-
Notifications
You must be signed in to change notification settings - Fork 13
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
294 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,294 @@ | ||
| { | ||
| "cells": [ | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "## MNIST classification\n", | ||
| "\n", | ||
| "In this notebook we tackle the perhaps most well known problem in all of machine learning, classifying hand-written digits.\n", | ||
| "\n", | ||
| "The particular dataset we will use is the MNIST (Modified National Institute of Standards and Technology)\n", | ||
| "The digits are 28x28 pixel images that look somewhat like this:\n", | ||
| "\n", | ||
| "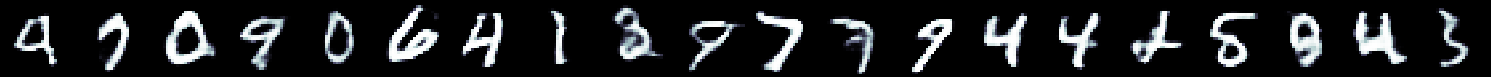\n", | ||
| "\n", | ||
| "Each digit has been hand classified, e.g. for the above 9-7-0-9-0-...\n", | ||
| "\n", | ||
| "Our task is to teach a machine to perform this classification." | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Import dependencies\n", | ||
| "\n", | ||
| "This should run without errors if all dependencies are installed properly." | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 1, | ||
| "metadata": { | ||
| "collapsed": true, | ||
| "scrolled": true | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "import tensorflow as tf\n", | ||
| "import matplotlib.pyplot as plt\n", | ||
| "import numpy as np\n", | ||
| "from tensorflow.examples.tutorials.mnist import input_data" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 2, | ||
| "metadata": { | ||
| "collapsed": true, | ||
| "scrolled": true | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "# Start a tensorflow session\n", | ||
| "session = tf.InteractiveSession()\n", | ||
| "\n", | ||
| "# Set the random seed to enable reproducible code\n", | ||
| "np.random.seed(0)" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Get data and utilities\n", | ||
| "\n", | ||
| "We now need to get the data we will use, which in this case is the famous [MNIST](http://yann.lecun.com/exdb/mnist/) dataset, a set of digits 70000 hand-written digits, of which 60000 are used for training and 10000 for testing.\n", | ||
| "\n", | ||
| "In addition to this, we create a utility `generate_data` which generates sinograms for each digit, as well as a function `evaluate(...)` that we will use to evaluate how good the classification is." | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 3, | ||
| "metadata": { | ||
| "scrolled": true | ||
| }, | ||
| "outputs": [ | ||
| { | ||
| "name": "stdout", | ||
| "output_type": "stream", | ||
| "text": [ | ||
| "Extracting MNIST_data\\train-images-idx3-ubyte.gz\n", | ||
| "Extracting MNIST_data\\train-labels-idx1-ubyte.gz\n", | ||
| "Extracting MNIST_data\\t10k-images-idx3-ubyte.gz\n", | ||
| "Extracting MNIST_data\\t10k-labels-idx1-ubyte.gz\n" | ||
| ] | ||
| } | ||
| ], | ||
| "source": [ | ||
| "# Get MNIST data\n", | ||
| "mnist = input_data.read_data_sets('MNIST_data')" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 4, | ||
| "metadata": { | ||
| "scrolled": true | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "# Read the 10000 mnist test points\n", | ||
| "batch = mnist.test.next_batch(10000)\n", | ||
| "test_images = batch[0].reshape([-1, 28, 28, 1])\n", | ||
| "test_labels = batch[1]\n", | ||
| "\n", | ||
| "def evaluate(result_tensor, data_placeholder):\n", | ||
| " \"\"\"Evaluate a reconstruction method.\n", | ||
| "\n", | ||
| " Parameters\n", | ||
| " ----------\n", | ||
| " result_tensor : `tf.Tensor`, shape (None,)\n", | ||
| " The tensorflow tensor containing the result of the classification.\n", | ||
| " data_placeholder : `tf.Tensor`, shape (None, 28, 28, 1)\n", | ||
| " The tensorflow tensor containing the input to the classification operator.\n", | ||
| "\n", | ||
| " Returns\n", | ||
| " -------\n", | ||
| " MSE : float\n", | ||
| " Mean squared error of the reconstruction.\n", | ||
| " \"\"\"\n", | ||
| " result = result_tensor.eval(\n", | ||
| " feed_dict={data_placeholder: test_images})\n", | ||
| "\n", | ||
| " return np.mean(result == test_labels)" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 5, | ||
| "metadata": { | ||
| "collapsed": true, | ||
| "scrolled": true | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "# Create placeholders. Placeholders are needed in tensorflow since tensorflow is a lazy language,\n", | ||
| "# and hence we first define the computational graph with placeholders as input, and later we evaluate it.\n", | ||
| "with tf.name_scope('placeholders'):\n", | ||
| " images = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])\n", | ||
| " true_labels = tf.placeholder(tf.int32, shape=[None])" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Logistic regression\n", | ||
| "\n", | ||
| "INSERT TEXT" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 6, | ||
| "metadata": { | ||
| "scrolled": true | ||
| }, | ||
| "outputs": [ | ||
| { | ||
| "name": "stdout", | ||
| "output_type": "stream", | ||
| "text": [ | ||
| "0 Average correct: 0.117\n", | ||
| "1000 Average correct: 0.8998\n", | ||
| "2000 Average correct: 0.9156\n", | ||
| "3000 Average correct: 0.9142\n", | ||
| "4000 Average correct: 0.9168\n", | ||
| "5000 Average correct: 0.9157\n", | ||
| "6000 Average correct: 0.9218\n", | ||
| "7000 Average correct: 0.9229\n", | ||
| "8000 Average correct: 0.9229\n", | ||
| "9000 Average correct: 0.9265\n" | ||
| ] | ||
| } | ||
| ], | ||
| "source": [ | ||
| "with tf.name_scope('logistic_regression'):\n", | ||
| " x = tf.contrib.layers.flatten(images)\n", | ||
| " pred_one_hot = tf.contrib.layers.fully_connected(x, 10,\n", | ||
| " activation_fn=tf.nn.softmax)\n", | ||
| " pred = tf.argmax(pred_one_hot, axis=1)\n", | ||
| " \n", | ||
| "with tf.name_scope('optimizer'):\n", | ||
| " one_hot_labels = tf.one_hot(true_labels, depth=10)\n", | ||
| " \n", | ||
| " loss = tf.reduce_mean((pred_one_hot - one_hot_labels) ** 2)\n", | ||
| " optimizer = tf.train.AdamOptimizer().minimize(loss)\n", | ||
| "\n", | ||
| "# Initialize all TF variables\n", | ||
| "session.run(tf.global_variables_initializer())\n", | ||
| "\n", | ||
| "for i in range(10000):\n", | ||
| " batch = mnist.train.next_batch(10)\n", | ||
| " train_images = batch[0].reshape([-1, 28, 28, 1])\n", | ||
| " train_labels = batch[1]\n", | ||
| "\n", | ||
| " session.run(optimizer, feed_dict={images: train_images, \n", | ||
| " true_labels: train_labels})\n", | ||
| "\n", | ||
| " if i % 1000 == 0:\n", | ||
| " print('{} Average correct: {}'.format(\n", | ||
| " i, evaluate(pred, images)))" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Convolutional network\n", | ||
| "\n", | ||
| "INSERT TEXT" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 7, | ||
| "metadata": { | ||
| "scrolled": true | ||
| }, | ||
| "outputs": [ | ||
| { | ||
| "name": "stdout", | ||
| "output_type": "stream", | ||
| "text": [ | ||
| "0 Average correct: 0.0998\n", | ||
| "1000 Average correct: 0.9379\n", | ||
| "2000 Average correct: 0.9562\n", | ||
| "3000 Average correct: 0.9655\n", | ||
| "4000 Average correct: 0.9665\n", | ||
| "5000 Average correct: 0.9724\n", | ||
| "6000 Average correct: 0.9679\n", | ||
| "7000 Average correct: 0.977\n", | ||
| "8000 Average correct: 0.9755\n", | ||
| "9000 Average correct: 0.9766\n" | ||
| ] | ||
| } | ||
| ], | ||
| "source": [ | ||
| "with tf.name_scope('convolutional_network'):\n", | ||
| " x = tf.contrib.layers.conv2d(images, num_outputs=32, kernel_size=3, stride=2)\n", | ||
| " x = tf.contrib.layers.conv2d(x, num_outputs=32, kernel_size=3, stride=2)\n", | ||
| " x = tf.contrib.layers.flatten(x)\n", | ||
| " \n", | ||
| " pred_one_hot = tf.contrib.layers.fully_connected(x, 10,\n", | ||
| " activation_fn=tf.nn.softmax)\n", | ||
| " pred = tf.argmax(pred_one_hot, axis=1)\n", | ||
| " \n", | ||
| "with tf.name_scope('optimizer'):\n", | ||
| " one_hot_labels = tf.one_hot(true_labels, depth=10)\n", | ||
| " \n", | ||
| " loss = tf.reduce_mean((pred_one_hot - one_hot_labels) ** 2)\n", | ||
| " optimizer = tf.train.AdamOptimizer().minimize(loss)\n", | ||
| "\n", | ||
| "# Initialize all TF variables\n", | ||
| "session.run(tf.global_variables_initializer())\n", | ||
| "\n", | ||
| "for i in range(10000):\n", | ||
| " batch = mnist.train.next_batch(10)\n", | ||
| " train_images = batch[0].reshape([-1, 28, 28, 1])\n", | ||
| " train_labels = batch[1]\n", | ||
| "\n", | ||
| " session.run(optimizer, feed_dict={images: train_images, \n", | ||
| " true_labels: train_labels})\n", | ||
| "\n", | ||
| " if i % 1000 == 0:\n", | ||
| " print('{} Average correct: {}'.format(\n", | ||
| " i, evaluate(pred, images)))" | ||
| ] | ||
| } | ||
| ], | ||
| "metadata": { | ||
| "kernelspec": { | ||
| "display_name": "Python 3", | ||
| "language": "python", | ||
| "name": "python3" | ||
| }, | ||
| "language_info": { | ||
| "codemirror_mode": { | ||
| "name": "ipython", | ||
| "version": 3 | ||
| }, | ||
| "file_extension": ".py", | ||
| "mimetype": "text/x-python", | ||
| "name": "python", | ||
| "nbconvert_exporter": "python", | ||
| "pygments_lexer": "ipython3", | ||
| "version": "3.5.3" | ||
| } | ||
| }, | ||
| "nbformat": 4, | ||
| "nbformat_minor": 2 | ||
| } |