GO语言有接口类型(interface{}),但它与面向对象的接口含义不同,GO语言的接口类型与数组(array)、切片(slice)、集合(map)、结构体(struct)是同等地位的。怎么理解这句话呢?
我们知道:
var num int // 定义了一个int型变量num 同理:go
var any interface{} // 定义了一个接口类型变量从这个角度上看,GO的interface{}与面向对象的接口是不一样的。interface{}是一个任意类型,或者说是万能类型。
也就是说定义一个变量为interface{}类型,可以把任意的值赋给这个变量,例如:
var v1 interface{} = 250 // 把int值赋给interface{}
var v2 interface{} = "eagle" // 把string值赋给interface{}
var v3 interface{} = &v1 // 把v1的地址赋给interface{}当然函数的入参类型也可以是interface{},这样函数就可以接受任意类型的参数,例如GO语言标准库fmt中的函数Println()。
在调用方法的时候,值类型既可以调用值接收者的方法,也可以调用指针接收者的方法;指针类型既可以调用指针接收者的方法,也可以调用值接收者的方法。
也就是说,不管方法的接收者是什么类型,该类型的值和指针都可以调用,不必严格符合接收者的类型。
实现了接收者是值类型的方法,相当于自动实现了接收者是指针类型的方法;而实现了接收者是指针类型的方法,不会自动生成对应接收者是值类型的方法。**即:**实现了接收者是值类型的方法,会隐含地也实现了接收者是指针类型的方法。
如果方法的接收者是值类型,无论调用者是对象还是对象指针,修改的都是对象的副本,不影响调用者;如果方法的接收者是指针类型,则调用者修改的是指针指向的对象本身。
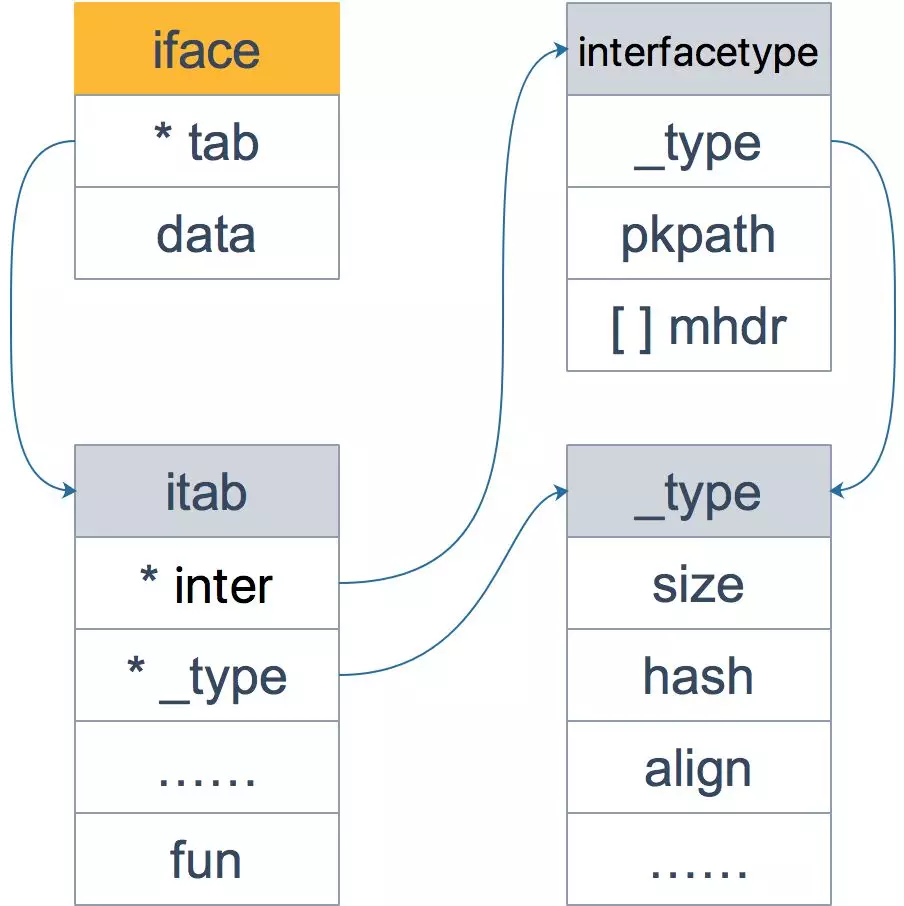
iface描述的接口是包含方法的
// go1.16.2 src/runtime/runtime2.go
type iface struct {
tab *itab // 表示接口的类型以及赋给这个接口的实体类型
data unsafe.Pointer // 指向实际类型的实际值
}// go1.16.2 src/runtime/runtime2.go
type itab struct {
inter *interfacetype // 实际类型实现的接口类型
_type *_type // 描述实体的实际类型(包括内存堆区方式,大小等)
hash uint32
_ [4]byte
fun [1]uintptr // 放置和接口方法对应的实际类型的方法地址
}// go1.16.2 src/runtime/type.go
type interfacetype struct {
typ _type // _type实际上是描述Go语言中各种数据类型的结构体
pkgpath name // 记录定义了接口的包名
mhdr []imethod // 表示接口所定义的函数列表
}// go1.16.2 src/runtime/type.go
type _type struct {
size uintptr // 类型大小
ptrdata uintptr
hash uint32 // 类型的hash
tflag tflag // 类型的flag,和反射相关
align uint8 // 内存对齐相关
fieldAlign uint8
kind uint8 // 类型的编号,有bool,slice,struct等
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte // 和gc相关
str nameOff
ptrToThis typeOff
}iface类型的整体图:
Go 语言各种数据类型都是在 _type 字段的基础上,增加一些额外的字段来进行管理的:
type arraytype struct {
typ _type
elem *_type
slice *_type
len uintptr
}
type chantype struct {
typ _type
elem *_type
dir uintptr
}
type slicetype struct {
typ _type
elem *_type
}
type structtype struct {
typ _type
pkgPath name
fields []structfield
}这些数据类型的结构体定义,是反射实现的基础。
eface描述的则是不包含任何方法的空口interface{}
// go1.16.2 src/runtime/runtime2.go
type eface struct {
_type *_type // 实际类型
data unsafe.Pointer // 实际类型的实际值
}
从源码里可以看到:iface包含两个字段:tab 是接口表指针,指向类型信息;data 是数据指针,则指向具体的数据。它们分别被称为动态类型和动态值。而接口值包括动态类型和动态值。
【引申1】接口类型和 nil 作比较
接口值的零值是指动态类型和动态值都为 nil。当仅且当这两部分的值都为 nil 的情况下,这个接口值就才会被认为 接口值 == nil。
来看个例子:
package main
import "fmt"
type Coder interface {
code()
}
type Gopher struct {
name string
}
func (g Gopher) code() {
fmt.Printf("%s is coding\n", g.name)
}
func main() {
var c Coder
fmt.Println(c == nil)
fmt.Printf("c: %T, %v\n", c, c)
var g *Gopher
fmt.Println(g == nil)
c = g
fmt.Println(c == nil)
fmt.Printf("c: %T, %v\n", c, c)
}输出:
true
c: <nil>, <nil>
true
false
c: *main.Gopher, <nil>
一开始,c 的 动态类型和动态值都为 nil,g 也为 nil,当把 g 赋值给 c 后,c 的动态类型变成了 *main.Gopher,仅管 c 的动态值仍为 nil,但是当 c 和 nil 作比较的时候,结果就是 false 了。
【引申2】 来看一个例子,看一下它的输出:
package main
import "fmt"
type MyError struct {}
func (i MyError) Error() string {
return "MyError"
}
func main() {
err := Process()
fmt.Println(err)
fmt.Println(err == nil)
}
func Process() error {
var err *MyError = nil
return err
}函数运行结果:
<nil>
false
这里先定义了一个 MyError 结构体,实现了 Error 函数,也就实现了 error 接口。Process 函数返回了一个 error 接口,这块隐含了类型转换。所以,虽然它的值是 nil,其实它的类型是 *MyError,最后和 nil 比较的时候,结果为 false。
【引申3】如何打印出接口的动态类型和值?
直接看代码:
package main
import (
"unsafe"
"fmt"
)
type iface struct {
itab, data uintptr
}
func main() {
var a interface{} = nil
var b interface{} = (*int)(nil)
x := 5
var c interface{} = (*int)(&x)
ia := *(*iface)(unsafe.Pointer(&a))
ib := *(*iface)(unsafe.Pointer(&b))
ic := *(*iface)(unsafe.Pointer(&c))
fmt.Println(ia, ib, ic)
fmt.Println(*(*int)(unsafe.Pointer(ic.data)))
}代码里直接定义了一个 iface 结构体,用两个指针来描述 itab 和 data,之后将 a, b, c 在内存中的内容强制解释成我们自定义的 iface。最后就可以打印出动态类型和动态值的地址。
运行结果如下:
{0 0} {17426912 0} {17426912 842350714568}
5
a 的动态类型和动态值的地址均为 0,也就是 nil;b 的动态类型和 c 的动态类型一致,都是 *int;最后,c 的动态值为 5。
我们知道,Go 语言中不允许隐式类型转换,也就是说 = 两边,不允许出现类型不相同的变量。
类型转换、类型断言本质都是把一个类型转换成另外一个类型。不同之处在于,类型断言是对接口变量进行的操作。
对于类型转换而言,转换前后的两个类型要相互兼容才行。类型转换的语法为:
<结果类型> := <目标类型> ( <表达式> )
package main
import "fmt"
func main() {
var i int = 9
var f float64
f = float64(i)
fmt.Printf("%T, %v\n", f, f)
f = 10.8
a := int(f)
fmt.Printf("%T, %v\n", a, a)
// s := []int(i)
}上面的代码里,我定义了一个 int 型和 float64 型的变量,尝试在它们之前相互转换,结果是成功的:int 型和 float64 是相互兼容的。
如果我把最后一行代码的注释去掉,编译器会报告类型不兼容的错误:
cannot convert i (type int) to type []int前面说过,因为空接口 interface{} 没有定义任何函数,因此 Go 中所有类型都实现了空接口。当一个函数的形参是 interface{},那么在函数中,需要对形参进行断言,从而得到它的真实类型。
断言的语法为:
<目标类型的值>,<布尔参数> := <表达式>.( 目标类型 ) // 安全类型断言 <目标类型的值> := <表达式>.( 目标类型 ) //非安全类型断言
类型转换和类型断言有些相似,不同之处,在于类型断言是对接口进行的操作。
还是来看一个简短的例子:
package main
import "fmt"
type Student struct {
Name string
Age int
}
func main() {
var i interface{} = new(Student)
s := i.(Student)
fmt.Println(s)
}运行一下:
panic: interface conversion: interface {} is *main.Student, not main.Student
直接 panic 了,这是因为 i 是 *Student 类型,并非 Student 类型,断言失败。这里直接发生了 panic,线上代码可能并不适合这样做,可以采用“安全断言”的语法:
func main() {
var i interface{} = new(Student)
s, ok := i.(Student)
if ok {
fmt.Println(s)
}
}这样,即使断言失败也不会 panic。
断言其实还有另一种形式,就是用在利用 switch 语句判断接口的类型。每一个 case 会被顺序地考虑。当命中一个 case 时,就会执行 case 中的语句,因此 case 语句的顺序是很重要的,因为很有可能会有多个 case 匹配的情况。
代码示例如下:
func main() {
//var i interface{} = new(Student)
//var i interface{} = (*Student)(nil)
var i interface{}
fmt.Printf("%p %v\n", &i, i)
