The MegEngine version implemention for RepVGG.
[2022.01.08] BaseCls提供了MegEngine版本RepVGG的预训练模型,本次更新提供脚本转换权重及转换好的权重; 修复了switch to deploy时赋值失败的错误。
[2021.11.06] 修改了导包时的命名错误和图像预处理方案;将训练策略修改为余弦退火;增加了断点续炼的功能。
- 使用DTR优化;
- 量化。
- 提出了一种简单强大的CNN,推理时其拥有VGG类似的plain结构,仅由卷积和ReLU组成;训练时拥有多分支的拓扑结构
- 得益于结构重参化(re-parameterization)技术,RepVGG运行速度比ResNet-50快83%,比ResNet-101快101%,并且具有更高的精度。
随着CNN在计算机视觉领域的成功,网络结构越来越复杂。这些复杂的结构相较于plain的网络结构虽然能够提供更高的精度,然是其缺点也是显而易见的:
- 复杂的多分支结构,各种各样的残差连接和concatenation增加了网络实现和修改难度,降低了推理速度和内存利用效率;
- 某些模块如深度卷积、channel shuffle等增加了内存访问的成本;
推理时间受到各种因素的影响,浮点运算(FLOPs)并不能准确反映实际速度,实际上VGG和NesNet在工业界还在大量使用着。而本文提出的RepVGG有以下优势:
- 与VGG相同的plain结构,没有任何分支;
- 只使用$3\times 3$卷积;
- 具体的架构没有使用自动搜索、手动优化、复合缩放等繁重的操作,仅仅使用了重参化。
-
快速
很多网络拥有用比VGG更小的理论浮点计算量(FLOPs),但是其实际推理速度并没有VGG快速,FlOPs不能代表网络的计算速度。
计算速度主要与两个重要因素有关:
- 内存访问成本(MAC):虽然残差连接和concatenation几乎可以忽略不计,但是其提高了内存访问成本(残差连接需要提高一倍的内存占用),此外,组卷积也会提高时间;
- 并行度:并行度是另一个重要因素,Inseption和一些自动搜索架构使用了很多小操作(small operators),这大大降低了网络的并行度。
-
内存经济
对于多分支的网络拓扑结构,每个分支的输出都必须保留,直到addition或concatenation操作完成,这会大大提高内存占用,如下图:
而plain的网络结构能够及时释放内存,并且设计专门的硬件时可以将更多的计算单元集成到芯片上。
-
灵活

多分支的网络结构限制了本身的灵活性,很难进行修改,牵一发而动全身,并且剪枝技术也受到很多限制。相比之下,plain结构允许我们根据需求自由配置各层,并进行修剪以获得更好的性能效率权衡。
plain的网络结构有一个致命的缺点——性能差,使用BN层的情况下,VGG-16仅仅能达到72% top-1准确率;
受到ResNet的启发,使用一个$y=x+f(x)$,当$x、f(x)$不匹配时,使用$1\times 1$的卷积层,则$y=g(x)+f(x)$;
ResNet成功的一个解释是,这种多分支的结构使得网络成为各个浅层模型的隐式集成,具体来说,有n个Block时,模型可以被解释为$2^n$个模型的集合,因为每个块将流分成两条路径。
虽然多分支结构在推理方面存在缺陷,但是其十分有利于训练;于是构建了一个$y=x+g(x)+f(x)$的结构,堆叠了n层,从上述可知,这意味着$3^n$个模型的集合。
本文即是选择这样的折中办法,训练时使用多分支,而推理时使用单分支。
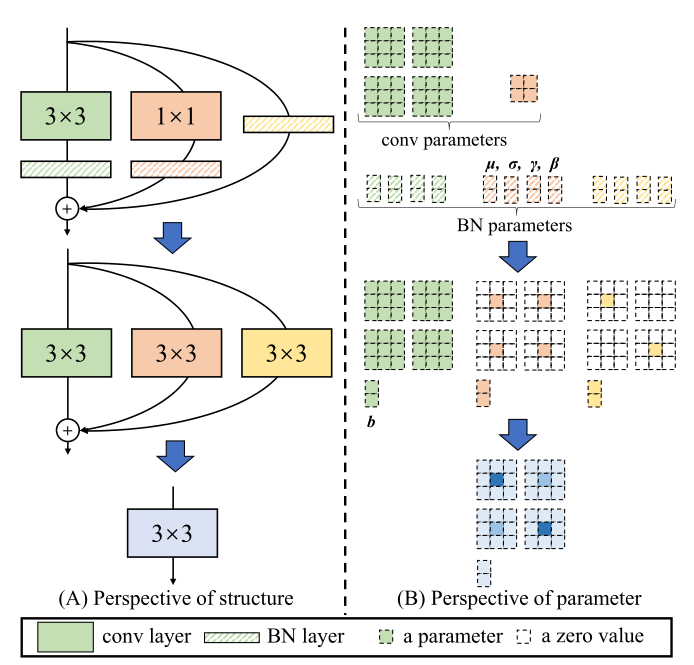
推理之前会进行重参数化,RepVGG的模块结构如上图所示,由$3\times 3,1\times 1,identity$组成,将这些全部变为$3\times3$卷积相加即可实现ReP。
identity:将$3\times3$矩阵中心赋值为1,其余为0
BN:
设卷积$Conv(x)=W(x)+b$,BN为$BN(x)=\gamma\frac{(x-mean)}{\sqrt{var}}+\beta$
带入可得: $$ \begin{align} BN(Conv(x))&=\gamma\frac{(W(x)+b-mean)}{\sqrt{var}}+\beta\&=\frac{\gammaW(x)}{\sqrt{var}}+(\frac{\gamma(b-mean)}{\sqrt{var}}+\beta) \end{align} $$ 注意后面为卷积的偏置项
这里BN的running_mean和running_var是从开始训练就一直记录的,并且其计算场景是online的,因为事先不知道会有多少数据,所以只能每次增量计算。计算公式为:
$$
mean_{t}=\frac{\sum_{i=1}^{t}x_i}{N_t}=\frac{mean_{t-1}\cdot(N_{t-1}+x_t)}{N_t}=mean_{t-1}+\frac{1}{N_t}(x_i-mean_{t-1})
$$
而在推理时,BN层则会固定这些参数,这也是我们能够融合CONVBN的原因。
├── README.md
├── models/ # 模型定义
├── utils.py #工具
├── train.py # 训练
├── test.py # 评估
├── verify.py # 验证模型搭建正确与否
├── convert_pretrained_weight.py # 用于转换预训练权重
python verify.pypython train.py --help python train.py --data /path/to/data/ --arch RepVGGA0 --save checkpoints --ngpus 4 --batch-size 256 --print-freq 20受限于算力,目前只测试了RepVGG-A0。
| Model | Top1-acc | Top2-acc | Pretained Model | Converted Model |
|---|---|---|---|---|
| RepVGG-A0 | 72.254 | 90.494 | here | here |
| RepVGG-A1 | here | here | ||
| RepVGG-B0 | here | here | ||
| RepVGG-A2 | here | here | ||
| RepVGG-B1g4 | here | here | ||
| RepVGG-B1g2 | here | here | ||
| RepVGG-B1 | here | here | ||
| RepVGG-B2g4 | here | here | ||
| RepVGG-B2g2 | here | here | ||
| RepVGG-B2 | here | here | ||
| RepVGG-B3g4 | here | here | ||
| RepVGG-B3g2 | here | here | ||
| RepVGG-B3 | here | here | ||
| RepVGG-D2 | here | here |
Convert pertrained weight
python convert_pretrained_weight.py --origin-dir /path/to/weight --save-dir /path/to/save --model-arch RepVGGA0python test.py --helppython test.py --data /path/to/data --arch RepVGGA0 --model /path/to/weights_file --val-batch-size 100 --deploy 0 --switch-deploy 1 --print-freq 20