator_<Vec3b> colorit, colorend;
for( colorit = colorim.begin<Vec3b>(), colorend =
colorim.end<Vec3b>(); colorit != colorend; ++colorit)
{
(*colorit)[0] = rand()%255; //Blue
(*colorit)[1] = rand()%255; //Green
(*colorit)[2] = rand()%255; //Red
}
//显示结果
imshow("grayim", grayim);
imshow("colorim", colorim);
waitKey(0);
return 0;
}
-
选取图像某行或某列用函数row()或col()
-
选区图像中的局部区域,Range 类还提供了一个静态方法 all(),这个方法的作用如同 Matlab 中的“:”,表示所有的行或者所有的列
//创建一个单位阵
Mat A = Mat::eye(10, 10, CV_32S);
//提取第 1 到 3 列(不包括 3)
Mat B = A(Range::all(), Range(1, 3));
//提取 B 的第 5 至 9 行(不包括 9)
//其实等价于 C = A(Range(5, 9), Range(1, 3))
Mat C = B(Range(5, 9), Range::all());
- 提取图像的感兴趣区域,用rect()函数,或者Range()对象来选择感兴趣区域
//创建宽度为 320,高度为 240 的 3 通道图像
Mat img(Size(320,240),CV_8UC3);
//roi 是表示 img 中 Rect(10,10,100,100)区域的对象
Mat roi(img, Rect(10,10,100,100));
除了使用构造函数,还可以使用括号运算符, 如下:
Mat roi2 = img(Rect(10,10,100,100));
当然也可以使用 Range 对象来定义感兴趣区域,如下:
//使用括号运算符
Mat roi3 = img(Range(10,100),Range(10,100));
- 读图像文件
Mat imread(const string& filename, int flags=1 )
很明显参数 filename 是被读取或者保存的图像文件名;在 imread()函数中,flag 参数值有三种情况:flag>0,该函数返回 3 通道图像,如果磁盘上的图像文件是单通道的灰度图像,则会被强制转为 3 通道;flag=0,该函数返回单通道图像,如果磁盘的图像文件是多通道图像,则会被强制转为单通道;flag<0,则函数不对图像进行通道转换
- 写图像文件
#include <iostream>
#include "opencv2/opencv.hpp"
using namespace std;
using namespace cv;
int main(int argc, char* argv[])
{
//读入图像,并将之转为单通道图像
Mat im = imread("lena.jpg", 0);
//请一定检查是否成功读图
if( im.empty() )
{
cout << "Can not load image." << endl;
return -1;
}
//进行 Canny 操作,并将结果存于 result
Mat result;
Canny(im, result, 50, 150);
//保存结果
imwrite("lena-canny.png", result);
return 0;
}
- 读视频文件VideoCapture()
#include "opencv2/opencv.hpp"
using namespace std;
using namespace cv;
int main(int argc, char** argv)
{
//打开第一个摄像头
//VideoCapture cap(0);
//打开视频文件
VideoCapture cap("video.short.raw.avi");
//检查是否成功打开
if(!cap.isOpened())
{
cerr << "Can not open a camera or file." << endl;
return -1;
}
Mat edges;
//创建窗口
namedWindow("edges",1);
for(;;)
{
Mat frame;
//从 cap 中读一帧,存到 frame
cap >> frame;
//如果未读到图像
if(frame.empty())
break;
//将读到的图像转为灰度图
cvtColor(frame, edges, CV_BGR2GRAY);
//进行边缘提取操作
Canny(edges, edges, 0, 30, 3);
//显示结果
imshow("edges", edges);
//等待 30 秒,如果按键则推出循环
if(waitKey(30) >= 0)
break;
}
//退出时会自动释放 cap 中占用资源
return 0;
}
- 写视频文件VideoWritter()
使用 OpenCV 创建视频也非常简单,与读视频不同的是,你需要在创建视频时设置一系列参数,包括:文件名,编解码器,帧率,宽度和高度等。编解码器 使用四个字符表示,可以是 CV_FOURCC('M','J','P','G')、 CV_FOURCC('X','V','I','D')及CV_FOURCC('D','I','V','X')等。如果使用某种编解码器无法创建视频文件,请尝试其他的编解码器。将图像写入视频可以使用 VideoWriter::write()函数, VideoWriter 类中也重载了<<操作符,使用起来非常方便。另外需要注意:待写入的图像尺寸必须与创建视频时指定的尺寸一致。下面例程演示了如何写视频文件。本例程将生成一个视频文件,视频的第 0帧上是一个红色的“0”,第 1 帧上是个红色的“1”,以此类推,共 100 帧。
#include <stdio.h>
#include <iostream>
#include "opencv2/opencv.hpp"
using namespace std;
using namespace cv;
int main(int argc, char** argv)
{
//定义视频的宽度和高度
Size s(320, 240);
//创建 writer,并指定 FOURCC 及 FPS 等参数
VideoWriter writer = VideoWriter("myvideo.avi",
CV_FOURCC('M','J','P','G'), 25, s);
//检查是否成功创建
if(!writer.isOpened())
{
cerr << "Can not create video file.\n" << endl;
return -1;
}
//视频帧
Mat frame(s, CV_8UC3);
for(int i = 0; i < 100; i++)
{
//将图像置为黑色
frame = Scalar::all(0);
//将整数 i 转为 i 字符串类型
char text[128];
snprintf(text, sizeof(text), "%d", i);
//将数字绘到画面上
putText(frame, text, Point(s.width/3, s.height/3),
FONT_HERSHEY_SCRIPT_SIMPLEX, 3,
Scalar(0,0,255), 3, 8);
//将图像写入视频
writer << frame;
}
//退出程序时会自动关闭视频文件
return 0;
}