Hunt for the highest MAP #2313
Comments
|
👋 Hello @tiwarikaran, thank you for your interest in 🚀 YOLOv5! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution. If this is a 🐛 Bug Report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you. If this is a custom training ❓ Question, please provide as much information as possible, including dataset images, training logs, screenshots, and a public link to online W&B logging if available. For business inquiries or professional support requests please visit https://www.ultralytics.com or email Glenn Jocher at glenn.jocher@ultralytics.com. RequirementsPython 3.8 or later with all requirements.txt dependencies installed, including $ pip install -r requirements.txtEnvironmentsYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training (train.py), testing (test.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu every 24 hours and on every commit. |


|
👋 Hello @tiwarikaran! Thanks for asking about improving training results. Most of the time good results can be obtained with no changes to the models or training settings, provided your dataset is sufficiently large and well labelled. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users first train with all default settings before considering any changes. This helps establish a performance baseline and spot areas for improvement. If you have questions about your training results we recommend you provide the maximum amount of information possible if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your We've put together a full guide for users looking to get the best results on their YOLOv5 trainings below. Dataset
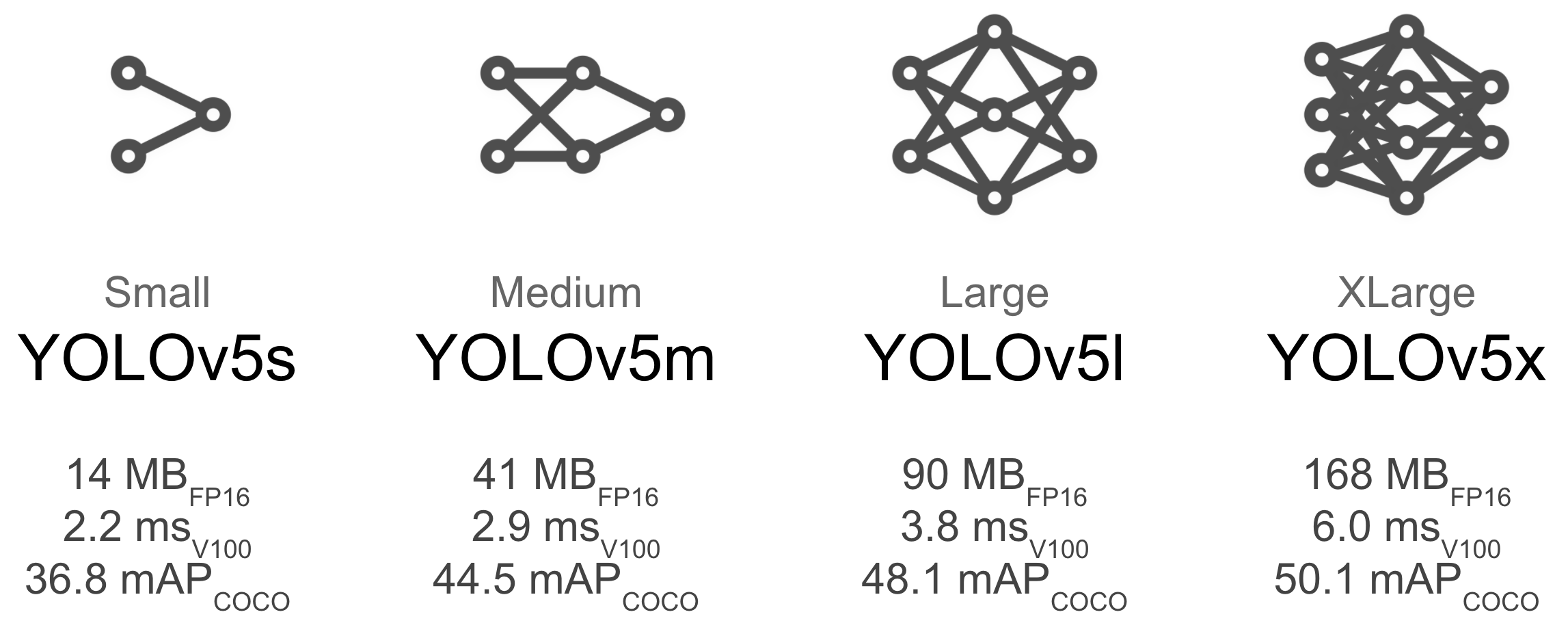
Model SelectionLarger models like YOLOv5x will produce better results in nearly all cases, but have more parameters and are slower to run. For mobile applications we recommend YOLOv5s/m, for cloud or desktop applications we recommend YOLOv5l/x. See our README table for a full comparison of all models. To start training from pretrained weights simply pass the name of the model to the python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
Training SettingsBefore modifying anything, first train with default settings to establish a performance baseline. A full list of train.py settings can be found in the train.py argparser.
|

|
Hello @glenn-jocher your wonderful and insightful comment has helped me in many unexpected ways, I thought lets write it out and try if some fellow student like me is kinda free to share his knowledge. Thanks again for this. I tried to run the same code today afternoon and it seemed to give me wonderful results, here's a snippet of the metrics from the latest experiment I ran.
Also when I saw your profile and learnt you're one of the many people who've made YOLO what it is today. I would say using the yolov5 is more easier than many of the auto ML libraries there exist. Yolov4 said that "this" should be accessible to everyone. V5 stands firmly on those grounds. PS YOLO (you only look once) is hands down the coolest name for an algorithm that exists in Computer Vision. |

|
@tiwarikaran thanks buddy! Yes, looking at your results everything looks good, though as the guide says since your val losses have not started overfitting you can actually benefit from even longer training, i.e. 2k or 3k epochs. Sometimes with small datasets especially much longer training is required to get the best results. |
|
@tiwarikaran also you should be very careful with your labels, I noticed not all instances are labelled in all images, which is going to produce worse results. |
@glenn-jocher Is there no way to apply early stopping? I can see we're getting a Lines 376 to 379 in c2026a5 Is it similar to what other kind of models are doing in image classification when they stop the training of the model if the validation loss stops decreasing after X epochs (named "patience")? To reformulate my question: is it safe to always use the Thanks! |
|
@kinoute I think 'early stopping' term is used widely in TF and officially supported there, but you are right there is no comparable functionality here. So if you train with --epochs 1000 and overfitting occurs after 100 epochs it will keep training all the way to 1000. best.pt will work as intended, saved at the maximum fitness. We used to define fitness as inverse val loss (so best.pt would be saved at the min val loss epoch), but based on user feedback we changed this to the current combination of metrics. The two are usually never the same epoch, but instead are in the same vicinity. Still, users don't like to see best.pt test to a lower mAP than the best mAP observed in training. The most important point though in the above user guide is that you want to observe some overfitting in your results. If validation loss is lowest at the final epoch as in #2313 (comment) then you are not achieving your best performance, and should restart your training with longer epochs. |
Add the ability to create a dataset/splits only with images that have an annotation file, i.e a .txt file, associated to it. As we talked about this, the absence of a txt file could mean two things: * either the image wasn't yet labelled by someone, * either there is no object to detect. When it's easy to create small datasets, when you have to create datasets with thousands of images (and more coming), it's hard to track where you at and you don't want to wait to have all of them annotated before starting to train. Which means some images would lack txt files and annotations, resulting in label inconsistency as you say in ultralytics#2313. By adding the annotated_only argument to the function, people could create, if they want to, datasets/splits only with images that were labelled, for sure.
* Be able to create dataset from annotated images only Add the ability to create a dataset/splits only with images that have an annotation file, i.e a .txt file, associated to it. As we talked about this, the absence of a txt file could mean two things: * either the image wasn't yet labelled by someone, * either there is no object to detect. When it's easy to create small datasets, when you have to create datasets with thousands of images (and more coming), it's hard to track where you at and you don't want to wait to have all of them annotated before starting to train. Which means some images would lack txt files and annotations, resulting in label inconsistency as you say in #2313. By adding the annotated_only argument to the function, people could create, if they want to, datasets/splits only with images that were labelled, for sure. * Cleanup and update print() Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com>
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
@glenn-jocher Not sure if it's already the case but your comment #2313 (comment) is great and it might be a good idea to add it to the Wiki! |
* Be able to create dataset from annotated images only Add the ability to create a dataset/splits only with images that have an annotation file, i.e a .txt file, associated to it. As we talked about this, the absence of a txt file could mean two things: * either the image wasn't yet labelled by someone, * either there is no object to detect. When it's easy to create small datasets, when you have to create datasets with thousands of images (and more coming), it's hard to track where you at and you don't want to wait to have all of them annotated before starting to train. Which means some images would lack txt files and annotations, resulting in label inconsistency as you say in ultralytics#2313. By adding the annotated_only argument to the function, people could create, if they want to, datasets/splits only with images that were labelled, for sure. * Cleanup and update print() Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com>
* Update yolo.py with yaml.SafeLoader (ultralytics#1970) * Update autoanchor.py with yaml.SafeLoader (ultralytics#1971) * Update train.py with yaml.SafeLoader (ultralytics#1972) * check_git_status() asserts (ultralytics#1977) * Update Dockerfile (ultralytics#1982) * Add xywhn2xyxy() (ultralytics#1983) * verbose on final_epoch (ultralytics#1997) * check_git_status() Windows fix (ultralytics#2015) * check_git_status() Windows fix * Update general.py * Update general.py * Update general.py * Update general.py * Update general.py * Update general.py * Update Dockerfile (ultralytics#2016) * Update google_utils.py (ultralytics#2017) * Update ci-testing.yml (ultralytics#2018) * Update inference multiple-counting (ultralytics#2019) * Update inference multiple-counting * update github check * Update general.py check_git_status() fix (ultralytics#2020) * Update autoshape .print() and .save() (ultralytics#2022) * Update requirements.txt (ultralytics#2021) * Update requirements.txt * Update ci-testing.yml * Update hubconf.py * PyYAML==5.4.1 (ultralytics#2030) * Docker pyYAML>=5.3.1 fix (ultralytics#2031) * data-autodownload background tasks (ultralytics#2034) * Check im.format during dataset caching (ultralytics#2042) * Check im.format during dataset caching * Update datasets.py * Confusion matrix native image-space fix (ultralytics#2046) Make sure the labels and predictions are equally scaled on confusion_matrix.process_batch * Add histogram equalization fcn (ultralytics#2049) * W&B log epoch (ultralytics#1946) * W&B log epoch * capitalize * W&B log epoch * capitalize * Update train.py New try using https://docs.wandb.ai/library/log#incremental-logging * Update train.py * Update test.py * Update train.py * Update plots.py * Update train.py * Update train.py * label plot step -1 * update * update * update * update * update * update * Update train.py * Update train.py * Add 'exclude' tuple to check_requirements() (ultralytics#2041) * Update run-once lines (ultralytics#2058) * Metric-Confidence plots feature addition (ultralytics#2057) * Metric-Confidence plots feature addition * cleanup * Metric-Confidence plots feature addition * cleanup * Update run-once lines * cleanup * save all 4 curves to wandb * Update to colors.TABLEAU_COLORS (ultralytics#2069) * W&B epoch logging update (ultralytics#2073) * GhostConv update (ultralytics#2082) * Add YOLOv5-P6 models (ultralytics#2083) * Update tutorial.ipynb * Add Amazon Deep Learning AMI environment (ultralytics#2085) * Update greetings.yml * Update README.md * Add Kaggle badge (ultralytics#2090) * Update README.md * Update greetings.yml * Created using Colaboratory * Add Kaggle badge (ultralytics#2090) * Add variable-stride inference support (ultralytics#2091) * Update test.py --task speed and study (ultralytics#2099) * Add --speed benchmark * test range 256 - 1536 * update * update * update * update * Update plot_study() (ultralytics#2112) * Start setup for improved W&B integration (ultralytics#1948) * Add helper functions for wandb and artifacts * cleanup * Reorganize files * Update wandb_utils.py * Update log_dataset.py We can remove this code, as the giou hyp has been deprecated for a while now. * Reorganize and update dataloader call * yaml.SafeLoader * PEP8 reformat * remove redundant checks * Add helper functions for wandb and artifacts * cleanup * Reorganize files * Update wandb_utils.py * Update log_dataset.py We can remove this code, as the giou hyp has been deprecated for a while now. * Reorganize and update dataloader call * yaml.SafeLoader * PEP8 reformat * remove redundant checks * Update util files * Update wandb_utils.py * Remove word size * Change path of labels.zip * remove unused imports * remove --rect * log_dataset.py cleanup * log_dataset.py cleanup2 * wandb_utils.py cleanup * remove redundant id_count * wandb_utils.py cleanup2 * rename cls * use pathlib for zip * rename dataloader to dataset * Change import order * Remove redundant code * remove unused import * remove unused imports Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * LoadImages() pathlib update (ultralytics#2140) * Unique *.cache filenames fix (ultralytics#2134) * fix ultralytics#2121 * Update test.py * Update train.py * Update autoanchor.py * Update datasets.py * Update log_dataset.py * Update datasets.py Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Update train.py test batch_size (ultralytics#2148) * Update train.py * Update loss.py * Update train.py (ultralytics#2149) * Linear LR scheduler option (ultralytics#2150) * Linear LR scheduler option * Update train.py * Update data-autodownload background tasks (ultralytics#2154) * Update get_coco.sh * Update get_voc.sh * Update detect.py (ultralytics#2167) Without this cv2.imshow opens a window but nothing is visible * Update requirements.txt (ultralytics#2173) * Update utils/datasets.py to support .webp files (ultralytics#2174) Simply added 'webp' as an image format to the img_formats array so that webp image files can be used as training data. * Changed socket port and added timeout (ultralytics#2176) * PyTorch Hub results.save('path/to/dir') (ultralytics#2179) * YOLOv5 Segmentation Dataloader Updates (ultralytics#2188) * Update C3 module * Update C3 module * Update C3 module * Update C3 module * update * update * update * update * update * update * update * update * update * updates * updates * updates * updates * updates * updates * updates * updates * updates * updates * update * update * update * update * updates * updates * updates * updates * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update datasets * update * update * update * update attempt_downlaod() * merge * merge * update * update * update * update * update * update * update * update * update * update * parameterize eps * comments * gs-multiple * update * max_nms implemented * Create one_cycle() function * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * GitHub API rate limit fix * update * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * astuple * epochs * update * update * ComputeLoss() * update * update * update * update * update * update * update * update * update * update * update * merge * merge * merge * merge * update * update * update * update * commit=tag == tags[-1] * Update cudnn.benchmark * update * update * update * updates * updates * updates * updates * updates * updates * updates * update * update * update * update * update * mosaic9 * update * update * update * update * update * update * institute cache versioning * only display on existing cache * reverse cache exists booleans * Created using Colaboratory * YOLOv5 PyTorch Hub results.save() method retains filenames (ultralytics#2194) * save results with name * debug * save original imgs names * Update common.py Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * TTA augument boxes one pixel shifted in de-flip ud and lr (ultralytics#2219) * TTA augument boxes one pixel shifted in de-flip ud and lr * PEP8 reformat Co-authored-by: Jaap van de Loosdrecht <jaap.van.de.loosdrecht@nhlstenden.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * LoadStreams() frame loss bug fix (ultralytics#2222) * Update yolo.py channel array (ultralytics#2223) * Add check_imshow() (ultralytics#2231) * Add check_imshow() * Update general.py * Update general.py * Update CI badge (ultralytics#2230) * Add isdocker() (ultralytics#2232) * Add isdocker() * Update general.py * Update general.py * YOLOv5 Hub URL inference bug fix (ultralytics#2250) * Update common.py * Update common.py * Update common.py * Improved hubconf.py CI tests (ultralytics#2251) * Unified hub and detect.py box and labels plotting (ultralytics#2243) * reset head * Update inference default to multi_label=False (ultralytics#2252) * Update inference default to multi_label=False * bug fix * Update plots.py * Update plots.py * Robust objectness loss balancing (ultralytics#2256) * Created using Colaboratory * Update minimum stride to 32 (ultralytics#2266) * Dynamic ONNX engine generation (ultralytics#2208) * add: dynamic onnx export * delete: test onnx inference * fix dynamic output axis * Code reduction * fix: dynamic output axes, dynamic input naming * Remove fixed axes Co-authored-by: Shivam Swanrkar <ss8464@nyu.edu> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Update greetings.yml for auto-rebase on PR (ultralytics#2272) * Update Dockerfile with apt install zip (ultralytics#2274) * FLOPS min stride 32 (ultralytics#2276) Signed-off-by: xiaowo1996 <429740343@qq.com> * Update README.md * Amazon AWS EC2 startup and re-startup scripts (ultralytics#2185) * Amazon AWS EC2 startup and re-startup scripts * Create resume.py * cleanup * Amazon AWS EC2 startup and re-startup scripts (ultralytics#2282) * Update train.py (ultralytics#2290) * Update train.py * Update train.py * Update train.py * Update train.py * Create train.py * Improved model+EMA checkpointing (ultralytics#2292) * Enhanced model+EMA checkpointing * update * bug fix * bug fix 2 * always save optimizer * ema half * remove model.float() * model half * carry ema/model in fp32 * rm model.float() * both to float always * cleanup * cleanup * Improved model+EMA checkpointing 2 (ultralytics#2295) * Fix labels being missed when image extension appears twice in filename (ultralytics#2300) * W&B entity support (ultralytics#2298) * W&B entity support * shorten wandb_entity to entity Co-authored-by: Jan Hajek <jan.hajek@gmail.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Update yolo.py (ultralytics#2120) * Avoid mutable state in Detect * LoadImages() pathlib update (ultralytics#2140) * Unique *.cache filenames fix (ultralytics#2134) * fix ultralytics#2121 * Update test.py * Update train.py * Update autoanchor.py * Update datasets.py * Update log_dataset.py * Update datasets.py Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Update train.py test batch_size (ultralytics#2148) * Update train.py * Update loss.py * Update train.py (ultralytics#2149) * Linear LR scheduler option (ultralytics#2150) * Linear LR scheduler option * Update train.py * Update data-autodownload background tasks (ultralytics#2154) * Update get_coco.sh * Update get_voc.sh * Update detect.py (ultralytics#2167) Without this cv2.imshow opens a window but nothing is visible * Update requirements.txt (ultralytics#2173) * Update utils/datasets.py to support .webp files (ultralytics#2174) Simply added 'webp' as an image format to the img_formats array so that webp image files can be used as training data. * Changed socket port and added timeout (ultralytics#2176) * PyTorch Hub results.save('path/to/dir') (ultralytics#2179) * YOLOv5 Segmentation Dataloader Updates (ultralytics#2188) * Update C3 module * Update C3 module * Update C3 module * Update C3 module * update * update * update * update * update * update * update * update * update * updates * updates * updates * updates * updates * updates * updates * updates * updates * updates * update * update * update * update * updates * updates * updates * updates * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update datasets * update * update * update * update attempt_downlaod() * merge * merge * update * update * update * update * update * update * update * update * update * update * parameterize eps * comments * gs-multiple * update * max_nms implemented * Create one_cycle() function * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * update * GitHub API rate limit fix * update * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * ComputeLoss * astuple * epochs * update * update * ComputeLoss() * update * update * update * update * update * update * update * update * update * update * update * merge * merge * merge * merge * update * update * update * update * commit=tag == tags[-1] * Update cudnn.benchmark * update * update * update * updates * updates * updates * updates * updates * updates * updates * update * update * update * update * update * mosaic9 * update * update * update * update * update * update * institute cache versioning * only display on existing cache * reverse cache exists booleans * Created using Colaboratory * YOLOv5 PyTorch Hub results.save() method retains filenames (ultralytics#2194) * save results with name * debug * save original imgs names * Update common.py Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * TTA augument boxes one pixel shifted in de-flip ud and lr (ultralytics#2219) * TTA augument boxes one pixel shifted in de-flip ud and lr * PEP8 reformat Co-authored-by: Jaap van de Loosdrecht <jaap.van.de.loosdrecht@nhlstenden.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * LoadStreams() frame loss bug fix (ultralytics#2222) * Update yolo.py channel array (ultralytics#2223) * Add check_imshow() (ultralytics#2231) * Add check_imshow() * Update general.py * Update general.py * Update CI badge (ultralytics#2230) * Add isdocker() (ultralytics#2232) * Add isdocker() * Update general.py * Update general.py * YOLOv5 Hub URL inference bug fix (ultralytics#2250) * Update common.py * Update common.py * Update common.py * Improved hubconf.py CI tests (ultralytics#2251) * Unified hub and detect.py box and labels plotting (ultralytics#2243) * reset head * Update inference default to multi_label=False (ultralytics#2252) * Update inference default to multi_label=False * bug fix * Update plots.py * Update plots.py * Robust objectness loss balancing (ultralytics#2256) * Created using Colaboratory * Update minimum stride to 32 (ultralytics#2266) * Dynamic ONNX engine generation (ultralytics#2208) * add: dynamic onnx export * delete: test onnx inference * fix dynamic output axis * Code reduction * fix: dynamic output axes, dynamic input naming * Remove fixed axes Co-authored-by: Shivam Swanrkar <ss8464@nyu.edu> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Update greetings.yml for auto-rebase on PR (ultralytics#2272) * Update Dockerfile with apt install zip (ultralytics#2274) * FLOPS min stride 32 (ultralytics#2276) Signed-off-by: xiaowo1996 <429740343@qq.com> * Update README.md * Amazon AWS EC2 startup and re-startup scripts (ultralytics#2185) * Amazon AWS EC2 startup and re-startup scripts * Create resume.py * cleanup * Amazon AWS EC2 startup and re-startup scripts (ultralytics#2282) * Update train.py (ultralytics#2290) * Update train.py * Update train.py * Update train.py * Update train.py * Create train.py * Improved model+EMA checkpointing (ultralytics#2292) * Enhanced model+EMA checkpointing * update * bug fix * bug fix 2 * always save optimizer * ema half * remove model.float() * model half * carry ema/model in fp32 * rm model.float() * both to float always * cleanup * cleanup * Improved model+EMA checkpointing 2 (ultralytics#2295) * Fix labels being missed when image extension appears twice in filename (ultralytics#2300) * W&B entity support (ultralytics#2298) * W&B entity support * shorten wandb_entity to entity Co-authored-by: Jan Hajek <jan.hajek@gmail.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Avoid mutable state in Detect * Update yolo and remove .to(device) Co-authored-by: Oleg Boiko <oboiko@chegg.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: train255 <thanhdd.it@gmail.com> Co-authored-by: ab-101 <56578530+ab-101@users.noreply.github.com> Co-authored-by: Transigent <wbdsmith@optusnet.com.au> Co-authored-by: NanoCode012 <kevinvong@rocketmail.com> Co-authored-by: Daniel Khromov <danielkhromov@gmail.com> Co-authored-by: VdLMV <jaap@vdlmv.nl> Co-authored-by: Jaap van de Loosdrecht <jaap.van.de.loosdrecht@nhlstenden.com> Co-authored-by: Yann Defretin <kinoute@gmail.com> Co-authored-by: Aditya Lohia <64709773+aditya-dl@users.noreply.github.com> Co-authored-by: Shivam Swanrkar <ss8464@nyu.edu> Co-authored-by: xiaowo1996 <429740343@qq.com> Co-authored-by: Iden Craven <iden.craven@gmail.com> Co-authored-by: Jan Hajek <toretak@users.noreply.github.com> Co-authored-by: Jan Hajek <jan.hajek@gmail.com> * final_epoch EMA bug fix (ultralytics#2317) * Update test.py (ultralytics#2319) * Update Dockerfile install htop (ultralytics#2320) * remove TTA 1 pixel offset (ultralytics#2325) * EMA bug fix 2 (ultralytics#2330) * EMA bug fix 2 * update * FROM nvcr.io/nvidia/pytorch:21.02-py3 (ultralytics#2341) * Confusion matrix background axis swap (ultralytics#2114) * Created using Colaboratory * Anchor override (ultralytics#2350) * Resume with custom anchors fix (ultralytics#2361) * Resume with custom anchors fix * Update train.py * Faster random index generator for mosaic augmentation (ultralytics#2345) * faster random index generator for mosaic augementation We don't need to access list to generate random index It makes augmentation slower. * Update datasets.py Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * --no-cache notebook (ultralytics#2381) * ENV HOME=/usr/src/app (ultralytics#2382) Set HOME environment variable per Binder requirements. https://github.com/binder-examples/minimal-dockerfile * image weights compatible faster random index generator v2 for mosaic augmentation (ultralytics#2383) image weights compatible faster random index generator v2 for mosaic augmentation * GPU export options (ultralytics#2297) * option for skip last layer and cuda export support * added parameter device * fix import * cleanup 1 * cleanup 2 * opt-in grid --grid will export with grid computation, default export will skip grid (same as current) * default --device cpu GPU export causes ONNX and CoreML errors. Co-authored-by: Jan Hajek <jan.hajek@gmail.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * bbox_iou() stability and speed improvements (ultralytics#2385) * AWS wait && echo "All tasks done." (ultralytics#2391) * GCP sudo docker userdata.sh (ultralytics#2393) * GCP sudo docker * cleanup * CVPR 2021 Argoverse-HD dataset autodownload support (ultralytics#2400) * added argoverse-download ability * bugfix * add support for Argoverse dataset * Refactored code * renamed to argoverse-HD * unzip -q and YOLOv5 small cleanup items * add image counts Co-authored-by: Kartikeya Sharma <kartikes@trinity.vision.cs.cmu.edu> Co-authored-by: Kartikeya Sharma <kartikes@trinity-0-32.eth> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * CVPR 2021 Argoverse-HD autodownload fix (ultralytics#2418) * DDP after autoanchor reorder (ultralytics#2421) * Integer printout (ultralytics#2450) * Integer printout * test.py 'Labels' * Update train.py * Update test.py --task train val study (ultralytics#2453) * Update test.py --task train val study * update argparser --task * labels.jpg class names (ultralytics#2454) * labels.png class names * fontsize=10 * CVPR 2021 Argoverse-HD autodownload curl (ultralytics#2455) curl preferred over wget for slightly better cross platform compatibility (i.e. out of the box macos compatible). * Add autoShape() speed profiling (ultralytics#2459) * Add autoShape() speed profiling * Update common.py * Create README.md * Update hubconf.py * cleanuip * autoShape() speed profiling update (ultralytics#2460) * Update tutorial.ipynb * Created using Colaboratory * Update autosplit() with annotated_only option (ultralytics#2466) * Be able to create dataset from annotated images only Add the ability to create a dataset/splits only with images that have an annotation file, i.e a .txt file, associated to it. As we talked about this, the absence of a txt file could mean two things: * either the image wasn't yet labelled by someone, * either there is no object to detect. When it's easy to create small datasets, when you have to create datasets with thousands of images (and more coming), it's hard to track where you at and you don't want to wait to have all of them annotated before starting to train. Which means some images would lack txt files and annotations, resulting in label inconsistency as you say in ultralytics#2313. By adding the annotated_only argument to the function, people could create, if they want to, datasets/splits only with images that were labelled, for sure. * Cleanup and update print() Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Scipy kmeans-robust autoanchor update (ultralytics#2470) Fix for ultralytics#2394 * PyTorch Hub models default to CUDA:0 if available (ultralytics#2472) * PyTorch Hub models default to CUDA:0 if available * device as string bug fix * Created using Colaboratory * Improved W&B integration (ultralytics#2125) * Init Commit * new wandb integration * Update * Use data_dict in test * Updates * Update: scope of log_img * Update: scope of log_img * Update * Update: Fix logging conditions * Add tqdm bar, support for .txt dataset format * Improve Result table Logger * Init Commit * new wandb integration * Update * Use data_dict in test * Updates * Update: scope of log_img * Update: scope of log_img * Update * Update: Fix logging conditions * Add tqdm bar, support for .txt dataset format * Improve Result table Logger * Add dataset creation in training script * Change scope: self.wandb_run * Add wandb-artifact:// natively you can now use --resume with wandb run links * Add suuport for logging dataset while training * Cleanup * Fix: Merge conflict * Fix: CI tests * Automatically use wandb config * Fix: Resume * Fix: CI * Enhance: Using val_table * More resume enhancement * FIX : CI * Add alias * Get useful opt config data * train.py cleanup * Cleanup train.py * more cleanup * Cleanup| CI fix * Reformat using PEP8 * FIX:CI * rebase * remove uneccesary changes * remove uneccesary changes * remove uneccesary changes * remove unecessary chage from test.py * FIX: resume from local checkpoint * FIX:resume * FIX:resume * Reformat * Performance improvement * Fix local resume * Fix local resume * FIX:CI * Fix: CI * Imporve image logging * (:(:Redo CI tests:):) * Remember epochs when resuming * Remember epochs when resuming * Update DDP location Potential fix for ultralytics#2405 * PEP8 reformat * 0.25 confidence threshold * reset train.py plots syntax to previous * reset epochs completed syntax to previous * reset space to previous * remove brackets * reset comment to previous * Update: is_coco check, remove unused code * Remove redundant print statement * Remove wandb imports * remove dsviz logger from test.py * Remove redundant change from test.py * remove redundant changes from train.py * reformat and improvements * Fix typo * Add tqdm tqdm progress when scanning files, naming improvements Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Update Detections() times=None (ultralytics#2570) Fix for results.tolist() method breaking after YOLOv5 Hub profiling PRshttps://github.com/ultralytics/pull/2460 ultralytics#2459 and * check_requirements() exclude pycocotools, thop (ultralytics#2571) Exclude non-critical packages from dependency checks in detect.py. pycocotools and thop in particular are not required for inference. Issue first raised in ultralytics#1944 and also raised in ultralytics#2556 * W&B DDP fix (ultralytics#2574) * Enhanced check_requirements() with auto-install (ultralytics#2575) * Update check_requirements() with auto-install This PR builds on an idea I had to automatically install missing dependencies rather than simply report an error message. YOLOv5 should now 1) display all dependency issues and not simply display the first missing dependency, and 2) attempt to install/update each missing/VersionConflict package. * cleanup * cleanup 2 * Check requirements.txt file exists * cleanup 3 * Update tensorboard>=2.4.1 (ultralytics#2576) * Update tensorboard>=2.4.1 Update tensorboard version to attempt to address ultralytics#2573 (tensorboard logging fail in Docker image). * cleanup * YOLOv5 PyTorch Hub models >> check_requirements() (ultralytics#2577) * Update hubconf.py with check_requirements() Dependency checks have been missing from YOLOv5 PyTorch Hub model loading, causing errors in some cases when users are attempting to import hub models in unsupported environments. This should examine the YOLOv5 requirements.txt file and pip install any missing or version-conflict packages encountered. This is highly experimental (!), please let us know if this creates problems in your custom workflows. * Update hubconf.py * W&B DDP fix 2 (ultralytics#2587) Revert unintentional change to test batch sizes caused by PR ultralytics#2125 * YOLOv5 PyTorch Hub models >> check_requirements() (ultralytics#2588) * YOLOv5 PyTorch Hub models >> check_requirements() Update YOLOv5 PyTorch Hub requirements.txt path to cache path. * Update hubconf.py * YOLOv5 PyTorch Hub models >> check_requirements() (ultralytics#2591) Prints 'Please restart runtime or rerun command for update to take effect.' following package auto-install to inform users to restart/rerun. * YOLOv5 PyTorch Hub models >> check_requirements() (ultralytics#2592) Improved user-feedback following requirements auto-update. * Supervisely Ecosystem (ultralytics#2519) guide describes YOLOv5 apps collection in Supervisely Ecosystem * Save webcam results, add --nosave option (ultralytics#2598) This updates the default detect.py behavior to automatically save all inference images/videos/webcams unless the new argument --nosave is used (python detect.py --nosave) or unless a list of streaming sources is passed (python detect.py --source streams.txt) * Update segment2box() comment (ultralytics#2600) * resume.py typo (ultralytics#2603) * Remove Cython from requirements.txt (ultralytics#2604) Cython should be a dependency of the remaining packages in requirements.txt, so should be installed anyway even if not a direct requirement. * Update git_describe() for remote dir usage (ultralytics#2606) * Add '*.mpo' to supported image formats (ultralytics#2615) Co-authored-by: Max Uppenkamp <max.uppenkamp@inform-software.com> * Create date_modified() (ultralytics#2616) Updated device selection string with fallback for non-git directories. ```python def select_device(device='', batch_size=None): # device = 'cpu' or '0' or '0,1,2,3' s = f'YOLOv5 🚀 {git_describe() or date_modified()} torch {torch.__version__} ' # string ... ``` * Update detections() self.t = tuple() (ultralytics#2617) * Update detections() self.t = tuple() Fix multiple results.print() bug. * Update experimental.py * Update yolo.py * Fix Indentation in test.py (ultralytics#2614) * Fix Indentation in test.py * CI fix * Comply with PEP8: 80 characters per line * Update Detections() self.n comment (ultralytics#2620) ```python self.n = len(self.pred) # number of images (batch size) ``` * Remove conflicting nvidia-tensorboard package (ultralytics#2622) Attempt to resolve tensorboard Docker error in ultralytics#2573 * FROM nvcr.io/nvidia/pytorch:21.03-py3 (ultralytics#2623) Update Docker FROM nvcr.io/nvidia/pytorch:21.03-py3 * Improve git_describe() (ultralytics#2633) Catch 'fatal: not a git repository' returns and return '' instead (observed in GCP Hub checks). * Fix: evolve with wandb (ultralytics#2634) * W&B resume ddp from run link fix (ultralytics#2579) * W&B resume ddp from run link fix * Native DDP W&B support for training, resuming * Improve git_describe() fix 1 (ultralytics#2635) Add stderr=subprocess.STDOUT to catch error messages. * PyTorch Hub custom model to CUDA device fix (ultralytics#2636) Fix for ultralytics#2630 raised by @Pro100rus32 * PyTorch Hub amp.autocast() inference (ultralytics#2641) I think this should help speed up CUDA inference, as currently models may be running in FP32 inference mode on CUDA devices unnecesarily. * Add tqdm pbar.close() (ultralytics#2644) When using tqdm, sometimes it can't print in one line and roll to next line. * Speed profiling improvements (ultralytics#2648) * Speed profiling improvements * Update torch_utils.py deepcopy() required to avoid adding elements to model. * Update torch_utils.py * Created using Colaboratory (ultralytics#2649) * Update requirements.txt (ultralytics#2564) * Add opencv-contrib-python to requirements.txt * Update requirements.txt Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * add option to disable half precision in test.py (ultralytics#2507) Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Add --label-smoothing eps argument to train.py (default 0.0) (ultralytics#2344) * Add label smoothing option * Correct data type * add_log * Remove log * Add log * Update loss.py remove comment (too versbose) Co-authored-by: phattran <phat.tranhoang@cyberlogitec.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Created using Colaboratory * Set resume flag to false (ultralytics#2657) * Update README.md * Created using Colaboratory * Update README with Tips for Best Results tutorial (ultralytics#2682) * Update README with Tips for Best Results tutorial * Update README.md * Add TransformerLayer, TransformerBlock, C3TR modules (ultralytics#2333) * yolotr * transformer block * Remove bias in Transformer * Remove C3T * Remove a deprecated class * put the 2nd LayerNorm into the 2nd residual block * move example model to models/hub, rename to -transformer * Add module comments and TODOs * Remove LN in Transformer * Add comments for Transformer * Solve the problem of MA with DDP * cleanup * cleanup find_unused_parameters * PEP8 reformat Co-authored-by: DingYiwei <846414640@qq.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Fix: ultralytics#2674 (ultralytics#2683) * Set resume flag to false * Check existance of val dataset * PyTorch Hub model.save() increment as runs/hub/exp (ultralytics#2684) * PyTorch Hub model.save() increment as runs/hub/exp This chane will align PyTorch Hub results saving with the existing unified results saving directory structure of runs/ /train /detect /test /hub /exp /exp2 ... * cleanup * autoShape forward im = np.asarray(im) # to numpy (ultralytics#2689) Slight speedup. * pip install coremltools onnx (ultralytics#2690) Requested in ultralytics#2686 * Updated filename attributes for YOLOv5 Hub results (ultralytics#2708) Proposed fix for 'Model predict with forward will fail if PIL image does not have filename attribute' ultralytics#2702 * Updated filename attributes for YOLOv5 Hub BytesIO (ultralytics#2718) Fix 2 for 'Model predict with forward will fail if PIL image does not have filename attribute' ultralytics#2702 * Add support for list-of-directory data format for wandb (ultralytics#2719) * Update README with collapsable notes (ultralytics#2721) * Update README with collapsable notes. * cleanup * center table * Add Hub results.pandas() method (ultralytics#2725) * Add Hub results.pandas() method New method converts results from torch tensors to pandas DataFrames with column names. This PR may partially resolve issue ultralytics#2703 ```python results = model(imgs) print(results.pandas().xyxy[0]) xmin ymin xmax ymax confidence class name 0 57.068970 391.770599 241.383545 905.797852 0.868964 0 person 1 667.661255 399.303589 810.000000 881.396667 0.851888 0 person 2 222.878387 414.774231 343.804474 857.825073 0.838376 0 person 3 4.205386 234.447678 803.739136 750.023376 0.658006 5 bus 4 0.000000 550.596008 76.681190 878.669922 0.450596 0 person ``` * Update comments torch example input now shown resized to size=640 and also now a multiple of P6 stride 64 (see ultralytics#2722 (comment)) * apply decorators * PEP8 * Update common.py * pd.options.display.max_columns = 10 * Update common.py * autocast enable=torch.cuda.is_available() (ultralytics#2748) * torch.cuda.amp bug fix (ultralytics#2750) PR ultralytics#2725 introduced a very specific bug that only affects multi-GPU trainings. Apparently the cause was using the torch.cuda.amp decorator in the autoShape forward method. I've implemented amp more traditionally in this PR, and the bug is resolved. * utils/wandb_logging PEP8 reformat (ultralytics#2755) * wandb_logging PEP8 reformat * Update wandb_utils.py * Tensorboard model visualization bug fix (ultralytics#2758) This fix should allow for visualizing YOLOv5 model graphs correctly in Tensorboard by uncommenting line 335 in train.py: ```python if tb_writer: tb_writer.add_graph(torch.jit.trace(model, imgs, strict=False), []) # add model graph ``` The problem was that the detect() layer checks the input size to adapt the grid if required, and tracing does not seem to like this shape check (even if the shape is fine and no grid recomputation is required). The following will warn: https://github.com/ultralytics/yolov5/blob/0cae7576a9241110157cd154fc2237e703c2719e/train.py#L335 Solution is below. This is a YOLOv5s model displayed in TensorBoard. You can see the Detect() layer merging the 3 layers into a single output for example, and everything appears to work and visualize correctly. ```python tb_writer.add_graph(torch.jit.trace(model, imgs, strict=False), []) ``` <img width="893" alt="Screenshot 2021-04-11 at 01 10 09" src="https://user-images.githubusercontent.com/26833433/114286928-349bd600-9a63-11eb-941f-7139ee6cd602.png"> * Created using Colaboratory * YouTube Livestream Detection (ultralytics#2752) * Youtube livestream detection * dependancy update to auto install pafy * Remove print * include youtube_dl in deps * PEP8 reformat * youtube url check fix * reduce lines * add comment * update check_requirements * stream framerate fix * Update README.md * cleanup * PEP8 * remove cap.retrieve() failure code Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * YOLOv5 v5.0 Release (ultralytics#2762) * YOLOv5 v5.0 Release patch 1 (ultralytics#2764) * torch.jit.trace(model, img, strict=False) * Update check_file() * Update hubconf.py * Update README.md * Update tutorial.ipynb * Created using Colaboratory * Update tutorial.ipynb * Created using Colaboratory * Created using Colaboratory * Update README.md * Flask REST API Example (ultralytics#2732) * add files * Update README.md * Update README.md * Update restapi.py pretrained=True and model.eval() are used by default when loading a model now, so no need to call them manually. * PEP8 reformat * PEP8 reformat Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Update README.md * ONNX Simplifier (ultralytics#2815) * ONNX Simplifier Add ONNX Simplifier to ONNX export pipeline in export.py. Will auto-install onnx-simplifier if onnx is installed but onnx-simplifier is not. * Update general.py * YouTube Bug Fix (ultralytics#2818) Fix for ultralytics#2810 ```shell python detect.py --source 0 ``` introduced by YouTube Livestream Detection PR ultralytics#2752 * PyTorch Hub cv2 .save() .show() bug fix (ultralytics#2831) * PyTorch Hub cv2 .save() .show() bug fix cv2.rectangle() was failing on non-contiguous np array inputs. This checks for contiguous arrays and applies is necessary: ```python imgs[i] = im if im.data.contiguous else np.ascontiguousarray(im) # update ``` * Update plots.py ```python assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to plot_on_box() input image.' ``` * Update hubconf.py Expand CI tests to OpenCV image. * Create FUNDING.yml (ultralytics#2832) * Update FUNDING.yml (ultralytics#2833) * Update FUNDING.yml * move FUNDING.yml to ./github * Fix ONNX dynamic axes export support with onnx simplifier, make onnx simplifier optional (ultralytics#2856) * Ensure dynamic export works succesfully, onnx simplifier optional * Update export.py * add dashes Co-authored-by: Tim <tim.stokman@hal24k.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Update increment_path() to handle file paths (ultralytics#2867) * Detection cropping+saving feature addition for detect.py and PyTorch Hub (ultralytics#2827) * Update detect.py * Update detect.py * Update greetings.yml * Update cropping * cleanup * Update increment_path() * Update common.py * Update detect.py * Update detect.py * Update detect.py * Update common.py * cleanup * Update detect.py Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Implement yaml.safe_load() (ultralytics#2876) * Implement yaml.safe_load() * yaml.safe_dump() * Cleanup load_image() (ultralytics#2871) * don't resize up in load_image if augmenting * cleanup Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * bug fix: switched rows and cols for correct detections in confusion matrix (ultralytics#2883) * VisDrone2019-DET Dataset Auto-Download (ultralytics#2882) * VisDrone Dataset Auto-Download * add visdrone.yaml * cleanup * add VisDrone2019-DET-test-dev * cleanup VOC * Uppercase model filenames enabled (ultralytics#2890) * ACON activation function (ultralytics#2893) * ACON Activation Function ## 🚀 Feature There is a new activation function [ACON (CVPR 2021)](https://arxiv.org/pdf/2009.04759.pdf) that unifies ReLU and Swish. ACON is simple but very effective, code is here: https://github.com/nmaac/acon/blob/main/acon.py#L19  The improvements are very significant:  ## Alternatives It also has an enhanced version meta-ACON that uses a small network to learn beta explicitly, which may influence the speed a bit. ## Additional context [Code](https://github.com/nmaac/acon) and [paper](https://arxiv.org/pdf/2009.04759.pdf). * Update activations.py * Explicit opt function arguments (ultralytics#2817) * more explicit function arguments * fix typo in detect.py * revert import order * revert import order * remove default value * Update yolo.py (ultralytics#2899) * Update google_utils.py (ultralytics#2900) * Add detect.py --hide-conf --hide-labels --line-thickness options (ultralytics#2658) * command line option for line thickness and hiding labels * command line option for line thickness and hiding labels * command line option for line thickness and hiding labels * command line option for line thickness and hiding labels * command line option for line thickness and hiding labels * command line option for hiding confidence values * Update detect.py Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Default optimize_for_mobile() on TorchScript models (ultralytics#2908) Per https://pytorch.org/tutorials/recipes/script_optimized.html this should improve performance on torchscript models (and maybe coreml models also since coremltools operates on a torchscript model input, though this still requires testing). * Update export.py (ultralytics#2909) * Update export.py for 2 dry runs (ultralytics#2910) * Update export.py for 2 dry runs * Update export.py * Add file_size() function (ultralytics#2911) * Add file_size() function * Update export.py * Update download() for tar.gz files (ultralytics#2919) * Update download() for tar.gz files * Update general.py * Update visdrone.yaml (ultralytics#2921) * Change default value of hide label argument to False (ultralytics#2923) * Change default value of hide-conf argument to false (ultralytics#2925) * test.py native --single-cls (ultralytics#2928) * Add verbose option to pytorch hub models (ultralytics#2926) * Add verbose and update print to logging * Fix positonal param * Revert auto formatting changes * Update hubconf.py Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * ACON Activation batch-size 1 bug patch (ultralytics#2901) * ACON Activation batch-size 1 bug path This is not a great solution to nmaac/acon#4 but it's all I could think of at the moment. WARNING: YOLOv5 models with MetaAconC() activations are incapable of running inference at batch-size 1 properly due to a known bug in nmaac/acon#4 with no known solution. * Update activations.py * Update activations.py * Update activations.py * Update activations.py * Check_requirements() enclosing apostrophe bug fix (ultralytics#2929) This fixes a bug where the '>' symbol in python package requirements was not running correctly with subprocess.check_output() commands. * Update README.md (ultralytics#2934) * Update README.md dependencies: ImportError: libGL.so.1: cannot open shared object file: No such file or directory ImportError: libgthread-2.0.so.0: cannot open shared object file: No such file or directory ImportError: libSM.so.6: cannot open shared object file: No such file or directory ImportError: libXrender.so.1: cannot open shared object file: No such file or directory * replace older apt-get with apt Code commented for now until a better understanding of the issue, and also code is not cross-platform compatible. Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Improved yolo.py profiling (ultralytics#2940) * Improved yolo.py profiling Improved column order and labelling. * Update yolo.py * Add yolov5/ to sys.path() for *.py subdir exec (ultralytics#2949) * Add yolov5/ to sys.path() for *.py subdir exec * Update export.py * update UI + latest yolov5 sources (#15) * merge latest version done, not tested * split tabs with radio buttons * models table -wip * models table -wip * start split html template to parts * ui refactoring * compile-template wip - paths confusion * compile wip * train/val splits * keep/ignore unlabeled images * models table * training hyperparameters * UI templates - done * unlabeled count in UI * add adam optimizer * convert_project to detection - works * start train/val splits * splits wip * splits done, only simple tests * splits validation * data preprocessing - not tested * download weights - wip * init_script_arguments - not tested * init_script_arguments - not tested * prepare weights - wip * not tested * add metrics period * set output * artifacts dirs * train_batches_uploaded flag * pre-release for debug * update config * update SDK version * fix imports * change imports * change imports * add UI sources directory to sys.path * new SDK version * new SDK version * fix GIoU smoothing * update smoothing * send metrics for the last epoch * save link to app UI * todo * log train/val size * sly-to-yolov5 format: fix same names in different datasets * fix inference * serve not tested * [serve] modal table stat * [serve] modal tabs * [serve] modal tabs * [serve] modal width * [serve] modal tabs style * [serve] fix pretrained weights URL * [serve] add stride to serv * [train] readme wip * [train] readme wip * [train] readme wip * [serve] change inference_image_id to work with remote storages (s3, azure, ...) * [serve] fix stride initialization * [serve] yolov5 serve - fixed * add additional info logs * [serve] todo * [train] splits - hide notice1 * fix collections readme * train readme - new screenshot * train readme Co-authored-by: Abhiram V <61599526+Anon-Artist@users.noreply.github.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: ramonhollands <ramonhollands@gmail.com> Co-authored-by: Ayush Chaurasia <ayush.chaurarsia@gmail.com> Co-authored-by: train255 <thanhdd.it@gmail.com> Co-authored-by: ab-101 <56578530+ab-101@users.noreply.github.com> Co-authored-by: Transigent <wbdsmith@optusnet.com.au> Co-authored-by: NanoCode012 <kevinvong@rocketmail.com> Co-authored-by: Daniel Khromov <danielkhromov@gmail.com> Co-authored-by: VdLMV <jaap@vdlmv.nl> Co-authored-by: Jaap van de Loosdrecht <jaap.van.de.loosdrecht@nhlstenden.com> Co-authored-by: Yann Defretin <kinoute@gmail.com> Co-authored-by: Aditya Lohia <64709773+aditya-dl@users.noreply.github.com> Co-authored-by: Shivam Swanrkar <ss8464@nyu.edu> Co-authored-by: xiaowo1996 <429740343@qq.com> Co-authored-by: Iden Craven <iden.craven@gmail.com> Co-authored-by: Jan Hajek <toretak@users.noreply.github.com> Co-authored-by: Jan Hajek <jan.hajek@gmail.com> Co-authored-by: oleg <oleh.boiko@gmail.com> Co-authored-by: Oleg Boiko <oboiko@chegg.com> Co-authored-by: Ryan Avery <ravery@ucsb.edu> Co-authored-by: Yonghye Kwon <developer.0hye@gmail.com> Co-authored-by: Kartikeya Sharma <karthiklfhs@gmail.com> Co-authored-by: Kartikeya Sharma <kartikes@trinity.vision.cs.cmu.edu> Co-authored-by: Kartikeya Sharma <kartikes@trinity-0-32.eth> Co-authored-by: Yann Defretin <yann@defret.in> Co-authored-by: maxupp <max.uppenkamp@rwth-aachen.de> Co-authored-by: Max Uppenkamp <max.uppenkamp@inform-software.com> Co-authored-by: zzttqu <80448114+zzttqu@users.noreply.github.com> Co-authored-by: Youngjin Shin <mail@jindev.me> Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com> Co-authored-by: Phat Tran <36766404+ptran1203@users.noreply.github.com> Co-authored-by: phattran <phat.tranhoang@cyberlogitec.com> Co-authored-by: Ding Yiwei <16083536+dingyiwei@users.noreply.github.com> Co-authored-by: DingYiwei <846414640@qq.com> Co-authored-by: Ben Milanko <bpmil3@student.monash.edu> Co-authored-by: Robin <robmarkcole@gmail.com> Co-authored-by: Tim Stokman <41363+timstokman@users.noreply.github.com> Co-authored-by: Tim <tim.stokman@hal24k.com> Co-authored-by: Burhan <burhr2@gmail.com> Co-authored-by: JoshSong <Joshua_Song@outlook.com> Co-authored-by: Michael Heilig <75843816+MichHeilig@users.noreply.github.com> Co-authored-by: r-blmnr <77175527+r-blmnr@users.noreply.github.com> Co-authored-by: fcakyon <34196005+fcakyon@users.noreply.github.com> Co-authored-by: Maximilian Peters <maximili.peters@mail.huji.ac.il> Co-authored-by: albinxavi <62288451+albinxavi@users.noreply.github.com> Co-authored-by: BZFYS <qq327568824@sina.com>
{kind=link}
{kind=link}
{kind=link}
* Be able to create dataset from annotated images only Add the ability to create a dataset/splits only with images that have an annotation file, i.e a .txt file, associated to it. As we talked about this, the absence of a txt file could mean two things: * either the image wasn't yet labelled by someone, * either there is no object to detect. When it's easy to create small datasets, when you have to create datasets with thousands of images (and more coming), it's hard to track where you at and you don't want to wait to have all of them annotated before starting to train. Which means some images would lack txt files and annotations, resulting in label inconsistency as you say in ultralytics#2313. By adding the annotated_only argument to the function, people could create, if they want to, datasets/splits only with images that were labelled, for sure. * Cleanup and update print() Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com>
* Be able to create dataset from annotated images only Add the ability to create a dataset/splits only with images that have an annotation file, i.e a .txt file, associated to it. As we talked about this, the absence of a txt file could mean two things: * either the image wasn't yet labelled by someone, * either there is no object to detect. When it's easy to create small datasets, when you have to create datasets with thousands of images (and more coming), it's hard to track where you at and you don't want to wait to have all of them annotated before starting to train. Which means some images would lack txt files and annotations, resulting in label inconsistency as you say in ultralytics#2313. By adding the annotated_only argument to the function, people could create, if they want to, datasets/splits only with images that were labelled, for sure. * Cleanup and update print() Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com>
Question
How to increase MAP?
Additional context
I trained the yolov5 for arounf 1500 epochs and it had a single class only, the images I downloaded were from google and the sizes were also kinda small majority of them < 640. I made a single class detection and the MAP I got after that was ~0.3. Any ideas how to increase this? I am relatively new to the yolo family.
Any help, any comment, any single idea would be of much much help.
THANKS!
These are the labels

These are the predictions

We can talk more here
https://www.linkedin.com/in/karan-tiwari-a86673200/The text was updated successfully, but these errors were encountered: