队列(Queue):一种线性表数据结构,是一种只允许在表的一端进行插入操作,而在表的另一端进行删除操作的线性表。
我们把队列中允许插入的一端称为 「队尾(rear)」;把允许删除的另一端称为 「队头(front)」。当表中没有任何数据元素时,称之为 「空队」。
队列有两种基本操作:「插入操作」 和 「删除操作」。
- 队列的插入操作又称为「入队」。
- 队列的删除操作又称为「出队」。
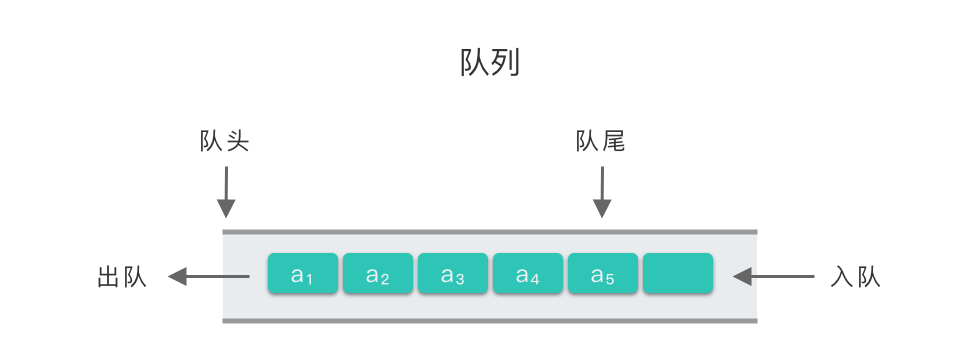
简单来说,队列是一种 「先进先出(First In First Out)」 的线性表,简称为 「FIFO 结构」。
我们可以从两个方面来解释一下队列的定义:
- 第一个方面是 「线性表」。
队列首先是一个线性表,队列中元素具有前驱后继的线性关系。队列中元素按照
- 第二个方面是 「先进先出原则」。
根据队列的定义,最先进入队列的元素在队头,最后进入队列的元素在队尾。每次从队列中删除的总是队头元素,即最先进入队列的元素。也就是说,元素进入队列或者退出队列是按照「先进先出(First In First Out)」的原则进行的。
和线性表类似,队列有两种存储表示方法:「顺序存储的队列」 和 「链式存储的队列」。
-
「顺序存储的队列」:利用一组地址连续的存储单元依次存放队列中从队头到队尾的元素,同时使用指针
$front$ 指向队头元素在队列中的位置,使用指针$rear$ 指示队尾元素在队列中的位置。 -
「链式存储的队列」:利用单链表的方式来实现队列。队列中元素按照插入顺序依次插入到链表的第一个节点之后,并使用队头指针
$front$ 指向链表头节点位置,也就是队头元素,$rear$ 指向链表尾部位置,也就是队尾元素。
注意:$front$ 和
在描述队列的顺序存储与链式存储具体实现之前,我们先来看看队列具有哪些基本操作。
-
初始化空队列:创建一个空队列,定义队列的大小
$size$ ,以及队头元素指针$front$ ,队尾指针$rear$ 。 -
判断队列是否为空:当队列为空时,返回
$True$ 。当队列不为空时,返回$False$ 。一般只用于「出队操作」和「获取队头元素操作」中。 -
判断队列是否已满:当队列已满时,返回
$True$ ,当队列未满时,返回$False$ 。一般只用于顺序队列中插入元素操作中。 -
插入元素(入队):相当于在线性表最后一个数据元素后面插入一个新的数据元素。并改变队尾指针
$rear$ 的指向位置。 -
删除元素(出队):相当于在线性表中删除第一个数据元素。并改变队头指针
$front$ 的指向位置。 -
获取队头元素:相当于获取线性表中第一个数据元素。与插入元素(入队)、删除元素(出队)不同的是,该操作并不改变队头指针
$front$ 的指向位置。 -
获取队尾元素:相当于获取线性表中最后一个数据元素。与插入元素(入队)、删除元素(出队)不同的是,该操作并不改变队尾指针
$rear$ 的指向位置。
接下来我们来看一下队列的顺序存储与链式存储两种不同的实现方式。
队列最简单的实现方式就是借助于一个数组来描述队列的顺序存储结构。在 Python 中我们可以借助列表

为了算法设计上的方便以及算法本身的简单,我们约定:队头指针
-
初始化空队列:创建一个空队列
$self.queue$ ,定义队列大小$self.size$ 。令队头指针$self.front$ 和队尾指针$self.rear$ 都指向$-1$ 。即$self.front = self.rear = -1$ 。 -
判断队列是否为空:根据
$self.front$ 和$self.rear$ 的指向位置关系进行判断。如果队头指针$self.front$ 和队尾指针$self.rear$ 相等,则说明队列为空。否则,队列不为空。 -
判断队列是否已满:如果
$self.rear$ 指向队列最后一个位置,即$self.rear == self.size - 1$ ,则说明队列已满。否则,队列未满。 -
插入元素(入队):先判断队列是否已满,已满直接抛出异常。如果队列不满,则将队尾指针
$self.rear$ 向右移动一位,并进行赋值操作。此时$self.rear$ 指向队尾元素。 -
删除元素(出队):先判断队列是否为空,为空直接抛出异常。如果队列不为空,则将队头指针
$self.front$ 指向元素赋值为$None$ ,并将$self.front$ 向右移动一位。 -
获取队头元素:先判断队列是否为空,为空直接抛出异常。如果队列不为空,因为
$self.front$ 指向队头元素所在位置的前一个位置,所以队头元素在$self.front$ 后面一个位置上,返回$self.queue[self.front + 1]$ 。 -
获取队尾元素:先判断队列是否为空,为空直接抛出异常。如果不为空,因为
$self.rear$ 指向队尾元素所在位置,所以直接返回$self.queue[self.rear]$ 。
class Queue:
# 初始化空队列
def __init__(self, size=100):
self.size = size
self.queue = [None for _ in range(size)]
self.front = -1
self.rear = -1
# 判断队列是否为空
def is_empty(self):
return self.front == self.rear
# 判断队列是否已满
def is_full(self):
return self.rear + 1 == self.size
# 入队操作
def enqueue(self, value):
if self.is_full():
raise Exception('Queue is full')
else:
self.rear += 1
self.queue[self.rear] = value
# 出队操作
def dequeue(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
self.front += 1
return self.queue[self.front]
# 获取队头元素
def front_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
return self.queue[self.front + 1]
# 获取队尾元素
def rear_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
return self.queue[self.rear]在「2.2 队列的顺序存储实现」中,如果队列中第
而由于出队操作总是删除当前的队头元素,将
当队尾指针满足
为了解决「假溢出」问题,有两种做法:
- 第一种:每一次删除队头元素之后,就将整个队列往前移动
$1$ 个位置。其代码如下所示:
# 出队操作
def dequeue(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
value = self.queue[0]
for i in range(self.rear):
self.queue[i] = self.queue[i + 1]
return value这种情况下,队头指针似乎用不到了。因为队头指针总是在队列的第
- 第二种:将队列想象成为头尾相连的循环表,利用数学中的求模运算,使得空间得以重复利用,这样就解决了问题。
在进行插入操作时,如果队列的第
我们约定:$self.size$ 为循环队列的最大元素个数。队头指针
-
插入元素(入队)时:队尾指针循环前进
$1$ 个位置,即$self.rear = (self.rear + 1) \mod self.size$ 。 -
删除元素(出队)时:队头指针循环前进
$1$ 个位置,即$self.front = (self.front + 1) \mod self.size$ 。
注意:
- 循环队列在一开始初始化,队列为空时,满足条件$self.front == self.rear$。
- 而当充满队列后,仍满足条件
$self.front == self.rear$ 。这种情况下就无法判断「队列为空」还是「队列为满」了。
为了区分循环队列中「队列为空」还是「队列已满」的情况,有多种处理方式:
-
方式 1:增加表示队列中元素个数的变量
$self.count$ ,用来以区分队列已满还是队列为空。在入队、出队过程中不断更新元素个数$self.count$ 的值。- 队列已满条件为:队列中元素个数等于队列整体容量,即
$self.count == self.size$ 。 - 队空为空条件为:队列中元素个数等于
$0$ ,即$self.count == 0$ 。
- 队列已满条件为:队列中元素个数等于队列整体容量,即
-
方式 2:增加标记变量
$self.tag$ ,用来以区分队列已满还是队列为空。- 队列已满条件为:$self.tag == 1$ 的情况下,因插入导致
$self.front == self.rear$ 。 - 队列为空条件为:在
$self.tag == 0$ 的情况下,因删除导致$self.front == self.rear$ 。
- 队列已满条件为:$self.tag == 1$ 的情况下,因插入导致
-
方式 3:特意空出来一个位置用于区分队列已满还是队列为空。入队时少用一个队列单元,即约定以「队头指针在队尾指针的下一位置」作为队满的标志。
- 队列已满条件为:队头指针在队尾指针的下一位置,即
$(self.rear + 1) \mod self.size == self.front$ 。 - 队列为空条件为:队头指针等于队尾指针,即
$self.front == self.rear$ 。
- 队列已满条件为:队头指针在队尾指针的下一位置,即
下面我们以「方式 3」中特意空出来一个位置的处理方式为例,对循环队列的顺序存储做一下基本描述。

我们约定:$self.size$ 为循环队列的最大元素个数。队头指针
-
初始化空队列:创建一个空队列,定义队列大小为
$self.size + 1$ 。令队头指针$self.front$ 和队尾指针$self.rear$ 都指向$0$ 。即$self.front = self.rear = 0$ 。 -
判断队列是否为空:根据
$self.front$ 和$self.rear$ 的指向位置进行判断。根据约定,如果队头指针$self.front$ 和队尾指针$self.rear$ 相等,则说明队列为空。否则,队列不为空。 -
判断队列是否已满:队头指针在队尾指针的下一位置,即
$(self.rear + 1) \mod self.size == self.front$ ,则说明队列已满。否则,队列未满。 -
插入元素(入队):先判断队列是否已满,已满直接抛出异常。如果不满,则将队尾指针
$self.rear$ 向右循环移动一位,并进行赋值操作。此时$self.rear$ 指向队尾元素。 -
删除元素(出队):先判断队列是否为空,为空直接抛出异常。如果不为空,则将队头指针
$self.front$ 指向元素赋值为$None$ ,并将$self.front$ 向右循环移动一位。 -
获取队头元素:先判断队列是否为空,为空直接抛出异常。如果不为空,因为
$self.front$ 指向队头元素所在位置的前一个位置,所以队头元素在$self.front$ 后一个位置上,返回$self.queue[(self.front + 1) \mod self.size]$ 。 -
获取队尾元素:先判断队列是否为空,为空直接抛出异常。如果不为空,因为
$self.rear$ 指向队尾元素所在位置,所以直接返回$self.queue[self.rear]$ 。
class Queue:
# 初始化空队列
def __init__(self, size=100):
self.size = size + 1
self.queue = [None for _ in range(size + 1)]
self.front = 0
self.rear = 0
# 判断队列是否为空
def is_empty(self):
return self.front == self.rear
# 判断队列是否已满
def is_full(self):
return (self.rear + 1) % self.size == self.front
# 入队操作
def enqueue(self, value):
if self.is_full():
raise Exception('Queue is full')
else:
self.rear = (self.rear + 1) % self.size
self.queue[self.rear] = value
# 出队操作
def dequeue(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
self.queue[self.front] = None
self.front = (self.front + 1) % self.size
return self.queue[self.front]
# 获取队头元素
def front_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
value = self.queue[(self.front + 1) % self.size]
return value
# 获取队尾元素
def rear_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
value = self.queue[self.rear]
return value对于在使用过程中数据元素变动较大,或者说频繁进行插入和删除操作的数据结构来说,采用链式存储结构比顺序存储结构更加合适。
所以我们可以采用链式存储结构来实现队列。
- 我们用一个线性链表来表示队列,队列中的每一个元素对应链表中的一个链节点。
- 再把线性链表的第
$1$ 个节点定义为队头指针$front$ ,在链表最后的链节点建立指针$rear$ 作为队尾指针。 - 最后限定只能在链表队头进行删除操作,在链表队尾进行插入操作,这样整个线性链表就构成了一个队列。

我们约定:队头指针
-
初始化空队列:建立一个链表头节点
$self.head$ ,令队头指针$self.front$ 和队尾指针$self.rear$ 都指向$head$ 。即$self.front = self.rear = head$ 。 -
判断队列是否为空:根据
$self.front$ 和$self.rear$ 的指向位置进行判断。根据约定,如果队头指针$self.front$ 等于队尾指针$self.rear$ ,则说明队列为空。否则,队列不为空。 -
插入元素(入队):创建值为
$value$ 的链表节点,插入到链表末尾,并令队尾指针$self.rear$ 沿着链表移动$1$ 位到链表末尾。此时$self.rear$ 指向队尾元素。 -
删除元素(出队):先判断队列是否为空,为空直接抛出异常。如果不为空,则获取队头指针
$self.front$ 下一个位置节点上的值,并将$self.front$ 沿着链表移动$1$ 位。如果$self.front$ 下一个位置是$self.rear$ ,则说明队列为空,此时,将$self.rear$ 赋值为$self.front$ ,令其相等。 -
获取队头元素:先判断队列是否为空,为空直接抛出异常。如果不为空,因为
$self.front$ 指向队头元素所在位置的前一个位置,所以队头元素在$self.front$ 后一个位置上,返回$self.front.next.value$ 。 -
获取队尾元素:先判断队列是否为空,为空直接抛出异常。如果不为空,因为
$self.rear$ 指向队尾元素所在位置,所以直接返回$self.rear.value$ 。
class Node:
def __init__(self, value):
self.value = value
self.next = None
class Queue:
# 初始化空队列
def __init__(self):
head = Node(0)
self.front = head
self.rear = head
# 判断队列是否为空
def is_empty(self):
return self.front == self.rear
# 入队操作
def enqueue(self, value):
node = Node(value)
self.rear.next = node
self.rear = node
# 出队操作
def dequeue(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
node = self.front.next
self.front.next = node.next
if self.rear == node:
self.rear = self.front
value = node.value
del node
return value
# 获取队头元素
def front_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
return self.front.next.value
# 获取队尾元素
def rear_value(self):
if self.is_empty():
raise Exception('Queue is empty')
else:
return self.rear.value队列是算法和程序中最常用的辅助结构,其应用十分广泛。比如现实生活中的排队买票、银行办理业务挂号等等。队列在计算机科学领域的应用主要提现在以下两个方面:
- 解决计算机的主机与外部设备之间速度不匹配的问题。
- 比如解决主机与打印机之间速度不匹配问题。主机输出数据给计算机打印,输出数据的速度比打印数据的速度要快很多,如果直接把数据送给打印机进行打印,由于速度不匹配,显然行不通。为此,可以设置一个打印数据缓存队列,将要打印的数据依次写入缓存队列中。然后打印机从缓冲区中按照先进先出的原则依次取出数据并且打印。这样即保证了打印数据的正确,又提高了主机的效率。
- 解决由于多用户引起的系统资源竞争的问题。
- 比如说一个带有多终端的计算机系统,当有多个用户需要各自运行各自的程序时,就分别通过终端向操作系统提出占用 CPU 的请求。操作系统通常按照每个请求在时间上的先后顺序将它们排成一个队列,每次把 CPU 分配给队头请求的用户使用;当相应的程序运行结束或用完规定的时间间隔之后,将其退出队列,再把 CPU 分配给新的队头请求的用户使用。这样既能满足多用户的请求,又能使 CPU 正常运行。
- 再比如 Linux 中的环形缓存、高性能队列 Disruptor,都用到了循环并发队列。iOS 多线程中的 GCD、NSOperationQueue 都用到了队列结构。
- 【书籍】数据结构与算法 Python 语言描述 - 裘宗燕 著
- 【书籍】数据结构教程 第 3 版 - 唐发根 著
- 【书籍】大话数据结构 程杰 著
- 【文章】数据结构之 python 实现队列的链式存储 - 不服输的南瓜的博客
- 【文章】顺序存储的循环队列判空判满判长_- ccxcuixia
- 【文章】队列 - 数据结构与算法之美 - 极客时间