人工智能实践:Tensorflow笔记 https://www.icourse163.org/learn/PKU-1002536002
class4自制数据集数据文件 https://gitee.com/jlfff/tf_studynotes_2/releases/v.001
| 维数 | 阶 | 名字 | 例子 |
|---|---|---|---|
| 0-D | 0 | 标量scalar | s = 1 |
| 1-D | 1 | 向量vector | v = [1, 2, 3],shape=(3,) |
| 2-D | 2 | 矩阵matrix | m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
| n-D | n | 张量tensor | t = [[[ |
-
数据类型(常用):
tf.int32tf.float32tf.float64tf.booltf.string -
创建数据:
tf.constant(张量内容, dtype=tf.float32)tf.constant([True, False])tf.constant("Hello World") -
np convert to tf:
a = np.arange(0, 5) b = tf.convert_to_tensor(a, dtype=tf.int64) -
zeros, ones, fill:
a = tf.zeros([2, 3]) #全为0的张量,[维度] b = tf.ones(4) #全为1的张量 c = tf.fill([2, 2], 9) #全为9的张量 -
正太分布随机函数:
d = tf.random.normal([2,2], mean=0.5, stddev=1)维度,均值,标准差 -
截断式正太分布随机数:
e = tf.random.truncated_normal([2, 2], mean=0.5, stddev=1) -
均匀分布随机函数:
f = tf.random.uniform([2, 2], minval=0, maxval=1)维度,最小值,最大值 -
强制转换类型:
x2 = tf.cast(tf.constant([1., 2., 3.], dtype=tf.float64), tf.int32)数据,数据类型 -
最大/最小值:
tf.reduce_min(x2)tf.reduce_max(x2) -
平均值:
tf.reduce_mean(x, axis=0)#axis可选axis=0代表每个垂直方向rank -
总和:
tf.reduce_sum(x, axis=1)axis=1代表每个横向row -
独热码: 将数据由小到大排列,
labels = tf.constant([1, 0, 2]) # 输入的元素值最小为0,最大为2 output = tf.one_hot(labels, depth=3, on_value=None, #固定最大值,1的位置 off_value=None, #固定最小值,0的位置 axis=None, dtype=None, name=None ) print("result of labels1:", output)
x_train.shape(50000, 32, 32, 3)#5w个,32行,32列,三(通道)堆叠数据
常用内容
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.python.keras import Model
from PIL import Image
import time
mnist = tf.keras.datasets.mnist
cifar10 = tf.keras.datasets.cifar10
fashion = tf.keras.datasets.fashion_mnist
#存入训练集,测试集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
#预处理
x_train, x_test = x_train / 255.0, x_test / 255.0 #归一化
(注意import)from sklearn import datasets
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 给数据增加一个维度,从(60000, 28, 28)reshape为(60000, 28, 28, 1)
# 60000张 28*28的图 → → → 60000张 28*28 单通道的灰度图
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
image_gen_train = ImageDataGenerator(
rescale=1. / 1., # 如为图像,分母为255时,可归至0~1
rotation_range=45, # 随机45度旋转
width_shift_range=.15, # 宽度偏移
height_shift_range=.15, # 高度偏移
horizontal_flip=False, # 水平翻转
zoom_range=0.5 # 将图像随机缩放阈量50%
)
image_gen_train.fit(x_train)
model = 略
model.fit(image_gen_train.flow(x_train, y_train, batch_size=32), epochs=5, validation_data=(x_test, y_test),
validation_freq=1)
#设定路径
train_path = './mnist_image_label/mnist_train_jpg_60000/'
train_txt = './mnist_image_label/mnist_train_jpg_60000.txt'
x_train_savepath = './mnist_image_label/mnist_x_train.npy'
y_train_savepath = './mnist_image_label/mnist_y_train.npy'
test_path = './mnist_image_label/mnist_test_jpg_10000/'
test_txt = './mnist_image_label/mnist_test_jpg_10000.txt'
x_test_savepath = './mnist_image_label/mnist_x_test.npy'
y_test_savepath = './mnist_image_label/mnist_y_test.npy'
#
def generateds(path, txt):
f = open(txt, 'r') # 以只读形式打开txt文件
contents = f.readlines() # 读取文件中所有行
f.close() # 关闭txt文件
x, y_ = [], [] # 建立空列表
for content in contents: # 逐行取出
value = content.split() # 以空格分开,图片路径为value[0] , 标签为value[1] , 存入列表
