Hereafter We present the information for Cloning driving behavior using Deep Learning. The code will be presented separately in the repository in the file model.py and different packages will be used to process training data gathered from Udacity's simulator. Images gathered will be extended to provide better traininig. Images were saved to an S3 bucket to provide access from multiple computers to craft the model separately from the training instance.
The goals / steps of this project are the following:
- Use the simulator to collect data of good driving behavior
- Build, a convolution neural network in Keras that predicts steering angles from images
- Train and validate the model with a training and validation set
- Test that the model successfully drives around track one without leaving the road
- Summarize the results with a written report
The submission includes a model.py file, drive.py, model.h5 and a writeup report.
The following project includes:
- model.py Contains the script to create and train the model
- drive.py For driving the car in autonomous mode
- model.h5 Contains a trained convolution neural network
- writeup_report.md Summary of the results
- data_processing/ Module where all data processing code was placed
- data_preprocessing.py Utilities to merge all csv files into one
- data_processing.py Utilities to navigate csv using one index structure so that we can perform the following in a simple manner:
- Shuffle the data
- Apply multiple transforms
- Extend the data
Additional Files
- nvidia_model/
- model.h5 Model based on the nvidia network
- model.json JSON version of the model for info purposes
- inception_model/
- model.h5 Model based on the network with inception modules
- model.json JSON version of the model for info purposes
- smaller_model/
- model.h5 Model based on a smaller piece of the nvidia network
- model.json JSON version of the model for info purposes
Extra videos where created from each NN
The model provided can be used to successfully operate the simulation.
Using the Udacity provided simulator and drive.py file, the car can be driven autonomously around the track by executing
python drive.py model.h5To extend the data I created a standardized process.
- Gather new data using Udacity's Simulator and save it to a specific folder, e.g. new_data. Inside that folder you'll also have a IMG directory and a driving_log.csv file.
- Place the directory inside the specific track folder inside the data directory.
- If you have a data/driving_log_compiled.csv file already, erase it and re run model.py to regenerate, the process should gather your new images. All the transformations already in place will be applied to the new images.
The code in
model.pyuses a Python Generator
The code is separated in three files:
Contains all the code related to the CNN and the generators involved to train the model, as well as the pipeline for training, validating, and evaluating the model.
I created 3 Networks:
- Nvidia Model
- Smaller version of Nvidia Model
- Model with Inception Submodules
Several transformations for our images are done to extend the dataset, more information on this is found below. All the code pertaining into how these transformations are done is contained in this file.
Images are separated across multiple folders to allow scalability when adding new data from the simulator. These folders and files are traversed and merged into one.
The neural network uses convolution layers with appropriate filter sizes. Layers exist to introduce nonlinearity into the model. The data is normalized in the model.
All 3 Networks were able to clone the behavior.
A Batch Normalization Layer was added to each convolution based on the following: Sergey Ioffe and (2015). Batch Normalization: Accelerating Deep Network Training by Reducing. CoRR, abs/1502.03167.
Authors found that adding Batch Normalization to every convolution would improve learning.
Dropout Layer was added to all Networks
The Nvidia Network fared better than my other two networks. I trained it with just the provided data and gradually increased data until I reached a more healthy level of images of 21875 * cameras.
As I increased the data I also had to decreased the Epochs as it would overfit faster. Alternatively we could reduce the number of Samples per Epoch to have a more granular control over our loss.
Train/validation/test splits have been used, and the model uses dropout layers or other methods to reduce overfitting.
I divided the data and then proceed to shuffle the training data.
x_train, x_test = train_test_split(image_index_db, test_size=0.3)
x_train = shuffle(x_train)Batch size is a factor of the total samples to prevent processing the same samples. There is some data being thrown away randomly every run. This did not affect the results.
I also have Image normalization and Image Cropping as the first layers, as well as Dropout layers, Batch normalization in every convolution to improve learning.
I went with processing the whole dataset in every Epoch but I did not like this approach because it took away control. Training smaller subsets of the data gives the benefit of observing loss more carefully and using Keras I could save the model gradually.
Learning rate parameters are chosen with explanation, or an Adam optimizer is used.
I used an Adam Optimizer as it has given me good results in the past, the default learning rate of 0.001 works really well.
Training data has been chosen to induce the desired behavior in the simulation (i.e. keeping the car on the track).
A whole set of tools were created to extend the data fast and easily, this allowed me to find unwanted behavior and just gather more data for that. After that my system would gather the new data, extend it, and even use the left and right cameras. This produced great and fast results.
I have seen improvements in the past using multiple brightness levels but I believe in this case they will only introduce unnecessary computations since illumination won't change in the simulator. Here is an example of all the transforms we could apply if activated.

Of all those transformations we just keep the following:
For center cameras we just load the camera, I apply a correction to the steering of +0.25 for left and -0.25 for right camera.
All images, whether left, center, or right, will also be flipped and the steering will be multiplied by -0.1, after that the cameras will also be flipped (left for right and viceversa) and the steering adjust from before will still apply.
The README thoroughly discusses the approach taken for deriving and designing a model architecture fit for solving the given problem.
The overall strategy was to use models that were used before, starting with LeNet and ramping up to Nvidia's model for Deep Learning. I also created a model with Inceptions that worked but was too heavy for my computer. For the same reason I started gathering pieces to build my own Deep Learning computer with at least 32GB in GPU Memory.
For all models tried we used:
- Dropout Layers
- Extra normalization to constraint values as they traverse the network
- Training and test splits
- Shuffling of training data
We tracked the validation loss really closely to observe the moment we start seeing some rise, it takes more than entire Epoch to overfit but it is still a possibility. When overfitted the car would run in circles.
The README provides sufficient details of the characteristics and qualities of the architecture, such as the type of model used, the number of layers, the size of each layer. Visualizations emphasizing particular qualities of the architecture are encouraged.
Main model is based on the following:
Bojarski, M., Del Testa, D., Dworakowski, D., Firner, B., Flepp, B., Goyal, P., ... & Zhang, X. (2016). End to end learning for self-driving cars. arXiv preprint arXiv:1604.07316.

The solution was built to drop new data easily:

With the exception of using a Batch Normalization on every convolution.
The Nvidia Model is presented in model.py lines 45-60.
In 2014 Google presented GoogLeNet, a neural network made of 22 layers that looks something like this:

I have never trained such a massive network but I want to build a smaller version with less Inception modules. An inception looks like the following:

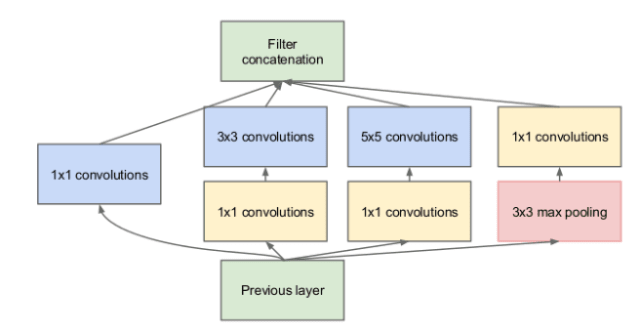
Which you may see it on the Deep Learning Course on Udacity as follows:
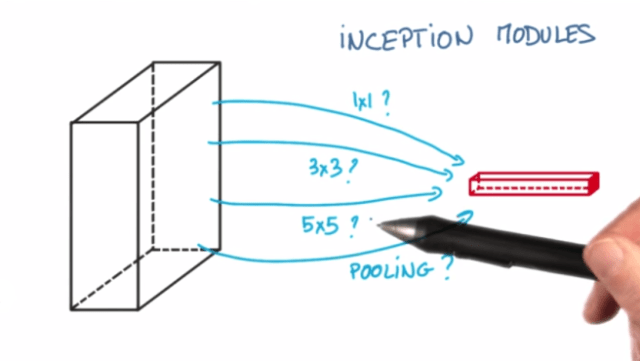
Inception worked really well for me in the past, so I want to take it out for a test drive on this project, at least to some exted, and the first step is to scrap the Sequential() model. One of the recommendations that caught my eye on Deep Learning by Bengio, Yoshua, Goodfellow, Ian J & Courville, Aaron (2015) is that gathering more data (or better data) is a more prefered route rather than changing the model.
The Inception Model is presented in model.py lines 63-110.
The README describes how the model was trained and what the characteristics of the dataset are. Information such as how the dataset was generated and examples of images from the dataset should be included.
To assemble the data we use multiple use cases, we need to be able to extend the data easily so we create some scripts that rebuilds the labels.

> *Mapping all those images in those 3 rows is as simple as doing `len(rows*cameras)` which should give us `9`.*
This is pretty convenient as of 3 rows we can generate use all the images, shuffle them, break them into test set, train set, whatever set.
We're still not done with our 9 images. We can make them less bright, more bright, adjust the gamma factor, flip them, pop them, twist them.
And this is where the index gets useful.
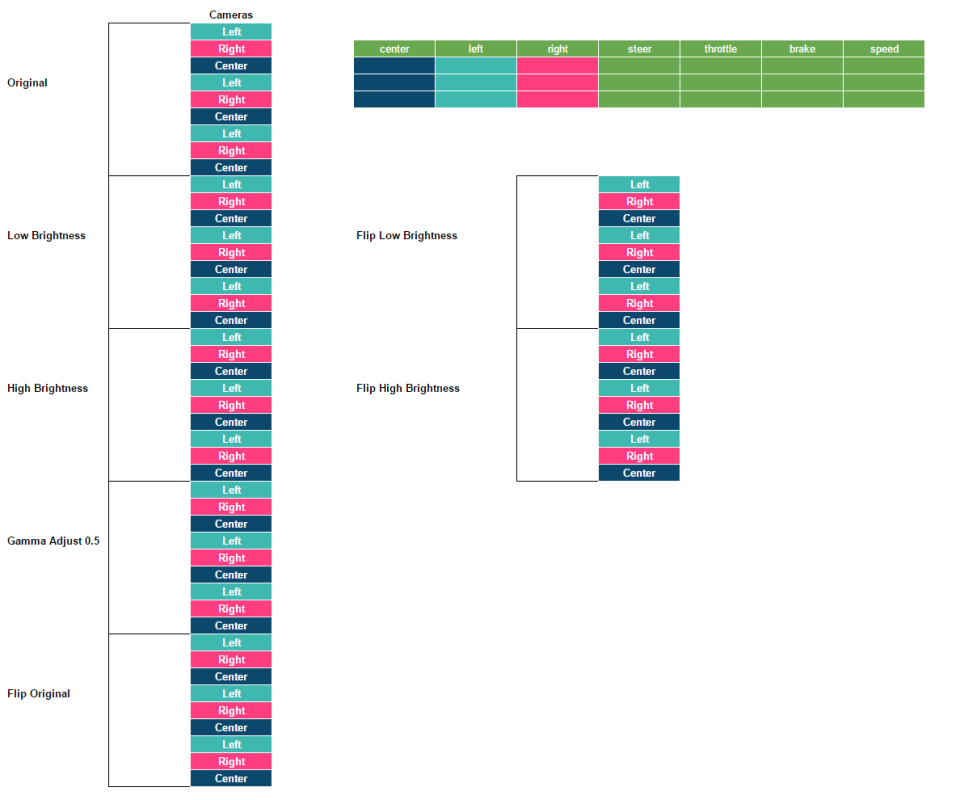
> *We just turned `9` images into `9 x Number of transformations`, in this case `63` different images.*
The transforms are documented in data_processing/data_processing.py lines 140-177.
To gather new data I train the network on a initial set of data. After observing parts that the network was not able to navigate I create new data based on the errors observed. This process continues and eventually we are able to navigate.
No tire may leave the drivable portion of the track surface. The car may not pop up onto ledges or roll over any surfaces that would otherwise be considered unsafe (if humans were in the vehicle).
The car is able to navigate on all models. An issue we observe is that my computer seems to struggle with the model. My computer wasn't able to train the Inception Model and running it eventually stops.
