Proxy startup and configuration is required for init_spawners, right? #2749
Comments
|
After #2750 this structure described will change for the better, but there is still something to consider I think. What dynamics are caused by |
|
This is the key misunderstanding:
The Hub probing servers in init_spawners exclusively verifies the Hub's internal state about which spawners are running and where. Only after init_spawners completes is The startup phase:
In JupyterHub 1.0, init_spawners is guaranteed to be complete before the proxy is consulted (or even started, in the default case where the Hub starts the proxy). #2721 complicated this a couple days ago by allowing init_spawners to be incomplete when that first
where was this? It doesn't really make sense to do that. |
I believe that
Lines 1940 to 1951 in 5b13f96 The calls to Lines 1974 to 2000 in 5b13f96 So, if for example |
Yes, and rightly so. The proxy is irrelevant, though, because the Hub always talks to spawners directly. No internal component of JupyterHub ever communicates via the proxy. Thinking about what the check is for: this is the check of what servers are running, in order to determine what the proxy should do. The proxy cannot be a requirement for determining what the proxy's routes should be.
This is what happens very often with jupyterhub upgrades and no users are deleted, because it goes like this:
|
|
Take the default jupyterhub configuration, where the Hub starts the proxy with |
|
@consideRatio discussions like this sound like a great occasion for improving architecture docs! We currently have this overview, but it may not be clear who talks directly to whom and when. This diagram, for instance: attempts to communicate that we have:
Critical points in JupyterHub architecture:
What happens when the Hub is checking if a server is alive? (occurs at startup and as the last stage of spawner start)
|
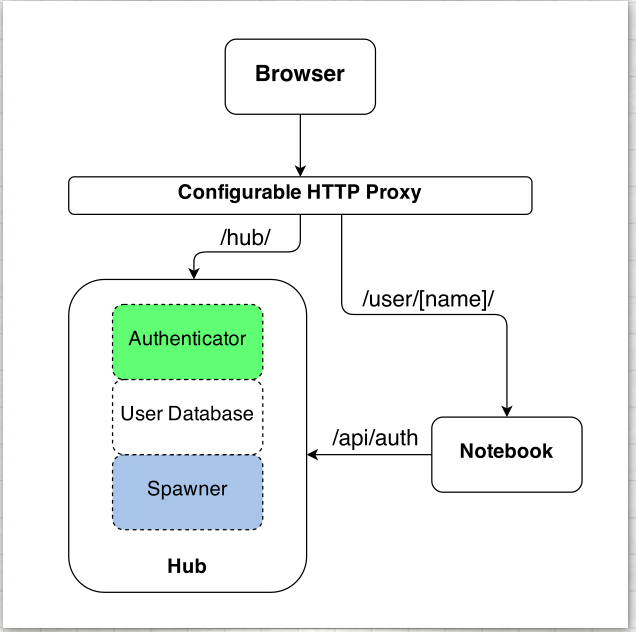
Yes, exactly! This is the condition that is required before the Hub will add the route to the proxy. We can't require that it be in the proxy before we decide if it should be added to the proxy. |
#2726 was my attempt at more, sort of what I learned with technical overview + everything else. Sometime I could make a pass at improving the technical overview too, but how should these two pages relate? For another "JupyterHub for sysadmins" talk I made a more detailed architecture diagram, [here] |
I had a faulty assumption, this is not an issue.
If the hub starts up with a state about running user pods, they will have their individual Spawner objects initialized (
init_spawners) again during startup of jupyterhub. As part of this, they will be probed for a life sign, and if they fail to respond they will be deleted. This user lifesign probe is relying on a proxy is available and configured. And here is the crux, can we be confident we have configured the proxy? I don't think so, that happens incheck_routesbut that is called after theinit_spawnersfunction unless a configurable amount of time passes, because then it will be called earlier in the end of thestartfunction...That was a discussion of configuring the proxy before init_spawners verifications are run, but what if the proxy isn't even started? Well, then its good that it becomes started by the
startfunction which can run after the configurable timeout is reached...The JupyterHub startup phase
Related
Issue about users being deleted when they shouldn't have been: jupyterhub/zero-to-jupyterhub-k8s#1370
The text was updated successfully, but these errors were encountered: