The keyword extraction technique will sift through the whole set of data in minutes and obtain the words and phrases that best describe each subject. This way, you can easily identify which parts of the available data cover the subjects you are looking for while saving your teams many hours of manual processing.
Streamlit app: https://keywordextract.streamlit.app/
-
Python version 3.9.6
-
Clone this repo to your local machine
-
make virtualenv (recommended)
-
open and change terminal location to the project directory
-
run the below command after activating the virtualenv
pip install -r requirement.txt -
now run the below command
streamlit run main.py
The following text will be shown
$ streamlit run main.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.0.105:8501
Open a browser with the local URL given in a terminal
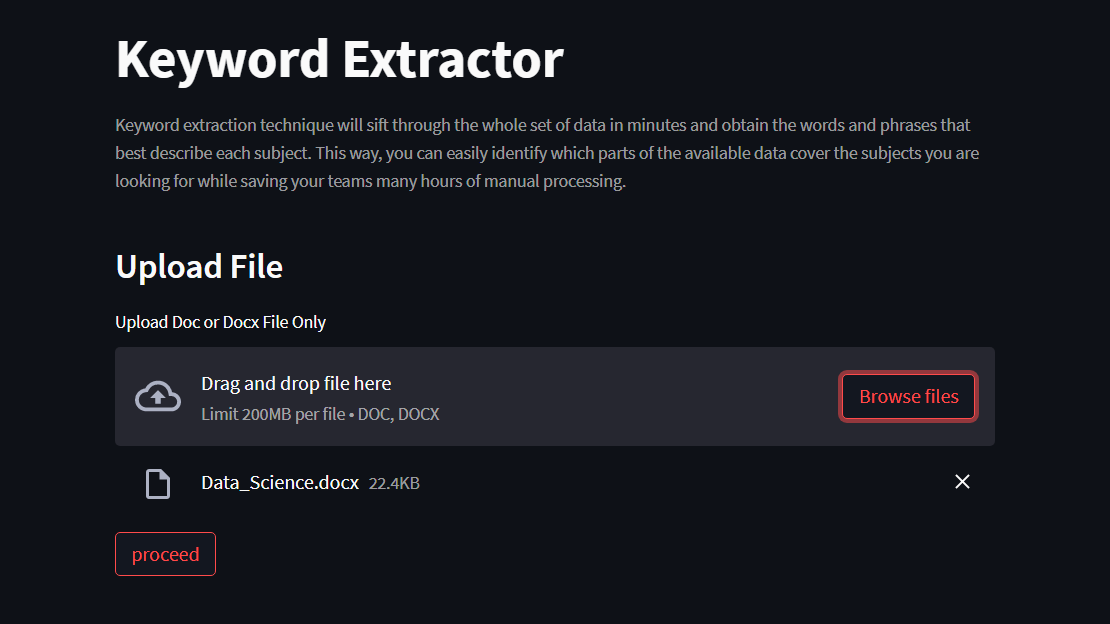
- Below is the home page of the keyword Extractor Streamlit app

- you can upload doc/docx file (max 200mb)
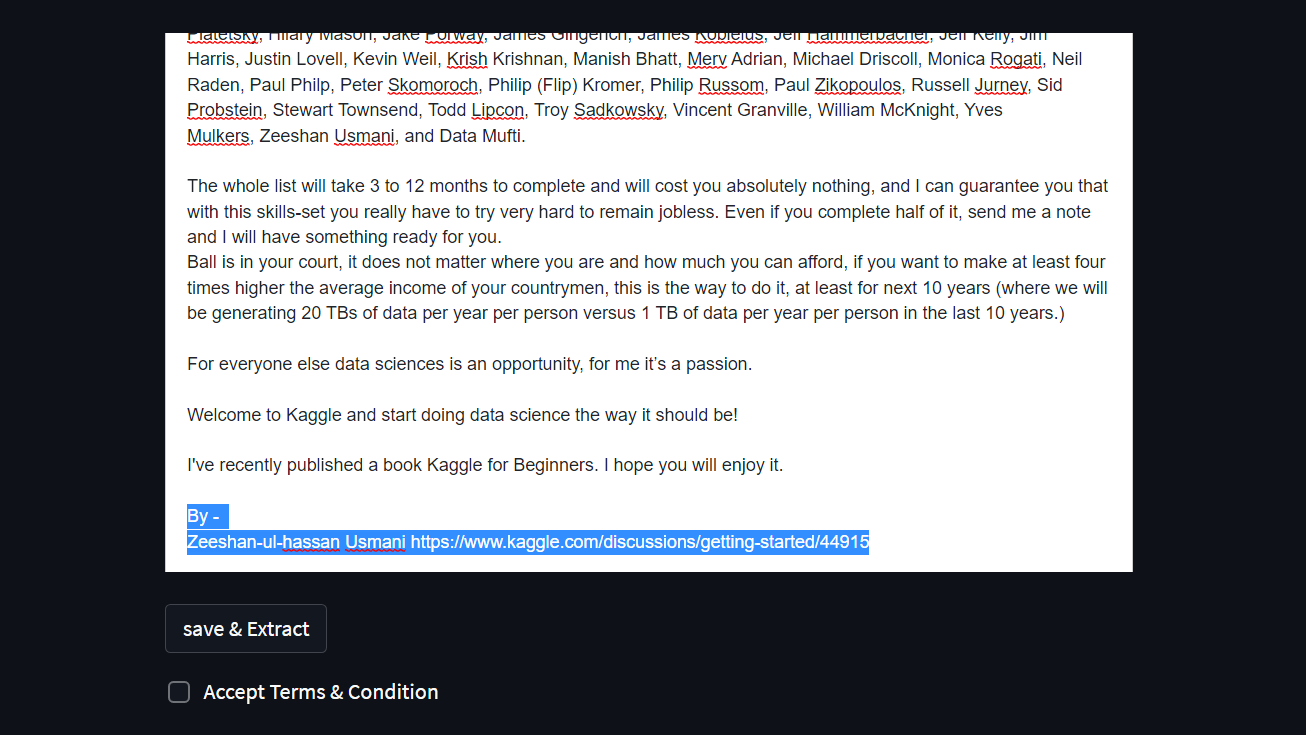
- process the file and edit it online
- Apply keyword extraction to the edited doc file and download it as a PDF/DOC file.
- For now, only spacy with textrank,Rake and tf-idf are implemented.
Currently using Spacy with textrank layer
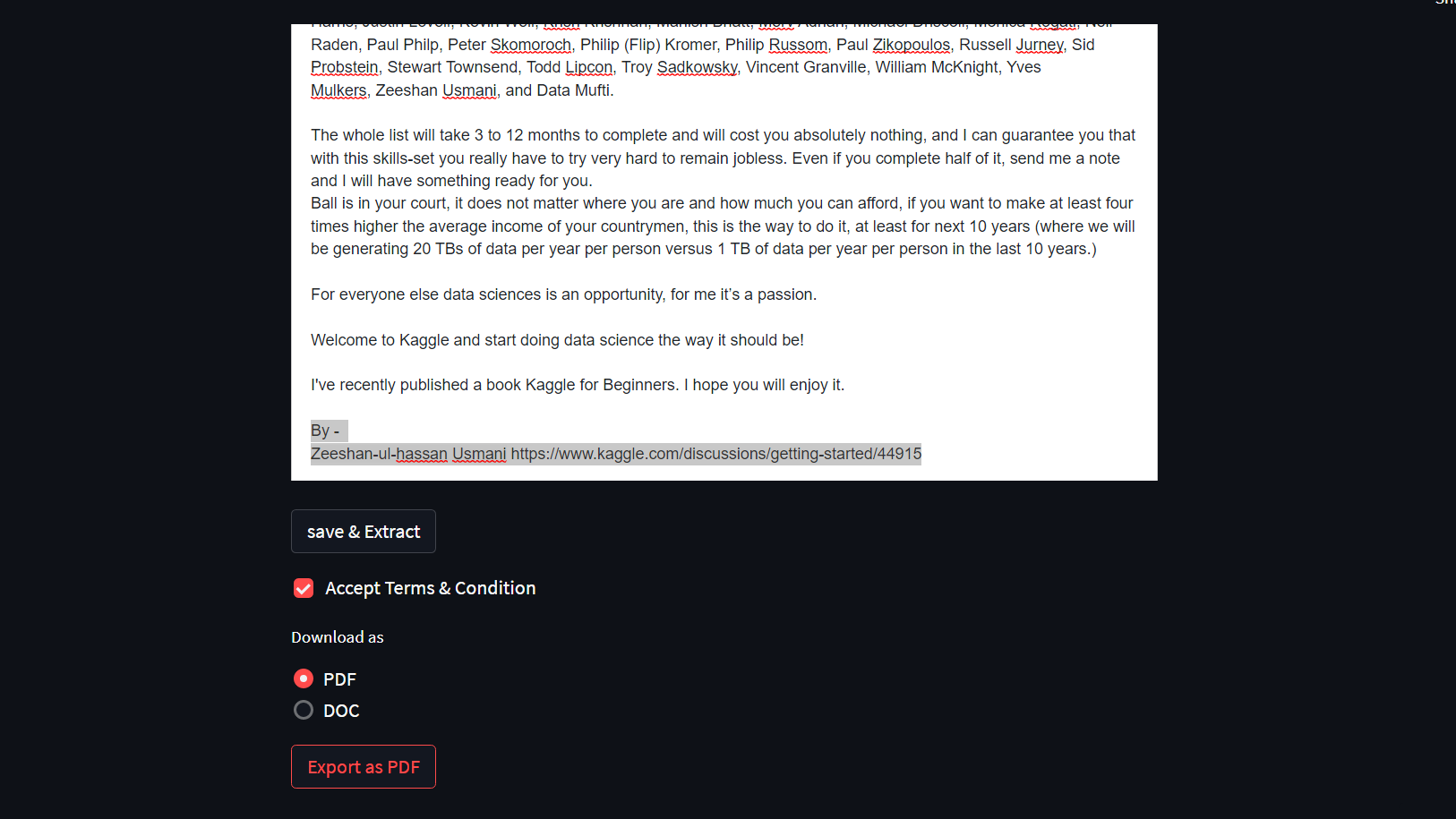
- The kewords will be appended to the last of the downloaded document.

Data preprocessing is an essential step in building a Machine Learning model and depending on how well the data has been preprocessed; the results are seen.
In NLP, text preprocessing is the first step in the process of building a model.
The various text preprocessing steps are:
Tokenization Lower casing Stop words removal Stemming Lemmatization These various text preprocessing steps are widely used for dimensionality reduction.
Learn more about - Text Preprocessing in Natural Language Processing
- If you have better idea and want to update this tool. please contribute to this project.