GPU usage out of memory #9320
Comments
|
👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
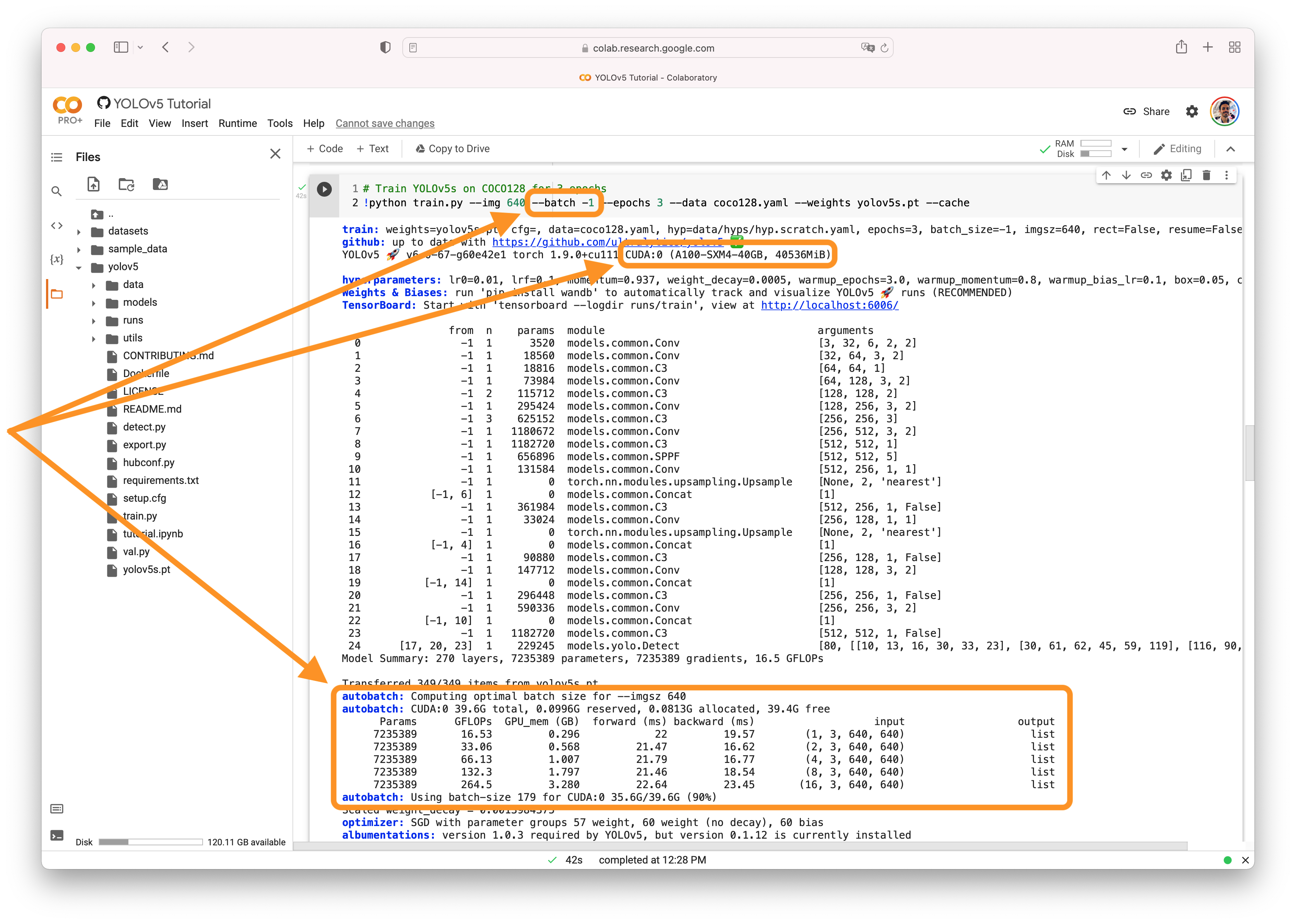
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |


|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
|
Hi, I wanted to know why the value of the gpu_mem is increasing with the passage of the epochs and it's not a constant (or almost constant) value, because every epoch has the same batch size and input size, so the memory usage should be the same, shouldn't it? Also I wanted to know how can we know how many RAM memory is necessary for our training in case, for example, we want to deploy a service on a cluster to train models. |
|
@JesusSilvaUtrera 👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |
|
@glenn-jocher I think he means why the memory is not stable. |
|
@tianlianghai hey there! Great question about why GPU memory usage isn't stable across epochs when using YOLOv5. 🤔 The variation in GPU memory usage can be influenced by several factors even when the batch size and input size remain constant. This might include variations in the complexity of the data being processed in different batches, or differences in memory allocation and caching strategies by PyTorch. The framework dynamically allocates memory and can cache certain computations for efficiency, which might lead to fluctuations in the observed memory usage. If the memory usage progressively increases and leads to out-of-memory errors, it could be a sign of a memory leak. However, if the usage goes up and down but stabilizes without crashing, it's generally part of the normal operation. Feel free to keep an eye on it and adjust training parameters as needed! 🚀 |
Search before asking
YOLOv5 Component
No response
Bug
total classes nc is 7500:
when train mode first GPU usage is as follows:
Epoch gpu_mem box obj cls total labels img_size
0/299 4.11G 0.05746 3.93 65.8
after a moment:
Epoch gpu_mem box obj cls total labels img_size
0/299 8.21G 0.05746 3.93 65.8
and then
Epoch gpu_mem box obj cls total labels img_size
0/299 15.1G 0.05746 3.93 65.8
and then Epoch gpu_mem box obj cls total labels img_size
0/299 18.6 G 0.05746 3.93 65.8
why GPU usage memory is increased,that's unreasonable
and as last rasie gpu out of memory
but when use class number nc =4, it is normal, it is related to the class number? or because of so large class bumber?
after training per epoch,the usage memory increased util raise error GPU out memory, and it is not memory leak because when class number nc=4,it can training normal,except class number nc=7500
Environment
enviroment:
two 3090ti
cuda 11.3
cudnn 8.2.3
pytorch 1.8.1 also try 1.12 ,1.11
Minimal Reproducible Example
No response
Additional
No response
Are you willing to submit a PR?
The text was updated successfully, but these errors were encountered: