- 데이터를 나열하고, 각 데이터를 인덱스에 대응하도록 구성한 데이터 구조
- Python에서는 List 타입이 Array 기능을 제공
- 장점 : 자료구조의 기본으로, 논리적 순서와 물리적 순서가 일치
→ index 번호로 빠른 접근 가능(첫 데이터의 위치에서 상대적인 위치로 데이터 접근) - 단점 : 삭제, 삽입 등의 연산에 필요한 cost ↑(미리 데이터 공간을 할당해야 함)
→ 삭제의 경우는 순서를 맞추기 위해 뒤의 원소들을 모두 shift 연산을 해줘야 하며,
→ 삽입의 경우는 삽입한 index 포함, 그 뒤의 index들에 shift 연산을 해줘야 함

- 파이썬에서는 리스트로 배열 구현 가능
# 1차원 배열: 리스트로 구현시
arr1 = [1,2,3,4,5]
# 2차원 배열: 리스트로 구현시
arr2 = [[1,2,3],[4,5,6],[7,8,9]]- 연결 리스트라고도 하며, Array의 삽입/삭제 연산에 대한 비효율성을 극복하고자 등장
- Array와의 차이점 : Array는 논리적, 물리적 저장이 순서대로 되어있는 반면, LinkedList는 각 원소가 다음 index 위치에 해당하는 물리적 주소를 갖고 있다.
→ 장점 : 삽입/삭제 시 데이터를 shift할 필요없이 해당되는 원소의 물리적 주소만 변경해주면 됨
→ 단점 : 하지만 이러한 연결 특성 때문에 원하는 index를 참조하려면 1번 index부터 차례대로 접근해야한다는 비효율성 존재, 접근 속도↓, 저장공간 효율↓ - 본래 C언어에서는 주요한 데이터 구조이지만, Python은 List 타입이 LinkedList의 기능을 모두 지원
- LinkedList 기본 구조와 용어
- 노드(Node) : 데이터 저장 단위(데이터값, 포인터)로 구성
- 포인터(Pointer) : 각 노드 안에서, 다음이나 이전의 노드와의 연결 정보를 갖고 있는 공간

- 본래 C언어에서는 주요한 데이터 구조이지만, Python은 List 타입이 LinkedList의 기능을 모두 지원
- 보통 파이썬에서 LinkedList 구현시, 파이썬 클래스를 활용
# Node 구현
class Node:
def __init__(self, data, next=None):
self.data = data
self.next = next
# LinkedList로 데이터 추가
def add(data):
node = head
while node.next:
node = node.next
node.next = Node(data)
node1 = Node(1)
head = node1
for index in range(2, 10):
add(index)
# LinkedList 데이터 출력(검색)
node = head
while node.next:
print(node.data)
node = node.next
print (node.data) # 1 ~ 9 차례대로 출력됨- Queue는 선형 자료구조이며, FIFO(First In, First Out)구조이다.
- 멀티 태스킹을 위한 프로세스 스케쥴링 방식을 구현하기 위해 많이 사용되며, 작업 우선순위, Heap 구현 등에 사용된다.

- 파이썬 queue 라이브러리는 다양한 큐 구조로 Queue(), LifoQueue(), PriorityQueue() 제공
- Queue() : 가장 일반적인 큐 자료 구조(FIFO)
- LifoQueue() : 나중에 입력된 데이터가 먼저 출력되는 구조(=스택 구조)
- PriorityQueue() : 데이터마다 우선순위 넣어서, 우선순위 높은 순으로 데이터 출력
# Queue
import queue
fifoq = queue.Queue()
fifoq.put("fifo")
fifoq.put(1)
fifoq.qsize() # 2
fifoq.get() # 'fifo'
# LifoQueue()
lifoq = queue.LifoQueue()
lifoq.put("lifo")
lifoq.put(1)
lifoq.qsize() # 2
lifoq.get() # 1
# PriorityQueue()
priorq = queue.PriorityQueue()
priorq.put((10, "a"))
priorq.put((5, 1))
priorq.put((15, "c"))
priorq.qsize() # 3
priorq.get() # (5, 1)
priorq.get() # (10, 'a')
# 리스트 변수로 enqueue, dequeue 기능 구현
queue_list = []
def enqueue(data):
queue_list.append(data)
def dequeue():
data = queue_list[0]
del queue_list[0]
return data
for idx in range(10):
enqueue(idx)
print(len(queue_list)) # 10
print(dequeue()) # 0- Stack은 선형 자료구조로, 데이터를 한쪽 끝에서만 제한적으로 접근 가능한 구조이다.
- LIFO(Last In, First Out)구조이며, 미로찾기, 괄호 유효성 체크 등에 활용된다.
- 스택은 단순하고 빠른 성능을 위해 사용되므로, 보통 배열 구조를 활용해서 구현하는 것이 일반적.
- 장점 : 구조가 단순해서 구현이 쉽고, 데이터 저장/읽기 속도 빠름
- 단점(일반적 스택 구현시) : 데이터 최대 갯수 미리 정해야 함(파이썬의 경우 재귀함수는 1000번까지만 호출 가능), 저장 공간 낭비 발생할 수 있음(미리 최대 갯수만큼 저장 공간 확보해야 함)

- 파이썬 리스트 기능에서 제공하는 메서드는 append(push), pop 이 있다.
stack = []
# push
stack.append(1)
stack.append(2)
print(stack) # [1,2]
# pop
a = stack.pop()
print(a) # 2- key에 데이터(value)를 저장하는 구조
- key를 통해 바로 데이터를 받아올 수 있으므로, 속도가 획기적으로 빨라짐
- 보통 배열로 미리 HashTable 사이즈만큼 생성 후에 사용(공간과 탐색 시간 복잡도 맞바꾸는 기법)
- 파이썬에서는 해쉬를 별도 구현하지 않고 딕셔너리 타입을 사용하면 된다.
- 장점 : 데이터 저장/검색 속도↑, 키에 대한 데이터가 있는지 중복 확인 용이
- 단점 : 저장공간 요구↑, 여러 키에 해당하는 주소가 동일할 경우 충돌 해결 위한 별도 자료구조 필요
- 저장/삭제/검색이 빈번한 경우, 캐쉬 구현시(중복 확인이 용이) 주로 사용한다.
- 해쉬 테이블의 경우, Collision이 없는 일반적인 경우를 기대하고 만들기 때문에 시간 복잡도는 O(1)이라고 할 수 있음
- ex. 16개의 배열에 데이터를 저장하고 검색할 때 O(n) vs 16개의 데이터 저장공간을 가진 해쉬테이블에 데이터를 저장하고 검색할 때 O(1)
- Hash : 임의 값을 고정 길이로 변환하는 것
- Hash Table : 키 값의 연산에 의해 직접 접근이 가능한 데이터 구조(해쉬값 또는 해쉬주소와 슬롯을 갖고 있는 데이터 구조)
- Hashing Function : 키를 넣으면 데이터 위치(해쉬 주소)를 찾을 수 있는 함수
- Hash Value 또는 Hash Address : 키를 해싱함수로 연산해서 해쉬값을 알아내고, 이를 기반으로 해쉬 테이블에서 해당 키에 대한 데이터 위치를 일관성있게 찾을 수 있음
- Slot : 한 개의 데이터를 저장할 수 있는 공간
- 저장할 데이터에 대해 키를 추출할 수 있는 별도 함수도 존재 가능
- 파이썬에서는 딕셔너리가 있어서 굳이 만들 필요는 없으나, 간단하게 구현한다면 코드는 다음과 같다.
# Hash Table
class HashTable:
def __init__(self, table_size):
self.size = table_size
self.hash_table = [0 for a in range(self.size)]
def getKey(self, data):
self.key = ord(data[0])
return self.key
def hashFunction(self, key):
return key % self.size
def getAddress(self, key):
myKey = self.getKey(key)
hash_address = self.hashFunction(myKey)
return hash_address
def save(self, key, value):
hash_address = self.getAddress(key)
self.hash_table[hash_address] = value
def read(self, key):
hash_address = self.getAddress(key)
return self.hash_table[hash_address]
def delete(self, key):
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0:
self.hash_table[hash_address] = 0
return True
else:
return False
#Test Code
h_table = HashTable(8)
h_table.save('a', '1111')
h_table.save('b', '2222')
h_table.save('c', '3333')
h_table.save('d', '4444')
print(h_table.hash_table) # [0, '1111', '2222', '3333', '4444', 0, 0, 0]
print(h_table.read('d')) # 4444
h_table.delete('d')
print(h_table.hash_table) # [0, '1111', '2222', '3333', 0, 0, 0, 0]- 비선형 자료구조로, Node와 Branch를 이용해서, 사이클을 이루지 않도록 구성한 계층적 데이터 구조
- 이진 트리(Binary Tree) 형태의 구조로, 탐색 알고리즘 구현을 위해 많이 사용됨
- Node: 트리에서 데이터를 저장하는 기본 요소 (데이터와 다른 연결된 노드에 대한 Branch 정보 포함)
- Root Node: 트리 맨 위에 있는 노드
- Level: 최상위 노드를 Level 0으로 하였을 때, 하위 Branch로 연결된 노드의 깊이를 나타냄
- Parent Node: 어떤 노드의 다음 레벨에 연결된 노드
- Child Node: 어떤 노드의 상위 레벨에 연결된 노드
- Leaf Node (Terminal Node): Child Node가 하나도 없는 노드
- Sibling (Brother Node): 동일한 Parent Node를 가진 노드
- Depth: 트리에서 Node가 가질 수 있는 최대 Level
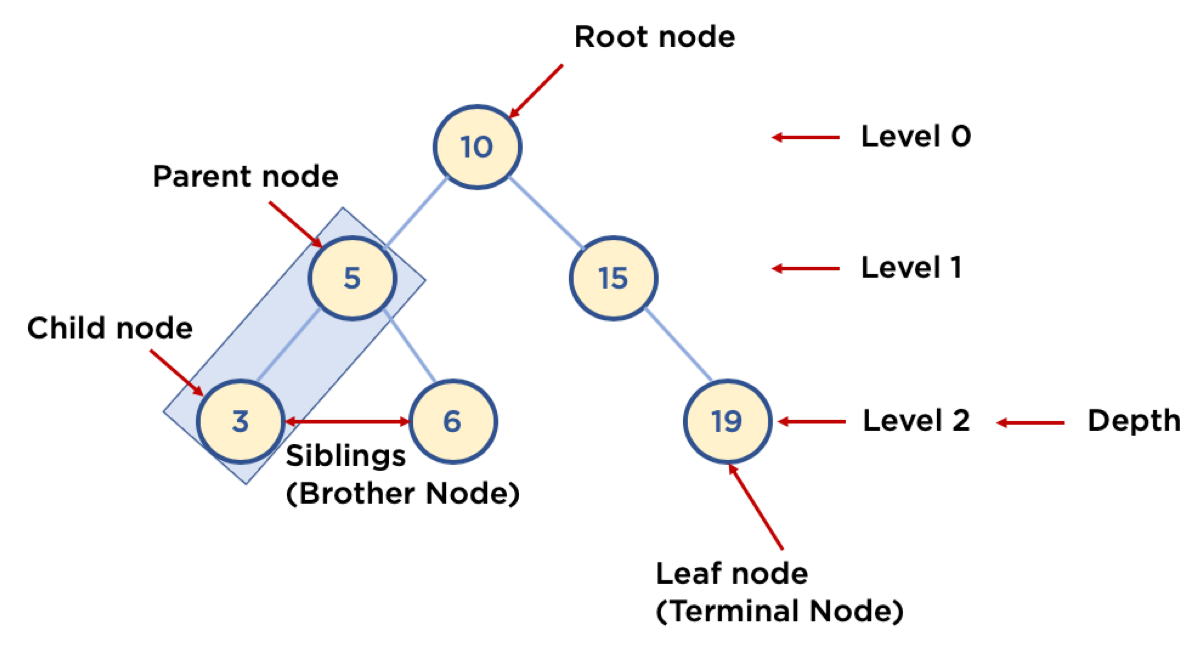
- 노드의 최대 Branch가 2인 트리
- 이진트리에는 모든 level이 가득 찬 이진트리인 Full Binary Tree(포화 이진 트리) 와 위에서 아래로, 왼쪽에서 오른쪽으로 순서대로 채워진 트리인 Complete Binary Tree(완전 이진 트리) 가 있다.
- 포화 이진트리 : 이진트리에서 최대 노드의 수를 만족하는 트리
- 완전 이진트리 : 높이가 h인 트리에서 노드 수가 n일 때 레벨 순서번호가 1~n까지 모두 일치하는 트리
- 배열로 포화 이진트리와 완전 이진트리를 구현했을 때, 노드의 개수 n에 대해서 i번째 노드에 대해서
parent[i] = i/2 , left_child = 2i, right_child = 2i + 1의 인덱스 값 을 갖는다.

- 효율적인 저장방법을 갖는 자료구조로, 저장 규칙에 따라 찾고자 하는 데이터를 효율적으로 탐색할 수 있다.
- 이진 트리에 왼쪽 노드는 해당 노드보다 작은 값, 오른쪽 노드는 해당 노드보다 큰 값을 갖는 추가적인 조건 이 있는 트리
- 평균 탐색시간은 O(logN), 최악 탐색시간은 O(N)
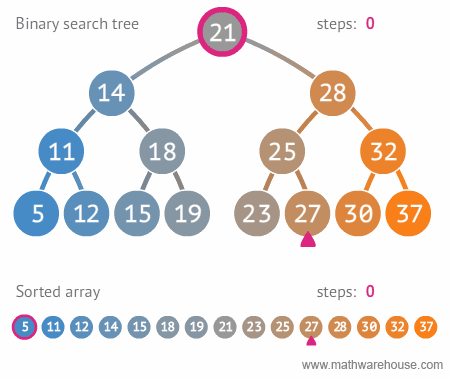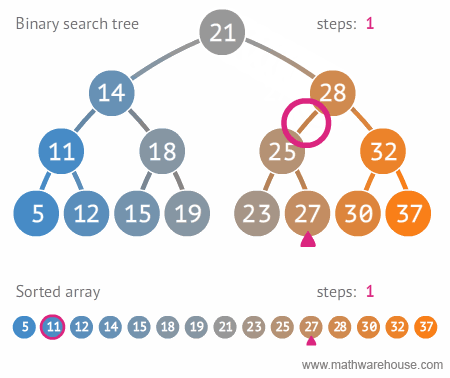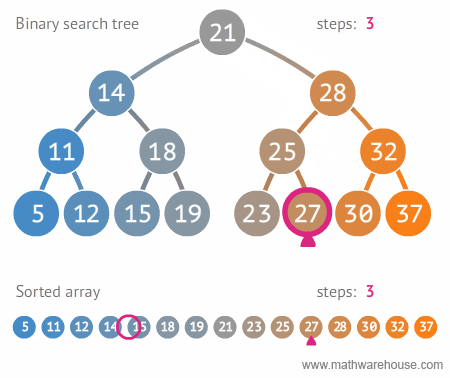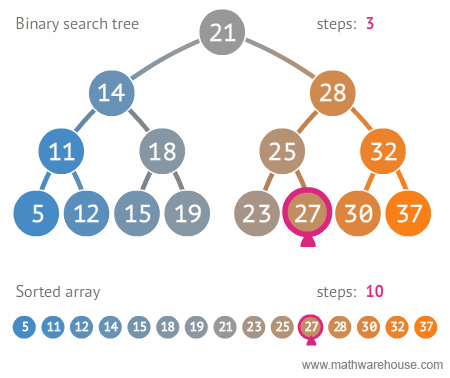
- 데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree)
- 힙을 사용하는 이유
- 배열에 데이터를 넣고, 최대값과 최소값을 찾으려면 O(n)이 걸림 vs 힙에 데이터를 넣고, 최대값과 최소값을 찾으면 O(logN)이 걸림
- 우선순위 큐와 같이 최대값 또는 최소값을 빠르게 찾아야 하는 자료구조 및 알고리즘 구현 등에 활용됨
- 최대값을 구하기 위한 MaxHeap과, 최소값을 구하기 위한 MinHeap으로 분류
- MaxHeap의 경우, 각 노드의 값은 해당 노드의 자식 노드가 가진 값보다 크거나 같다.
- MinHeap의 경우, 각 노드의 값은 해당 노드의 자식 노드가 가진 값보다 작거나 같다.

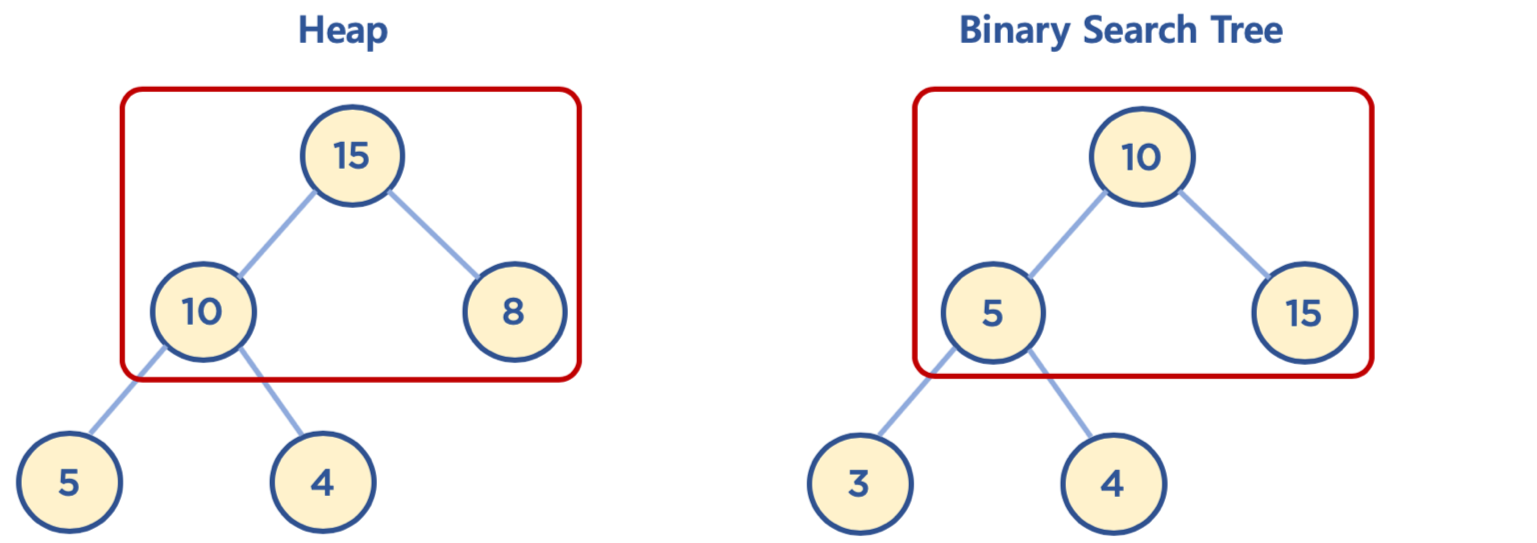
- 공통점: 힙과 이진 탐색 트리는 모두 이진 트리임
- 차이점:
- 힙은 각 노드의 값이 자식 노드보다 크거나 같음(Max Heap의 경우)
- 이진 탐색 트리는 왼쪽 자식 노드의 값이 가장 작고, 그 다음 부모 노드, 그 다음 오른쪽 자식 노드 값이 가장 큼
- 힙은 이진 탐색 트리의 조건인 자식 노드에서 작은 값은 왼쪽, 큰 값은 오른쪽이라는 조건은 없음
- 힙의 왼쪽 및 오른쪽 자식 노드의 값은 오른쪽이 클 수도 있고, 왼쪽이 클 수도 있음
- 이진 탐색 트리는 탐색을 위한 구조, 힙은 최대/최소값 검색을 위한 구조 중 하나로 이해하면 됨
- 파이썬
heapq모듈은 MinHeap의 형태로 정렬되는 heapq(proiority queue)알고리즘을 제공한다. - heapq.heappush(heap, item) : item을 heap에 추가
- heapq.heappop(heap) : heap에서 가장 작은 원소를 pop & 리턴. 비어 있는 경우 IndexError가 호출됨.
- heapq.heapify(x) : 리스트 x를 즉각적으로 heap으로 변환함 (in linear time, O(N))
- 파이썬
heapq모듈은 MinHeap으로 구현되어있으므로 MaxHeap구현을 위해서는 y=-x 변환을 하여 최솟값 정렬이 최댓값 정렬로 바뀌게 하는 아이디어가 필요하다.
import heapq
# heap 빈 리스트 생성 후 item 추가
heap = []
heapq.heappush(heap, 50)
heapq.heappush(heap, 10)
heapq.heappush(heap, 20)
print(heap) # [10, 50, 20]
# 이미 생성해둔 리스트를 heapify 함수 이용하여 힙 자료형으로 변환
heap2 = [50, 10, 20]
heapq.heapify(heap2)
print(heap2) # [10, 50, 20]
# 힙에서 원소 삭제
result = heapq.heappop(heap)
print(result) # 10
print(heap) # [20, 50]
# 원소를 삭제하지 않고 가져오고 싶다면 [0]인덱싱으로 접근
result2 = heap[0]
print(result2) # 20
print(heap) # [20, 50]
# MaxHeap 만들기
heap_items = [1,3,5,7,9]
max_heap = []
for item in heap_items:
heapq.heappush(max_heap, (-item, item))
print(max_heap) # [(-9, 9), (-7, 7), (-3, 3), (-1, 1), (-5, 5)]
# 인덱싱 활용하여 실제 원소값에 접근
max_item = heapq.heappop(max_heap)[1]
print(max_item) # 9