Can't train the model with multi gpus #8227
Comments
|
@CallMeDek 👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |


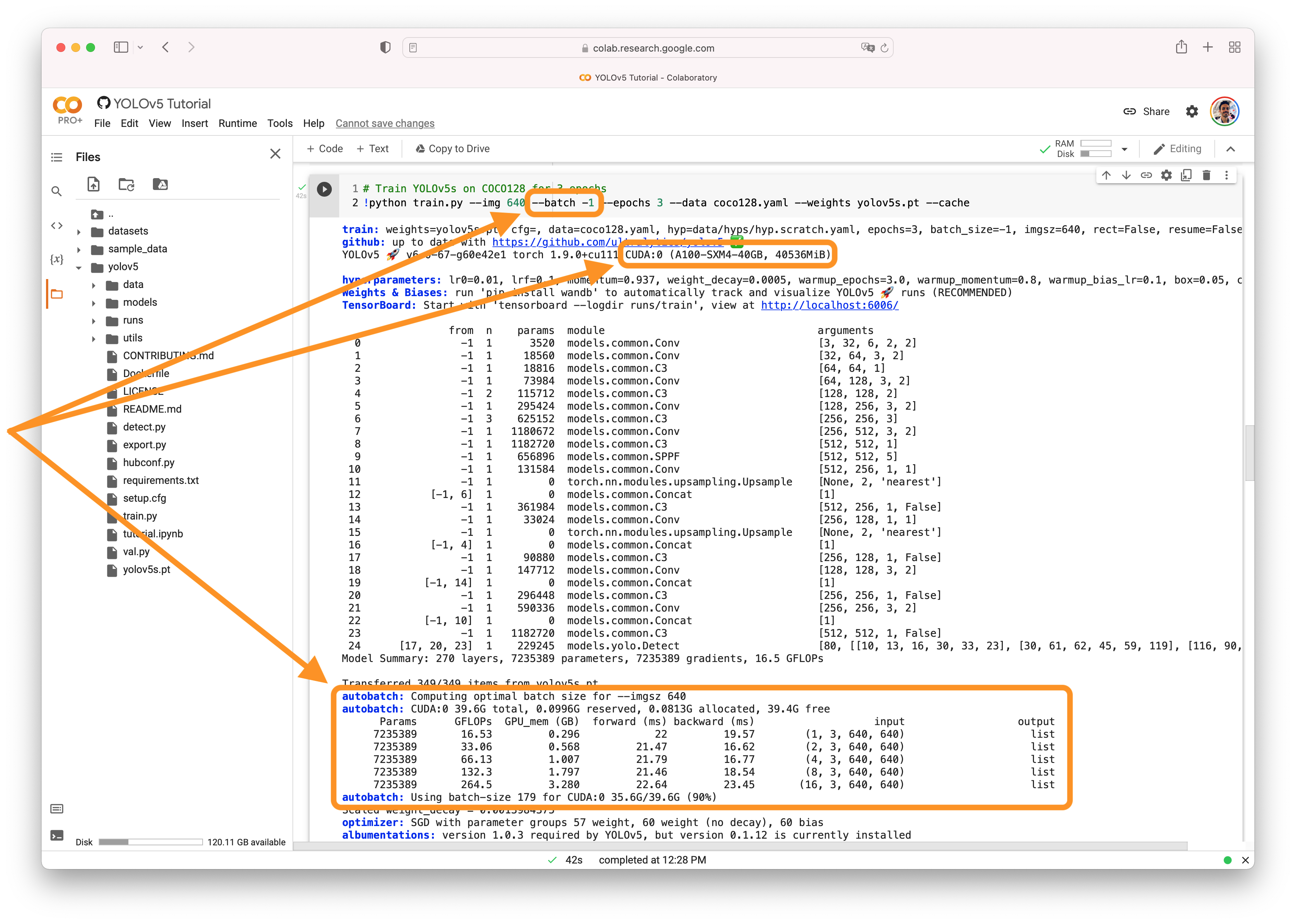
|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
Search before asking
Question
Hi,
I am trying to train my model with 4 gpus.


But I encountered an issue like below.
When I searched this problem, I saw that it is because model parameters of each gpu are different.
So, when I checked, I found out memory usage of them was different.
One thing I don't understand is when I trained the model with images which size is 640 in default config, there was no problem.
Only thing I changed was images(size 1920) and --img 1920 option.
Can you give some tips for this?
Thanks.
Additional
No response
The text was updated successfully, but these errors were encountered: