This repository bundles different NER benchmark experiments to compare the performance of monolingual and multilingual embeddings for both monolingual (Dutch, French and English) and multilingual datasets. The experiments were performed in the context of my master's dissertation. A bookdown website of the thesis can be found here (not everything is optimized for html so downloading the book in PDF is preferred).
All experiments made use of the awesome Flair library. The experiments were run using in individual scripts on Kaggle. A simple CLI was used to generate self-contained script and metadata files and push these to Kaggle using the Kaggle API, some examples can be found below.
| Language | Dataset | Downsampled | Tokens (train) | Tokens (dev) | Tokens (test) |
|---|---|---|---|---|---|
| English | CoNLL2003 | No | 203621 | 51362 | 46435 |
| Dutch | CoNLL2002 | No | 199969 | 37687 | 68466 |
| French | WikiNER | Yes (0.10) | 279729 | 34824 | 30991 |
| Multilingual | All | Yes (0.33) | 232173 | 40141 | 49444 |
Note: all datasets were converted to standard CoNLL2002 (BIO2)-format. Sentences containing more than 250 tokens (i.e. a total of 5 sentences in the CoNLL2002 dataset) were removed to allow the use of BERT embeddings (limited input sequence length). Document delimiters - when present - were removed as well. All three datasets were combined to obtain a multilingual dataset. Since the CoNLL2003 dataset requires a license (free for research) only the preprocessed CoNLL2002 and WikiNER datasets are included in this repository.
Different monolingual and multilingual embeddings were tested. This included monolingual, contextualized Flair and BERT embeddings, monolingual static fastText (fastT) and BytePair embeddings (BPEmbs) and task-specific word type embeddings (OneHotEmbeddings) (OHE) and character-feature embeddings (CharacterEmbeddings) (Char). For multilingual embeddings, we included multilingual BERT (mBERT), multilingual Flair (mFlair) and multilingual BytePair embeddings (mBPEmb).
For Flair embeddings, both forward and backward representations were included. BERT-based embeddings (both monolingual and multilingual) were obtained using the following parameter configuration of the TransformerWordEmbeddings class (i.e. default with only the last layer selected).
| parameter | value |
|---|---|
| layers | -1 |
| pooling_operation | first |
| use_scalar_mix | False |
A full overview of all configurations that were evaluated is provided below ("+" indicates concatenation into a single StackedEmbedding):
| No contextualized embeddings | BERT | Flair | BERT + Flair |
|---|---|---|---|
| BERT | Flair | BERT + Flair | |
| Char | BERT + Char | Flair + Char | BERT + Flair + Char |
| OHE | BERT + OHE | Flair + OHE | BERT + Flair + OHE |
| BPEmb (En) | BERT + BPEmb (En) | Flair + BPEmb (En) | BERT + Flair + BPEmb (En) |
| fastT (En) | BERT + fastT (En) | Flair + fastT (En) | BERT + Flair + fastT (En) |
| All | BERT + All | Flair + All | BERT + Flair + All |
All refers to Char + OHE + fastT (En) and BPEmb (En)
| No contextualized embeddings | BERT | Flair | BERT + Flair |
|---|---|---|---|
| BERTje | Flair (Nl) | BERTje + Flair (Nl) | |
| Char | BERTje + Char | Flair (Nl) + Char | BERTje + Flair (Nl) + Char |
| OHE | BERTje + OHE | Flair (Nl) + OHE | BERTje + Flair (Nl) + OHE |
| BPEmb (Nl) | BERTje + BPEmb (Nl) | Flair (Nl) + BPEmb (Nl) | BERTje + Flair (Nl) + BPEmb (Nl) |
| fastT (Nl) | BERTje + fastT (Nl) | Flair (Nl) + fastT (Nl) | BERTje + Flair (Nl) + fastT (Nl) |
| All | BERTje + All | Flair (Nl) + All | BERTje + Flair (Nl) + All |
All refers to Char + OHE + fastT (Nl) and BPEmb (Nl)
| No contextualized embeddings | BERT | Flair | BERT + Flair |
|---|---|---|---|
| CamemBERT | Flair (Fr) | CamemBERT + Flair (Fr) | |
| Char | CamemBERT + Char | Flair (Fr) + Char | CamemBERT + Flair (Fr) + Char |
| OHE | CamemBERT + OHE | Flair (Fr) + OHE | CamemBERT + Flair (Fr) + OHE |
| BPEmb (Fr) | CamemBERT + BPEmb (Fr) | Flair (Fr) + BPEmb (Fr) | CamemBERT + Flair (Fr) + BPEmb (Fr) |
| fastT (Fr) | CamemBERT + fastT (Fr) | Flair (Fr) + fastT (Fr) | CamemBERT + Flair (Fr) + fastT (Fr) |
| All | CamemBERT + All | Flair (Fr) + All | CamemBERT + Flair (Fr) + All |
All refers to Char + OHE + fastT (Fr) and BPEmb (Fr)
| No contextualized embeddings | BERT | Flair | BERT + Flair |
|---|---|---|---|
| mBERT | mFlair | mBERT + mFlair | |
| Char | mBERT + Char | mFlair + Char | mBERT + mFlair + Char |
| OHE | mBERT + OHE | mFlair + OHE | mBERT + mFlair + OHE |
| mBPEmb | mBERT + mBPEmb | mFlair + mBPEmb | mBERT + mFlair + mBPEmb |
| All | mBERT + All | mFlair + All | mBERT + mFlair + All |
All refers to Char + OHE + mBPEmb
Since the Kaggle API does not allow to import utility scripts directly from the command line, every experiment was executed from a self-contained script containing all the code to load the dataset, initialize the embeddings, train and evaluate the model. This script was automatically generated and pushed to Kaggle using a simple command line interface. Results were obtained by extracting the tp, fp and fn counts provided by Flair's training log and computing micro-average precision, recall and F1-score using sklearn. The Dropbox API was used to collect these results (token required).
The following command creates the python script, the kernel-metadata.json file (kernel name is the concatenation of dataset, language and the different embeddings) and pushes the script to Kaggle. By default, the embedding storage mode of the ModelTrainer instance is set to 'cpu'. When --storage option is set to gpu, the GPU is automatically enabled on Kaggle.
Important: the --data option requires a valid name of the dataset on Kaggle (path: /kaggle/input/<data>).
$ python3 push_and_run.py --help
Usage: push_to_kaggle.py [OPTIONS] [EMBEDDING_CODES]...
Embedding codes can be passed as arguments, the appropriate classes are
initiated according to the --lang option. Multiple embeddings are
concatenated (StackedEmbeddings)
Abbreviations:
=====================================================================
"bert": BERTje (nl), CamemBERT (fr), BERT (en), mBERT (multi)
"bpe": BytePairEmbeddings (fr, nl, en, multi)
"ohe": OneHotEmbeddings
"char": CharacterEmbeddings
"ft": fastText WordEmbeddings (fr, nl, en)
"flair": flair fw + bw (fr, nl, en, multi)
"elmo: ELMo embeddings (all 3 layers of ELMo large) (en)
=====================================================================
Options:
--user TEXT
--data TEXT Dataset: [conll2002, conll2003, wikiner, trired]
--lang TEXT Language of embedding class: [en, nl, fr, multi]
--epochs INTEGER Max number of epochs [default: 100]
--storage TEXT Embedding storage mode. When storage_mode is 'gpu', GPU
will be automatically enabled in the Kaggle environment.
[default: cpu]
--help Show this message and exit.Example 1: To run an experiment using CamemBERT + French fastText + OneHotEmbeddings on the WikiNER DS:
$ python3 push_and_run.py --data wikiner --lang fr bert ft oheExample 2: To run an experiment using mBERT + mFlair + multilingual BytePair embeddings on the trilingual DS:
$ python3 push_and_run.py --data trilingual --lang multi bert flair bpeAn overview of the results can be found in the thesis, .csv files can be downloaded here and the most recent results (currently, n=3 training runs for each experiment) are also visualized below. The precision, recall and F1-scores for each experiment were obtained by micro-averaging the per-class scores. The symbol and error bars indicate the mean and standard deviation (only included when they exceeded the symbol dimensions) for n=3.
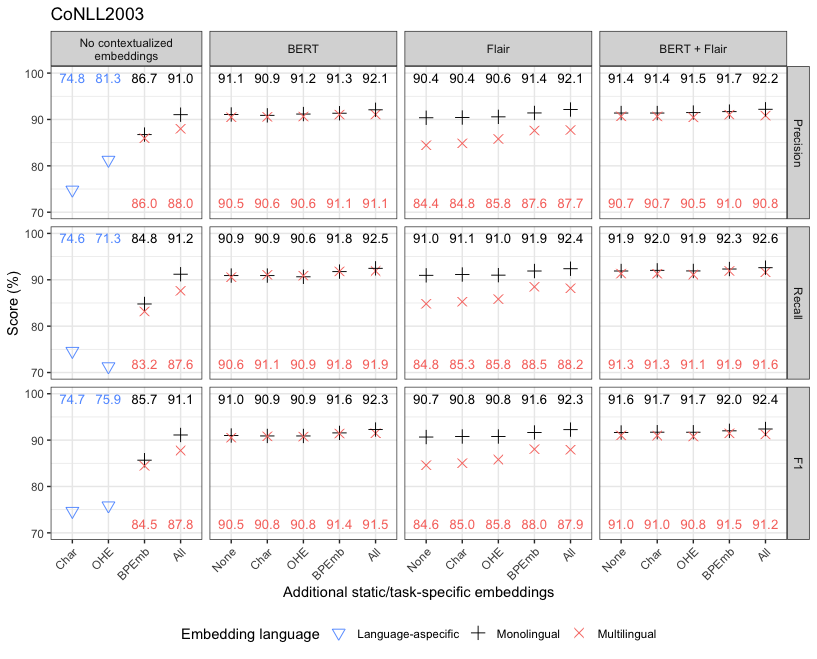
NOTE: "All" refers to Char + OHE + fastT and BPEmb (for monolingual embeddings) and Char + OHE + mBPEmb (for multilingual embeddings)
 NOTE: "All" refers to Char + OHE + fastT and BPEmb (for monolingual embeddings) and Char + OHE + mBPEmb (for multilingual embeddings)
NOTE: "All" refers to Char + OHE + fastT and BPEmb (for monolingual embeddings) and Char + OHE + mBPEmb (for multilingual embeddings)
 NOTE: "All" refers to Char + OHE + fastT and BPEmb (for monolingual embeddings) and Char + OHE + mBPEmb (for multilingual embeddings)
NOTE: "All" refers to Char + OHE + fastT and BPEmb (for monolingual embeddings) and Char + OHE + mBPEmb (for multilingual embeddings)