Small offset in detection and bad practice #6554
Comments
|
@Juanjojr9 👋 Hello! Thanks for asking about improving YOLOv5 🚀 training results. Most of the time good results can be obtained with no changes to the models or training settings, provided your dataset is sufficiently large and well labelled. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users first train with all default settings before considering any changes. This helps establish a performance baseline and spot areas for improvement. If you have questions about your training results we recommend you provide the maximum amount of information possible if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your We've put together a full guide for users looking to get the best results on their YOLOv5 trainings below. Dataset
Model SelectionLarger models like YOLOv5x and YOLOv5x6 will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For mobile deployments we recommend YOLOv5s/m, for cloud deployments we recommend YOLOv5l/x. See our README table for a full comparison of all models.
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
custom_pretrained.pt
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yamlTraining SettingsBefore modifying anything, first train with default settings to establish a performance baseline. A full list of train.py settings can be found in the train.py argparser.
Further ReadingIf you'd like to know more a good place to start is Karpathy's 'Recipe for Training Neural Networks', which has great ideas for training that apply broadly across all ML domains: http://karpathy.github.io/2019/04/25/recipe/ Good luck 🍀 and let us know if you have any other questions! |


|
@glenn-jocher Thank you very much for your answer. I will try to see how to improve it. Regarding the batch size question, why does it have to be as big as possible ? I have batch size to 1 and I don't know if it is the right thing to do. What should I do? |
|
@Juanjojr9 👋 Hello! Thanks for asking about CUDA memory issues. Batch size should be as large as possible for improved BatchNorm2d() statistics aggregation during training. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |


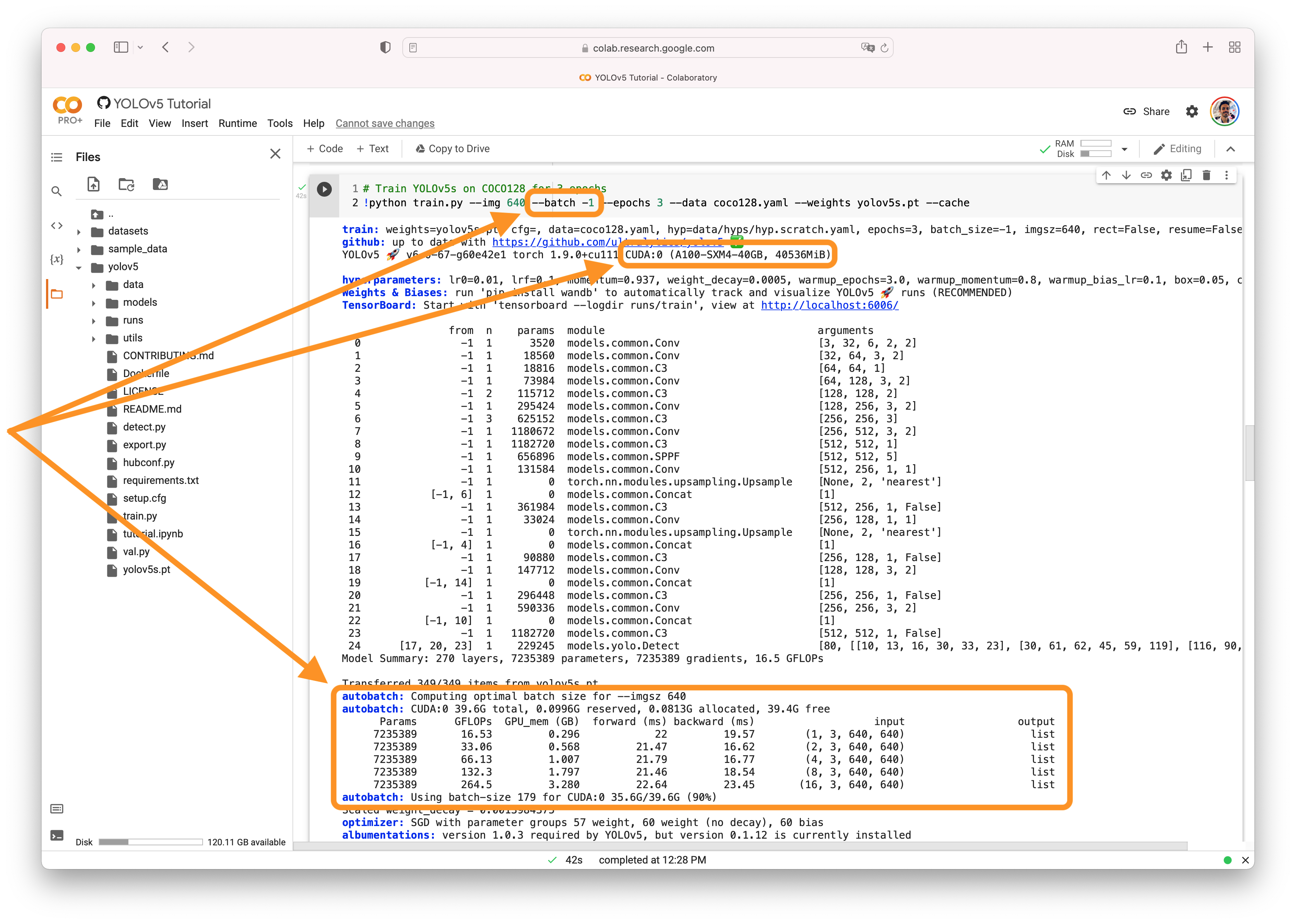
|
@glenn-jocher Thank you for your quick response.
As I ran out of CUDA memory I decided to lower the batch size. Would it be better to lower the image size and try to increase the batch size? Or use a smaller model? Or what would be the best practice? |

|
@Juanjojr9 up to you, see existing response #6554 (comment) |
|
@glenn-jocher I have seen it, but what I meant by my previous question was whether it is more convenient to reduce the batch size to the maximum, without touching the image size, or to reduce both a bit. |
|
@Juanjojr9 depends on use case, available resources, organization priorities etc. Use above guide and follow recommendations. |
|
@glenn-jocher OK, perfect. Thank you very much for all your help. It is very useful for me Regards |
Search before asking
Question
Hello
I have been training the Yolov5x6 model on my own dataset. I want to detect the pictures class, as COCO does not have this class.
Once the network is trained, I use detect.py. But I have a small problem, there is a small offset in the detection.
How could I solve it?
Another question I have.
As I had no CUDA memory, I reduced the batch size to 1. I know it's a bad practice, but I don't understand why. What is the reason for this?
What would be a best practice?
Thank you very much, I look forward to receiving your answers
Regards
JJ
Additional
No response
The text was updated successfully, but these errors were encountered: