
Superheros come to save the day! Source: Marjan Blan, unsplash.com
Trying to determine if a superhero is good or bad from text. A Natural Language Processing Model based on a dataset from Kaggle Kernels.
- Introduction
- README Outline
- Repo Contents
- Libraries and Prerequisites
- Feature and Definitions
- Models
- Conclusions
- Future Work
- Built With, Contributors, Authors, Acknowledgments

Using 'text' not 'photographs' to determine who is who in the hero world! Source: Marjan Blan, Unsplash.com
This repo contains the following:
- README.md - this is where you are now!
- Superhero_NLP_Notebook.ipynb - the Jupyter Notebook containing the finalized code for this project.
- LICENSE.md - the required license information.
- Data - superheroes_nlp_dataset.csv
- CONTRIBUTING.md
- Images - contains the fun images to this repo.
- gitignore
These are the libraries that I used in this project.
-
import pandas as pd
-
import numpy as np
-
import matplotlib.pyplot as plt
-
%matplotlib inline
-
import seaborn as sns
-
import string, re
-
import nltk
-
from nltk import FreqDist, word_tokenize
-
from nltk.corpus import stopwords
-
from sklearn.feature_extraction.text import TfidfVectorizer
-
from sklearn.model_selection import train_test_split
-
from sklearn.metrics import accuracy_score
-
from sklearn.ensemble import RandomForestClassifier
-
from sklearn.naive_bayes import MultinomialNB
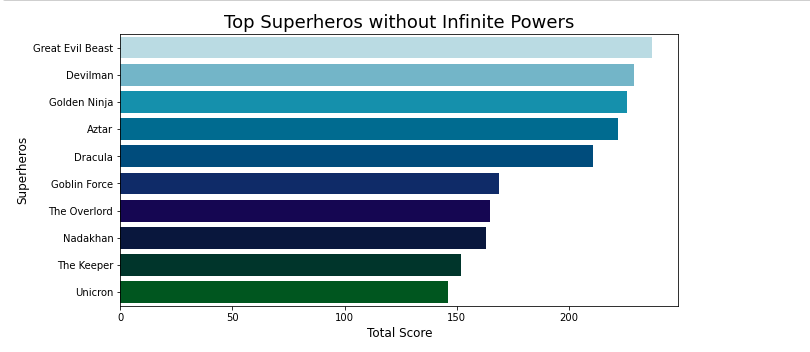
Bar graph of Superheros ranked by total powers. Source: Superhero_NLP_Notebook.ipynb
There are 81 columns in this dataset. Below is a sample of some of the ones I used:
- 0 name 1448 non-null object
- 1 real_name 1301 non-null object
- 2 full_name 956 non-null object
- 3 overall_score 1450 non-null object
- 4 history_text 1360 non-null object
- 5 powers_text 1086 non-null object
- 6 intelligence_score 1450 non-null int64
- 7 strength_score 1450 non-null int64
- 8 speed_score 1450 non-null int64
- 9 durability_score 1450 non-null int64
- 10 power_score 1450 non-null int64
- 11 combat_score 1450 non-null int64
- 12 superpowers 1450 non-null object
- 13 alter_egos 1450 non-null object
- 14 aliases 1450 non-null object
- 15 place_of_birth 788 non-null object
- 16 first_appearance 1247 non-null object
- 17 creator 1311 non-null object
- 18 alignment 1368 non-null object The majority of the rest of the features are floats, describing the superhero powers as a number.
Naive Bayes and Random Forest
There is so much more I want to do! I still have a lot to learn about text pre-processing - including how to put it all into a nice easy function.
.jpg)
Is this one of the good guys! Source: Yulia Matvienko, unsplash.com
Jupyter Notebook Python 3.0 scikit.learn
Please read CONTRIBUTING.md for details
Thomas Whipple
Please read LICENSE.md for details
Kaggle - This dataset comes from the following: https://www.kaggle.com/jonathanbesomi/superheroes-nlp-dataset