judge(i)
}
func judge(v interface{}) {
fmt.Printf("%p %v\n", &v, v)
switch v := v.(type) {
case nil:
fmt.Printf("%p %v\n", &v, v)
fmt.Printf("nil type[%T] %v\n", v, v)
case Student:
fmt.Printf("%p %v\n", &v, v)
fmt.Printf("Student type[%T] %v\n", v, v)
case *Student:
fmt.Printf("%p %v\n", &v, v)
fmt.Printf("*Student type[%T] %v\n", v, v)
default:
fmt.Printf("%p %v\n", &v, v)
fmt.Printf("unknow\n")
}
}
type Student struct {
Name string
Age int
}main 函数里有三行不同的声明,每次运行一行,注释另外两行,得到三组运行结果:
// --- var i interface{} = new(Student)
0xc4200701b0 [Name: ], [Age: 0]
0xc4200701d0 [Name: ], [Age: 0]
0xc420080020 [Name: ], [Age: 0]
*Student type[*main.Student] [Name: ], [Age: 0]
// --- var i interface{} = (*Student)(nil)
0xc42000e1d0 <nil>
0xc42000e1f0 <nil>
0xc42000c030 <nil>
*Student type[*main.Student] <nil>
// --- var i interface{}
0xc42000e1d0 <nil>
0xc42000e1e0 <nil>
0xc42000e1f0 <nil>
nil type[<nil>] <nil>对于第一行语句:
var i interface{} = new(Student)i 是一个 *Student 类型,匹配上第三个 case,从打印的三个地址来看,这三处的变量实际上都是不一样的。在 main 函数里有一个局部变量 i;调用函数时,实际上是复制了一份参数,因此函数里又有一个变量 v,它是 i 的拷贝;断言之后,又生成了一份新的拷贝。所以最终打印的三个变量的地址都不一样。
对于第二行语句:
var i interface{} = (*Student)(nil)这里想说明的其实是 i 在这里动态类型是 (*Student), 数据为 nil,它的类型并不是 nil,它与 nil 作比较的时候,得到的结果也是 false。
最后一行语句:
var i interface{}这回 i 才是 nil 类型。
【引申1】
fmt.Println 函数的参数是 interface。对于内置类型,函数内部会用穷举法,得出它的真实类型,然后转换为字符串打印。而对于自定义类型,首先确定该类型是否实现了 String() 方法,如果实现了,则直接打印输出 String() 方法的结果;否则,会通过反射来遍历对象的成员进行打印。
再来看一个简短的例子,比较简单,不要紧张:
package main
import "fmt"
type Student struct {
Name string
Age int
}
func main() {
var s = Student{
Name: "qcrao",
Age: 18,
}
fmt.Println(s)
}因为 Student 结构体没有实现 String() 方法,所以 fmt.Println 会利用反射挨个打印成员变量:
{qcrao 18}
增加一个 String() 方法的实现:
func (s Student) String() string {
return fmt.Sprintf("[Name: %s], [Age: %d]", s.Name, s.Age)
}打印结果:
[Name: qcrao], [Age: 18]
按照我们自定义的方法来打印了。
【引申2】 针对上面的例子,如果改一下:
func (s *Student) String() string {
return fmt.Sprintf("[Name: %s], [Age: %d]", s.Name, s.Age)
}注意看两个函数的接受者类型不同,现在 Student 结构体只有一个接受者类型为 指针类型 的 String() 函数,打印结果:
{qcrao 18}
为什么?
类型 T 只有接受者是 T 的方法;而类型 *T 拥有接受者是 T 和 *T 的方法。语法上 T 能直接调 *T 的方法仅仅是 Go 的语法糖。
所以, Student 结构体定义了接受者类型是值类型的 String() 方法时,通过
fmt.Println(s)
fmt.Println(&s)均可以按照自定义的格式来打印。
如果 Student 结构体定义了接受者类型是指针类型的 String() 方法时,只有通过
fmt.Println(&s)才能按照自定义的格式打印。
通过前面提到的 iface 的源码可以看到,实际上它包含接口的类型 interfacetype 和 实体类型的类型 _type,这两者都是 iface 的字段 itab 的成员。也就是说生成一个 itab 同时需要接口的类型和实体的类型。
<interface 类型, 实体类型> ->itable
当判定一种类型是否满足某个接口时,Go 使用类型的方法集和接口所需要的方法集进行匹配,如果类型的方法集完全包含接口的方法集,则可认为该类型实现了该接口。
例如某类型有 m 个方法,某接口有 n 个方法,则很容易知道这种判定的时间复杂度为 O(mn),Go 会对方法集的函数按照函数名的字典序进行排序,所以实际的时间复杂度为 O(m+n)。
这里我们来探索将一个接口转换给另外一个接口背后的原理,当然,能转换的原因必然是类型兼容。
直接来看一个例子:
package main
import "fmt"
type coder interface {
code()
run()
}
type runner interface {
run()
}
type Gopher struct {
language string
}
func (g Gopher) code() {
return
}
func (g Gopher) run() {
return
}
func main() {
var c coder = Gopher{}
var r runner
r = c
fmt.Println(c, r)
}简单解释下上述代码:定义了两个 interface: coder 和 runner。定义了一个实体类型 Gopher,类型 Gopher 实现了两个方法,分别是 run() 和 code()。main 函数里定义了一个接口变量 c,绑定了一个 Gopher 对象,之后将 c 赋值给另外一个接口变量 r 。赋值成功的原因是 c 中包含 run() 方法。这样,两个接口变量完成了转换。
执行命令:
go tool compile -S ./src/main.go得到 main 函数的汇编命令,可以看到: r = c 这一行语句实际上是调用了 runtime.convI2I(SB),也就是 convI2I 函数,从函数名来看,就是将一个 interface 转换成另外一个 interface,看下它的源代码:
func convI2I(inter *interfacetype, i iface) (r iface) {
tab := i.tab
if tab == nil {
return
}
if tab.inter == inter {
r.tab = tab
r.data = i.data
return
}
r.tab = getitab(inter, tab._type, false)
r.data = i.data
return
}代码比较简单,函数参数 inter 表示接口类型,i 表示绑定了实体类型的接口,r 则表示接口转换了之后的新的 iface。通过前面的分析,我们又知道, iface 是由 tab 和 data 两个字段组成。所以,实际上 convI2I 函数真正要做的事,找到新 interface 的 tab 和 data,就大功告成了。
我们还知道,tab 是由接口类型 interfacetype 和 实体类型 _type 组成。所以最关键的语句是 r.tab = getitab(inter, tab._type, false)。
因此,重点来看下 getitab 函数的源码,只看关键的地方:
func getitab(inter *interfacetype, typ *_type, canfail bool) *itab {
// ……
// 根据 inter, typ 计算出 hash 值
h := itabhash(inter, typ)
// look twice - once without lock, once with.
// common case will be no lock contention.
var m *itab
var locked int
for locked = 0; locked < 2; locked++ {
if locked != 0 {
lock(&ifaceLock)
}
// 遍历哈希表的一个 slot
for m = (*itab)(atomic.Loadp(unsafe.Pointer(&hash[h]))); m != nil; m = m.link {
// 如果在 hash 表中已经找到了 itab(inter 和 typ 指针都相同)
if m.inter == inter && m._type == typ {
// ……
if locked != 0 {
unlock(&ifaceLock)
}
return m
}
}
}
// 在 hash 表中没有找到 itab,那么新生成一个 itab
m = (*itab)(persistentalloc(unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*sys.PtrSize, 0, &memstats.other_sys))
m.inter = inter
m._type = typ
// 添加到全局的 hash 表中
additab(m, true, canfail)
unlock(&ifaceLock)
if m.bad {
return nil
}
return m
}简单总结一下:getitab 函数会根据 interfacetype 和 _type 去全局的 itab 哈希表中查找,如果能找到,则直接返回;否则,会根据给定的 interfacetype 和 _type 新生成一个 itab,并插入到 itab 哈希表,这样下一次就可以直接拿到 itab。
这里查找了两次,并且第二次上锁了,这是因为如果第一次没找到,在第二次仍然没有找到相应的 itab 的情况下,需要新生成一个,并且写入哈希表,因此需要加锁。这样,其他协程在查找相同的 itab 并且也没有找到时,第二次查找时,会被挂住,之后,就会查到第一个协程写入哈希表的 itab。
再来看一下 additab 函数的代码:
// 检查 _type 是否符合 interface_type 并且创建对应的 itab 结构体 将其放到 hash 表中
func additab(m *itab, locked, canfail bool) {
inter := m.inter
typ := m._type
x := typ.uncommon()
// both inter and typ have method sorted by name,
// and interface names are unique,
// so can iterate over both in lock step;
// the loop is O(ni+nt) not O(ni*nt).
//
// inter 和 typ 的方法都按方法名称进行了排序
// 并且方法名都是唯一的。所以循环的次数是固定的
// 只用循环 O(ni+nt),而非 O(ni*nt)
ni := len(inter.mhdr)
nt := int(x.mcount)
xmhdr := (*[1 << 16]method)(add(unsafe.Pointer(x), uintptr(x.moff)))[:nt:nt]
j := 0
for k := 0; k < ni; k++ {
i := &inter.mhdr[k]
itype := inter.typ.typeOff(i.ityp)
name := inter.typ.nameOff(i.name)
iname := name.name()
ipkg := name.pkgPath()
if ipkg == "" {
ipkg = inter.pkgpath.name()
}
for ; j < nt; j++ {
t := &xmhdr[j]
tname := typ.nameOff(t.name)
// 检查方法名字是否一致
if typ.typeOff(t.mtyp) == itype && tname.name() == iname {
pkgPath := tname.pkgPath()
if pkgPath == "" {
pkgPath = typ.nameOff(x.pkgpath).name()
}
if tname.isExported() || pkgPath == ipkg {
if m != nil {
// 获取函数地址,并加入到itab.fun数组中
ifn := typ.textOff(t.ifn)
*(*unsafe.Pointer)(add(unsafe.Pointer(&m.fun[0]), uintptr(k)*sys.PtrSize)) = ifn
}
goto nextimethod
}
}
}
// ……
m.bad = true
break
nextimethod:
}
if !locked {
throw("invalid itab locking")
}
// 计算 hash 值
h := itabhash(inter, typ)
// 加到Hash Slot链表中
m.link = hash[h]
m.inhash = true
atomicstorep(unsafe.Pointer(&hash[h]), unsafe.Pointer(m))
}additab 会检查 itab 持有的 interfacetype 和 _type 是否符合,就是看 _type 是否完全实现了 interfacetype 的方法,也就是看两者的方法列表重叠的部分就是 interfacetype 所持有的方法列表。注意到其中有一个双层循环,乍一看,循环次数是 ni * nt,但由于两者的函数列表都按照函数名称进行了排序,因此最终只执行了 ni + nt 次,代码里通过一个小技巧来实现:第二层循环并没有从 0 开始计数,而是从上一次遍历到的位置开始。
求 hash 值的函数比较简单:
func itabhash(inter *interfacetype, typ *_type) uint32 {
h := inter.typ.hash
h += 17 * typ.hash
return h % hashSize
}hashSize 的值是 1009。
更一般的,当把实体类型赋值给接口的时候,会调用 conv 系列函数,例如空接口调用 convT2E 系列、非空接口调用 convT2I 系列。这些函数比较相似:
- 具体类型转空接口时,_type 字段直接复制源类型的 _type;调用 mallocgc 获得一块新内存,把值复制进去,data 再指向这块新内存。
- 具体类型转非空接口时,入参 tab 是编译器在编译阶段预先生成好的,新接口 tab 字段直接指向入参 tab 指向的 itab;调用 mallocgc 获得一块新内存,把值复制进去,data 再指向这块新内存。
- 而对于接口转接口,itab 调用 getitab 函数获取。只用生成一次,之后直接从 hash 表中获取。
Reference: