RFC: Fix ambiguity with null variable values and default values #418
Conversation
> This is a **behavioral change** which changes how explicit `null` values interact with variable and argument default values. This also changes a validation rule which makes the rule more strict. There is currently ambiguity and inconsistency in how `null` values are coerced and resolved as part of variable values, default values, and argument values. This inconsistency and ambiguity can allow for `null` values to appear at non-null arguments, which might result in unforseen null-pointer-errors. This appears in three distinct but related issues: **Validation: All Variable Usages are Allowed** The explicit value `null` may be used as a default value for a variable with a nullable type, however this rule asks to treat a variable's type as non-null if it has a default value. Instead this rule should specifically only treat the variable's type as non-null if the default value is not `null`. Additionally, the `AreTypesCompatible` algorithm is underspecificied, which could lead to further misinterpretation of this validation rule. **Coercing Variable Values** `CoerceVariableValues()` allows the explicit `null` value to be used instead of a default value. This can result in a null value flowing to a non-null argument due to the validation rule mentioned above. Instead a default value must be used even when an explicit `null` value is provided. This is also more consistent with the explanation for validation rule "Variable Default Value Is Allowed" Also, how to treat an explicit `null` value is currently underspecified. While an input object explains that a `null` value should result in an explicit `null` value at the input object field, there is no similar explaination for typical scalar input types. Instead, `CoerceVariableValues()` should explicitly handle the `null` value to make it clear a `null` is the resulting value in the `coercedValues` Map. **Coercing Argument Values** The `CoerceArgumentValues()` algorithm is intentionally similar to `CoerceVariableValues()` and suffers from the same inconsistency. Explicit `null` values should not take precedence over default values, and should also be explicitly handled rather than left to underspecified input scalar coercion.
|
Since this changes behavior, I'd love your feedback @IvanGoncharov, @OlegIlyenko, et al |
|
cc @bbakerman |
|
@leebyron I fully agree with the changes from
This is very confusing at the first glance, especially for argument values. Here is the example from JS: function f(arg = 'foo') {
return arg;
}
f() // 'foo'
f(null) // null
f('bar') // 'bar'And same in Python and probably all other langs so I would expect the same from GraphQL. |
|
Absolutely correct, @IvanGoncharov. There are two paths forward to solve for the ambiguity, each of which have some tradeoffs. The path I'm proposing here preserves the ability to treat The alternative is to no longer treat My concern is that the change cost of this alternative is too high since passing a variable with a default value to a non-null argument is an existing pattern. However I'm less certain how common overriding a default value with an explicit |
|
It's an interesting change. I remember the time when I finally correctly implemented the support for the Along the way, I also faced these issues where null value can potentially appear in nullable the argument with a default value (which might be treated as not-null since it has a default). As a solution to this problem I introduced following 2 things:
I find this solution quite robust - by default, it behaves similarly to the proposal in this PR, but it also provides a way to propagate explicit Though it is still possible to trick the system by setting the default value to type Query {
article(id: ID = null): Atricle
}Do you think it would make sense to disallow this? (for arguments, input fields, and variables) I personally don't have practical insights on API that takes advantage of the |
|
@leebyron It's not an ideal solution since we are trying to fix validation issue by changing execution behavior. Ideally, we would allow defaults to be specified on nonull arguments: query foo($arg: String! = "foo")
{} => $arg === "foo"
{ arg: null } => Exception
query bar($arg: String = "bar")
{} => $arg === "bar"
{ arg: null } => $arg === nullBut it's not a viable alternative since it will break huge number of existing queries 😢 So practically speaking if there is no GraphQL APIs that distinguish between That said I think it's very important question so we need to be extremely careful and do some research beyond the Facebook use case. GitHub was my first victim and tried to pass nulls in every field with a default argument. A few of them treat |
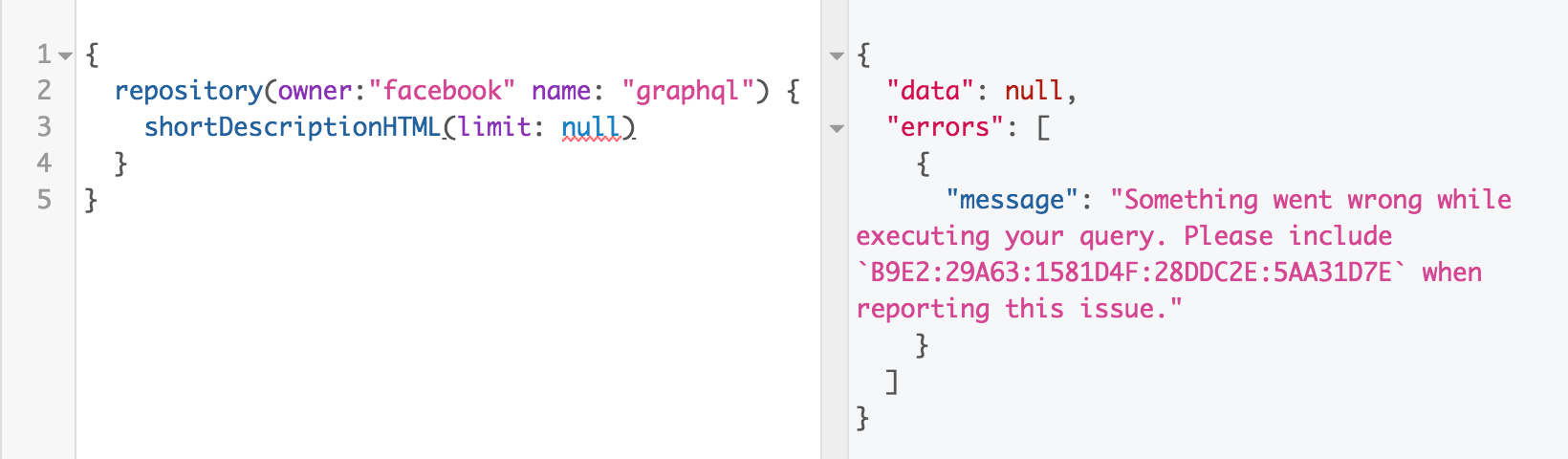
|
IIUC this is ~ the same issue as #359. I also find the "explicit nulls don't take precedence over defaults" confusing. Per the issue I originally filed, I think this can be solved by by allowing non-null variables/arguments/input-fields to have default values. This is I think what you mean by
The change cost of that approach is real, but the migration is fairly trivial and I think important: anywhere that this ambiguity currently occurs the author is forced to resolve it by adding a |
This updates this proposal to be a bit broader in scope however much narrower in breaking behavior changes. Mirroring the changes in graphql/graphql-js#1274, this update better defines the difference between a "required" and "non-null" argument / input field as a non-null typed argument / input-field with a default value is no longer required. As such the validation rule which prohibited queries from using non-null variables and default values has been removed. This also adds clarity to the input field validation - this rule has existed in the GraphQL.js reference implementation however was found missing within the spec. This also updates the CoerceVariableValues() and CoerceArgumentValues() algorithms to retain explicit null values overriding a default value (minimizing breaking changes), however critically adding additional protection to CoerceArgumentValues() to explicitly block null values from variables - thus allowing the older pattern of passing a nullable variable into a non-null argument while limiting the problematic case of an explicit null value at runtime.
d3599a4
to
3dc6d1b
Compare
|
Excellent feedback everyone. I've made serious revisions which I hope both protect against allowing null values to non-null arguments while preserving existing behavior. The result is a bit broader in scope, however no longer breaks existing queries in either validation or execution. The reference PR has also been updated in graphql/graphql-js#1274 This update better defines the difference between a "required" and "non-null" argument / input-field as a "non-null" type which includes a default value is no longer required. As such the validation rule which prohibited queries from using non-null variables and default values has been removed completely. This change also adds clarity to the input field validation - this rule has existed in the GraphQL.js reference implementation however was found missing within the spec. It essentially mirrors the change of the required argument rule. This also updates the I'd love another look at this and the accompanying PR. I feel confident in this approach but would appreciate your feedback. |
| @@ -1358,6 +1359,31 @@ For example the following query will not pass validation. | |||
| ``` | |||
|
|
|||
|
|
|||
| ### Input Object Required Fields | |||
There was a problem hiding this comment.
This rule exists as part of GraphQL.js's ValuesOfCorrectType but was missing from the spec
| @@ -1494,44 +1520,6 @@ fragment HouseTrainedFragment { | |||
| ``` | |||
|
|
|||
|
|
|||
| ### Variable Default Value Is Allowed | |||
There was a problem hiding this comment.
This rule is completely removed since the queries it prohibited we explicitly wish to support.
spec/Section 5 -- Validation.md
Outdated
| * If {variableType} is not a non-null and {defaultValue} is provided and not {null}: | ||
| * Let {variableType} be the non-null of {variableType}. | ||
| * Let {argumentType} be the type of the argument {variableUsage} is passed to. | ||
| * AreTypesCompatible({argumentType}, {variableType}) must be {true}. |
There was a problem hiding this comment.
Most of this change is for clarity, however the default value is now checked for {null} first
spec/Section 5 -- Validation.md
Outdated
| * Return {AreTypesCompatible(itemArgumentType, itemVariableType)}. | ||
| * Otherwise return {false}. | ||
| * If {variableType} is a list type return {false}. | ||
| * Return if {variableType} and {argumentType} are identical. |
There was a problem hiding this comment.
Other than the checking default values being removed from this algorithm, this is all for clarity and doesn't signify any other behavioral change
|
I'm a bit torn - on the one hand I think this approach is probably the best we can do in terms of a clarification that is strictly non-breaking. On the other hand I'm not sure that strictly non-breaking is something we should be striving for in this case:
I realize that putting a breaking change like that in the spec causes its own huge set of pains for implementations that have to migrate, but I guess I'm not convinced that isn't still the best long-term solution. All that said, I do believe this current approach is the best we can do while being non-breaking, so if that's the way that we want to go then I won't object further. |
|
@eapache - great points. I actually think what I now have here is very close to what I would propose in a "from scratch" design. The execution behavior is almost exactly as I would expect it in a from-scratch design as it respects explicit values over default values in the same way as other programming languages. The only difference I might have expected in a from-scratch design is to be even more trusting of variable values in The validation behavior is really where we've made specific considerations to avoid breaking existing queries, however this proposal is still very close to what I would propose in a "from scratch" design. This proposal makes 3 important changes to query validation:
I will look at editing this to both make it more clear where the caveat for existing systems is while making it possible (or even encouraged) for new systems not to adopt that caveat. @eapache are there other differences from the current state of this PR that you would consider approaching differently in a from-scratch design? |
Yup, this is the one that is bugging me :)
Awesome. I was going to suggest that we include an RFC 2119 header in the spec so we can use SHOULD/MAY appropriately here, but I note that you already did that, it just hasn't made it into http://facebook.github.io/graphql/ yet. I think that servers
I'll go through again but I think that was the only one. |
spec/Section 5 -- Validation.md
Outdated
| Otherwise, the argument is optional. | ||
| Arguments can be required. If the argument type is non-null and does not have a | ||
| default value, the argument is required and furthermore the explicit value | ||
| {null} may not be provided. Otherwise, the argument is optional. |
There was a problem hiding this comment.
I read this to imply (probably unintentionally) that a non-null argument with a default value is allowed to be passed an explicit null?
…makes it more explicitly clear that changing the effective type of a variable definition is only relevent when supporting legacy clients and suggests that new services should not use this behavior. I like that this balances a clear description of how this rule should work for existing services along with a stricter and therefore safer future path for new services.
|
@eapache - I just updated this with your feedback incorporated. I'm glad we agree on the ideal outcome of this proposal. My last update is one step further towards the idealized "from scratch" proposal, this makes it more explicitly clear that changing the effective type of a variable definition is only relevant when supporting legacy clients and suggests that new services should not use this behavior. I like that this balances a clear description of how this rule should work for existing services along with a stricter and therefore safer future path for new services. I also just updated graphql/graphql-js#1274 to include this and make this a breaking change by default while providing an API for using this legacy behavior. I'd love a last look by anyone else interested |
…e" statements for easier reading. Functionality is equivalent.
|
Updating this a bit. I'm still trying to convince myself that the breaking change is worth doing. I realized that it also has a side effect of not allowing an optional variable to be provided to a optional non-null argument. query Example($var: Int!) {
field(arg: $var)
}
type Query {
field(arg: Int! = 0): Int
}While the above query is valid, it is invalid to not provide a runtime value for An alternative, (which I'm also not sure about) is allowing nullable (optional) variables to flow into non-null optional positions, while still throwing at runtime for explicitly provided null values (already included in this proposal). For example, this is currently invalid but would become valid in the alternative proposal: query Example($var: Int) { # nullable
field(arg: $var) # non-null but optional
}
type Query {
field(arg: Int! = 0): Int
}In that case, omitting Thoughts on this? |
|
After discussing this in depth with @dschafer at a whiteboard - we've talked ourselves out of any breaking change - I think that having a fork in the expected behavior of validation rules is just too easy to get wrong, liable to cause issues during deployment, and could create a bifurcation of tooling environments. We came up with mitigation strategies for Facebook's codebases and APIs, however also agreed that public APIs like Github would be much much more challenging to solve for. Even though the behavior is not an ideal "from scratch" - I think that it's worth avoiding the breaking change. I still think the spec should call out this potential issue directly in a non-normative note for clarity. |
Also attempts to improve clarity and formatting and adds an example case.
|
I've just updated the description to mirror the current change. I believe this is ready to merge and will first wait for a bit for others to review and comment. |
There was a problem hiding this comment.
These changes look good, with just one edit.
More generally, I've wrestled with the idea of making a change that breaks previously-valid queries, and as much as I'd prefer the "from-scratch" behavior described above, I think this is the right call.
However, I don't think we should be terribly concerned with a bifurcation of tooling. Because we're already altering the spec for query validation to expand the definition of validity, we're going to see a mismatch in the wild: some servers won't update their software, while new clients will expect looser queries to work. This is probably unavoidable, and makes me think that there should be a "graphql version" or programmatically readable "feature set" (as discussed in the WG meeting) supplied in the result of an introspection query.
If such a thing were implemented, tooling (clients, code generators, compilers, etc) could allow the developer to opt into different validation behaviors based on the target server. This is a ton of added complexity, of course, but the problem it would solve exists with the proposed changes, even without SHOULD clauses describing the preferred, stricter rules.
| * Otherwise, if {argumentValue} is a {Variable}: | ||
| * Add an entry to {coercedValues} named {argumentName} with the | ||
| value {value}. | ||
| * Otherwise: |
There was a problem hiding this comment.
You probably don't want this "otherwise" here, since coercion and resulting failures need to happen if {argumentValue} is a {Variable}.
There was a problem hiding this comment.
It is intentional. Variables are coerced during CoerceVariableValues before execution of a query at which point and resulting failures are also reported before execution, so a second coercion is not necessary.
There's an existing note below this algorithm capturing this point
There was a problem hiding this comment.
Ah I see – I missed that note below. 👍
I agree with @mike-marcacci I think most of the tooling doesn't need to be backward compatible. There is only one scenario we shouldn't break: existing queries compiled inside clients that were deployed in production should be still supported by GraphQL server. That means that all client libraries, ESlint plugin, client code generation, GraphiQL and other libraries/tools that are used only in development or during build process can be easily updated. The only part of the ecosystem that should be backward compatible are GraphQL servers and maybe some proxy servers (e.g. Apollo Engine). That's why I think both specification and
This is not a problem since if a new client stops working with old servers it would be caught during development. So I think we should distinguish between changes that will break already deployed clients and changes that will result in temporary inconvenience during development.
I think any mechanism involving introspection query is not a solution since the majority of GraphQL clients doesn't do any handshake; they just send queries to the server. So the only solution I see is for sever to detect what was the expected behavior during client development and fallback to it.
@leebyron I want to propose a solution. Currently, all GraphQL clients send GraphQL request document inside So it makes sense to rename this field to So a server can implement the following algorithm:
Pros:
Cons:
I also think we should use an integer for |
…ibutes with default values. See graphql/graphql-spec#418
This removes a rule which was removed as part of the spec in graphql/graphql-spec#418
Note: there is a difference between explicitly passed "null" value and just omitted variable. See graphql/graphql-spec#418 Closes #866
See: https://graphql.org/learn/queries/#default-variables Note: there is a difference between explicitly passed "null" value and just omitted variable. See graphql/graphql-spec#418 Closes #866
Imported from tarantool/cartridge@6eb4a43 ``` See: https://graphql.org/learn/queries/#default-variables Note: there is a difference between explicitly passed "null" value and just omitted variable. See graphql/graphql-spec#418 Closes tarantool/cartridge#866 ```
Imported from tarantool/cartridge@6eb4a43 ``` See: https://graphql.org/learn/queries/#default-variables Note: there is a difference between explicitly passed "null" value and just omitted variable. See graphql/graphql-spec#418 Closes tarantool/cartridge#866 ```
Imported from tarantool/cartridge@6eb4a43 ``` See: https://graphql.org/learn/queries/#default-variables Note: there is a difference between explicitly passed "null" value and just omitted variable. See graphql/graphql-spec#418 Closes tarantool/cartridge#866 ```
(Rendering Preview: https://out-nmocjoypvp.now.sh)
This is a NON-BREAKING validation change which allows some previously invalid queries. It is also a behavioral execution change which changes how values interact with variable and argument default values.
There is currently ambiguity and inconsistency in how
nullvalues are coerced and resolved as part of variable values, default values, and argument values. This inconsistency and ambiguity can allow fornullvalues to appear at non-null arguments, which might result in unforseen null-pointer-errors.The version of this proposal to be merged includes the following:
nulldefault value cannot be provided to a non-null argument or input field.CoerceVariableValues()to make it more clear how to treat a lack of runtime value vs the explicit valuenullwith respect to default values and type coercion.CoerceArgumentValues()to ensure providing anullvariable value to a Non-Null argument type causes a field error, and to add clarity to hownullvalues and default values should be treated.nullvalue or runtime variable value to a non-null type causes a field error, and improve clarity for these coercion rules. This mirrors the changes toCoerceArgumentValues().Previous version of this proposal:
This appears in three distinct but related issues:
Validation: All Variable Usages are Allowed
The explicit value
nullmay be used as a default value for a variable with a nullable type, however this rule asks to treat a variable's type as non-null if it has a default value. Instead this rule should specifically only treat the variable's type as non-null if the default value is notnull.Additionally, the
AreTypesCompatiblealgorithm is underspecificied, which could lead to further misinterpretation of this validation rule.Coercing Variable Values
CoerceVariableValues()allows the explicitnullvalue to be used instead of a default value. This can result in a null value flowing to a non-null argument due to the validation rule mentioned above. Instead a default value must be used even when an explicitnullvalue is provided. This is also more consistent with the explanation for validation rule "Variable Default Value Is Allowed"Also, how to treat an explicit
nullvalue is currently underspecified. While an input object explains that anullvalue should result in an explicitnullvalue at the input object field, there is no similar explaination for typical scalar input types. Instead,CoerceVariableValues()should explicitly handle thenullvalue to make it clear anullis the resulting value in thecoercedValuesMap.Coercing Argument Values
The
CoerceArgumentValues()algorithm is intentionally similar toCoerceVariableValues()and suffers from the same inconsistency. Explicitnullvalues should not take precedence over default values, and should also be explicitly handled rather than left to underspecified input scalar coercion.