img_path = path + value[0] # 拼出图片路径和文件名
img = Image.open(img_path) # 读入图片
img = np.array(img.convert('L')) # 图片变为8位宽灰度值的np.array格式
img = img / 255. # 数据归一化 (实现预处理)
x.append(img) # 归一化后的数据,贴到列表x
y_.append(value[1]) # 标签贴到列表y_
print('loading : ' + content) # 打印状态提示
x = np.array(x) # 变为np.array格式
y_ = np.array(y_) # 变为np.array格式
y_ = y_.astype(np.int64) # 变为64位整型
return x, y_ # 返回输入特征x,返回标签y_
#判定是否存在npy文件
if os.path.exists(x_train_savepath) and os.path.exists(y_train_savepath) and os.path.exists(x_test_savepath) and os.path.exists(y_test_savepath):
print('-------------Load Datasets-----------------')
x_train_save = np.load(x_train_savepath)
y_train = np.load(y_train_savepath)
x_test_save = np.load(x_test_savepath)
y_test = np.load(y_test_savepath)
x_train = np.reshape(x_train_save, (len(x_train_save), 28, 28))#三维数组,数量,行,列 60000个
x_test = np.reshape(x_test_save, (len(x_test_save), 28, 28))
else:
print('-------------Generate Datasets-----------------')
x_train, y_train = generateds(train_path, train_txt)
x_test, y_test = generateds(test_path, test_txt)
print('-------------Save Datasets-----------------')
x_train_save = np.reshape(x_train, (len(x_train), -1))#60000个(x_train为用于reshape),(len(x_train),-1)铺成一个行向量[1 1 1 1 1 1 1 1 1 1 ]
x_test_save = np.reshape(x_test, (len(x_test), -1))
np.save(x_train_savepath, x_train_save)
np.save(y_train_savepath, y_train)
np.save(x_test_savepath, x_test_save)
np.save(y_test_savepath, y_test)
- 拉直层:
tf.keras.layers.Flatten(data_format=None) - 全连接层:
tf.keras.layers.Dense( units, #神经元个数 activation=None, use_bias=True, kernel_initializer="glorot_uniform", bias_initializer="zeros", #哪种正则化 kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None, ) - 卷积层:
tf.keras.layers.Conv2D( filters, #卷积核个数 kernel_size, #卷积核尺寸 strides=(1, 1), 卷积步长 padding="valid", #one of "valid" or "same" data_format=None, dilation_rate=(1, 1), groups=1, activation=None, use_bias=True, #使用偏置 kernel_initializer="glorot_uniform", bias_initializer="zeros", kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None, ) - LSTM层
layer-activation-functions文档详情
- relu function
tf.keras.activations.relu(x, alpha=0.0, max_value=None, threshold=0.0)使用默认值,这将返回标准 ReLU 激活:max(x, 0)、元素方面的最大值 0 和输入张量 x 。 - sigmoid function
tf.keras.activations.sigmoid(x)sigmoid(x) = 1 / (1 + exp(-x)) sigmoid 函数总是返回 0 到 1 之间的值。 - softmax function
tf.keras.activations.softmax(x, axis=-1)Softmax 将值向量转换为概率分布。 输出向量的元素在 (0, 1) 范围内并且总和为 1。 每个向量都是独立处理的。 axis 参数设置应用函数的输入轴。 Softmax 通常用作分类网络最后一层的激活,因为结果可以解释为概率分布。 每个向量 x 的 softmax 计算为 exp(x) / tf.reduce_sum(exp(x))。 输入值是结果概率的对数比值。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
#模板
class MyModel(Model):#表述继承了tensorflow的Model类
def __init__(self, data):
super(MyModel, self).__init__()
self.d1 = Dense(data)
def call(self, x):
y = self.d1(x)
return y
model = MyModel(3) #model传入class类中self,值 3 传入data
#5P27
class Baseline(Model):
def __init__(self):
super(Baseline, self).__init__()
self.c1 = Conv2D(filters=6, kernel_size=(5, 5), padding='same') # 卷积层
self.b1 = BatchNormalization() # BN层
self.a1 = Activation('relu') # 激活层
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same') # 池化层
self.d1 = Dropout(0.2) # dropout层
self.flatten = Flatten()
self.f1 = Dense(128, activation='relu')
self.d2 = Dropout(0.2)
self.f2 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.d1(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d2(x)
y = self.f2(x)
return y
model = Baseline()
配置训练方法(告知用哪种训练器,选择哪个损失函数,选择哪种评测指标)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
- optimizer可选:sgd、adagrad、adadelta、adam
- loss可选:'mse' or tf.keras.losses.SparseCategoricalCrossentropy稀疏分类交叉熵,False代表数据不经过概率分布,用于配合softmax
- metrics:
name content accuracy y_(标签值)和y(输出)均为数值 categorical_accuracu y_、y均为独热码 sparse_categorical_accuracy y_是数值、y是one-hot
执行训练过程(告知训练集和测试集的输入特征和标签,batch,迭代次数)
model.fit(x_train, y_train, batch_size=32, epochs=5, #epochs迭代轮数
validation_data=(x_test, y_test), #测试集的输入特征和标签
validation_split=0.2, #从训练集划分多少比例给测试集
validation_freq=1)#多少次epochs测试一次
位于model.compile后
checkpoint_save_path = "./checkpoint/mnist.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
#print(model.trainable_variables)#可训练参数,将此存入到同目录下的weights.txt
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
特征图对应元素相加(矩阵叠加) 图中共有 4 个 block_list,一共 8 个 ResNet18 块,每一个 ResNet18 块有两层卷积,一共 18 层网络。

class ResNet18(Model):
#block_list 值由 model = ResNet18([2, 2, 2, 2])传入
def __init__(self, block_list, initial_filters=64): # block_list表示每个block有几个卷积层
super(ResNet18, self).__init__()
self.num_blocks = len(block_list) # 共有几个block
self.block_list = block_list
self.out_filters = initial_filters
self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
「——— self.blocks = tf.keras.models.Sequential()
| # 构建ResNet网络结构
| for block_id in range(len(block_list)): # 第几个resnet block
| for layer_id in range(block_list[block_id]): # 第几个卷积层
|
| if block_id != 0 and layer_id == 0: # 对除第一个block以外的每个block的输入进行下采样
| block = ResnetBlock(self.out_filters, strides=2, residual_path=True)
| else:
| block = ResnetBlock(self.out_filters, residual_path=False)
﹂------------ self.blocks.add(block) # 将构建好的block加入resnet
self.out_filters *= 2 # 下一个block的卷积核数是上一个block的2倍
self.p1 = tf.keras.layers.GlobalAveragePooling2D()
self.f1 = tf.keras.layers.Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, inputs):
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = ResNet18([2, 2, 2, 2])

- 代码
tf.keras.layers.SimpleRNN(
units, #记忆体个数
activation="tanh", #不写,默认tanh
use_bias=True,
kernel_initializer="glorot_uniform",
recurrent_initializer="orthogonal",
bias_initializer="zeros",
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.0,
recurrent_dropout=0.0,
return_sequences=False, #是否每个时刻输出ht到下一层,true各时间步输出ht,false仅最后时间步输出ht
#一般最后一层用false
return_state=False,
go_backwards=False,
stateful=False,
unroll=False,
**kwargs
)
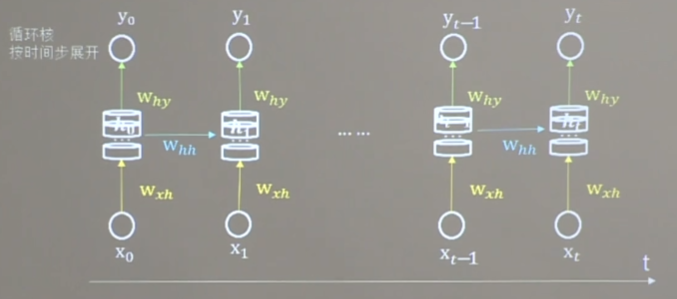
return_sequences=True情况
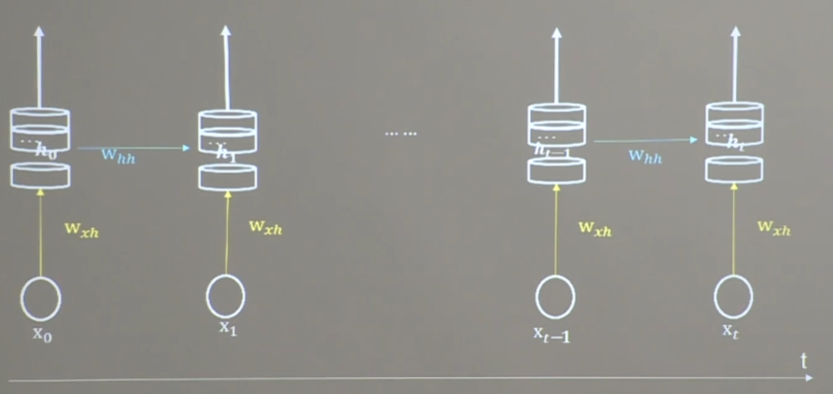
return_sequences=False情况

- 入RNN时,x_train维度: [送入样本数, 循环核时间展开数, 每个时间步输入特征个数]
一个循环核,按时间展开为1 [[0.4, 1.7, 0.6], [0.7, 0.9, 1.6]] RNN层期待维度:[2, 1, 3]
tf.concat(values, axis, name='concat')
- 其他:
tf.tile, tf.stack, tf.repeat. - 例子:
二维例子:
t1 = [[1, 2, 3], [4, 5, 6]]
t2 = [[7, 8, 9], [10, 11, 12]]
tf.concat([t1, t2], 0)
<tf.Tensor: shape=(4, 3), dtype=int32, numpy=
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]], dtype=int32)>
tf.concat([t1, t2], 1)
<tf.Tensor: shape=(2, 6), dtype=int32, numpy=
array([[ 1, 2, 3, 7, 8, 9],
[ 4, 5, 6, 10, 11, 12]], dtype=int32)>
- 也可以使用-1来表示axis,此时axis值由张量的列(rank)决定,当列为2,axis = -1 等同为 axis = (rank - 1)
- 预期串联维度在范围[-2,2)内
t1 = [[[1, 2], [2, 3]], [[4, 4], [5, 3]]]
t2 = [[[7, 4], [8, 4]], [[2, 10], [15, 11]]]
tf.concat([t1, t2], -1)
<tf.Tensor: shape=(2, 2, 4), dtype=int32, numpy=
array([[[ 1, 2, 7, 4],
[ 2, 3, 8, 4]],
[[ 4, 4, 2, 10],
[ 5, 3, 15, 11]]], dtype=int32)>
- 事实上大多数为三维数据,在这种情况下,axis=0代表的第一个维度的含义就不再是之前认为的行的概念了。
- 现在m1的第一维度的值是5,代表的是batch_size。仍然按照之前的理解,如果设置axis=0, axis=0就是将第一维度进行相加,其余维度不变,因此我们可以得到新的维度为(10,2,3)。
- 该预期串联维度在范围[-3,3)内
m1 = np.random.rand(5,2,3)
m2 = np.random.rand(5,2,3)
tf.concat([m1, m2], axis=0)
tf.Tensor(
[[[0.34430633 0.83003857 0.08612483]
[0.43257428 0.78452211 0.3509124 ]]
[[0.10208814 0.2321127 0.53013603]
[0.74482931 0.16760063 0.97408543]]
[[0.87906564 0.03753782 0.510531 ]
[0.45497528 0.3593978 0.75307507]]
[[0.78037273 0.32377479 0.96719595]
[0.87993334 0.33868999 0.83029079]]
[[0.22404866 0.14638118 0.07120537]
[0.91046574 0.6792461 0.09362955]]
[[0.17840385 0.66975948 0.40993195]
[0.64724555 0.16046651 0.20704188]]
[[0.7262562 0.11734689 0.24886733]
[0.71797053 0.99384083 0.2016469 ]]
[[0.44709938 0.00857796 0.31161445]
[0.97663824 0.8088507 0.36269392]]
[[0.07919517 0.46861975 0.46980364]
[0.1881042 0.8369626 0.30829756]]
[[0.49074451 0.86899614 0.64748985]
[0.4549892 0.22440097 0.70472271]]], shape=(10, 2, 3), dtype=float64)
- 某些时候,同一层中使用concat函数,例如
x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3) - 同一卷积层,堆叠4个分支
#CBA同类
class ConvBNRelu(Model):
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.model = tf.keras.models.Sequential([
Conv2D(ch, kernelsz, strides=strides, padding=padding),
BatchNormalization(),
Activation('relu')
])
def call(self, x):
x = self.model(x, training=False) #在training=False时,BN通过整个训练集计算均值、方差去做批归一化,training=True时,通过当前batch的均值、方差去做批归一化。推理时 training=False效果好
return x
class InceptionBlk(Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__()
self.ch = ch
self.strides = strides
self.c1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_2 = ConvBNRelu(ch, kernelsz=3, strides=1)
self.c3_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c3_2 = ConvBNRelu(ch, kernelsz=5, strides=1)
self.p4_1 = MaxPool2D(3, strides=1, padding='same')
self.c4_2 = ConvBNRelu(ch, kernelsz=1, strides=strides)
def call(self, x):
x1 = self.c1(x)
x2_1 = self.c2_1(x)
x2_2 = self.c2_2(x2_1)
x3_1 = self.c3_1(x)
x3_2 = self.c3_2(x3_1)
x4_1 = self.p4_1(x)
x4_2 = self.c4_2(x4_1)
# concat along axis=channel
x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3)
return x
df.iloc[a,b],其中df是DataFrame数据结构的数据(表1就是df),a是行索引(见表1),b是列索引(见表1)。
| 姓名(列索引10) | 班级(列索引1) | 分数(列索引2) | |
|---|---|---|---|
| row0 | 小明 | 302 | 87 |
| row1 | 小翠 | 303 | 93 |
| row2 | 小青 | 304 | 88 |
In[10]: data.loc[data['A']==0] #提取data数据(筛选条件: A列中数字为0所在的行数据)
Out[10]:
A B C D
a 0 1 2 3
In[11]: data.loc[(data['A']==0)&(data['B']==2)] #提取data数据(多个筛选条件)
Out[11]:
A B C D
a 0 1 2 3